在数据可视化的世界里,热力图一直是展现矩阵数据分布的强大工具。它能让枯燥的数值瞬间变得生动形象,帮助我们快速捕捉数据中的模式、异常和趋势。今天,我要分享一种别具一格的热力图绘制方式 ——方块大小与颜色双变量可视化,通过 python 代码实现一个既美观又信息丰富的可视化作品。如果你曾为如何让数据 “活起来” 而烦恼,这篇文章一定会给你带来新的灵感!
为什么选择这种热力图?
传统热力图通常只通过颜色深浅来表达数值大小,而我们今天要实现的版本增加了一个维度 ——方块面积。这种双变量可视化的优势在于:
- 颜色感知更直观:人类视觉对颜色的敏感度极高,不同色调能快速传递数值层级
- 面积大小强化差异:当数值差异较大时,面积变化比颜色变化更具冲击力
- 信息密度更高:在有限空间内展示更多维度的数据特征
这种可视化方式特别适合:
- 特征重要性分析(如机器学习模型的特征权重)
- 二维数据分布展示(如用户行为矩阵、市场份额分析)
- 数据对比场景(如不同条件下的指标对比)
代码实现:从 0 到 1 的可视化之旅
先来看完整代码,我们将逐步拆解每一个神奇的步骤:
import numpy as np
import matplotlib.pyplot as plt
# 随机生成一个 10x10 的矩阵,值域在 0 到 1 之间
np.random.seed(0)
data = np.random.rand(10, 10)
fig, ax = plt.subplots(figsize=(8, 6))
# 创建颜色映射(使用 colormap)
cmap = plt.cm.rdylgn
norm = plt.normalize(vmin=0, vmax=1)
# 绘制方块
for i in range(data.shape[0]):
for j in range(data.shape[1]):
value = data[i, j]
color = cmap(norm(value))
size = value * 900 # 控制面积大小(最大 900)
# 使用 scatter 绘制方块
ax.scatter(j + 1, 10 - i, s=size, c=[color], marker='s', edgecolor='black')
# 设置坐标轴
ax.set_xticks(np.arange(1, 11))
ax.set_yticks(np.arange(1, 11))
ax.set_xticklabels(np.arange(1, 11))
ax.set_yticklabels(np.arange(1, 11))
ax.set_xlabel("k (w)", fontsize=12)
ax.set_ylabel("samples", fontsize=12)
# 添加标题
ax.set_title("square heatmap plot", fontsize=14, fontweight='bold')
# 添加颜色条
sm = plt.cm.scalarmappable(cmap=cmap, norm=norm)
sm.set_array([])
cbar = plt.colorbar(sm, ax=ax)
cbar.set_label("")
# 添加网格线模拟边框
ax.set_xlim(0.5, 10.5)
ax.set_ylim(0.5, 10.5)
ax.set_xticks(np.arange(0.5, 11.5, 1), minor=true)
ax.set_yticks(np.arange(0.5, 11.5, 1), minor=true)
ax.grid(which='minor', color='black', linewidth=1)
ax.tick_params(which='minor', length=0)
plt.tight_layout()
plt.show()效果如下
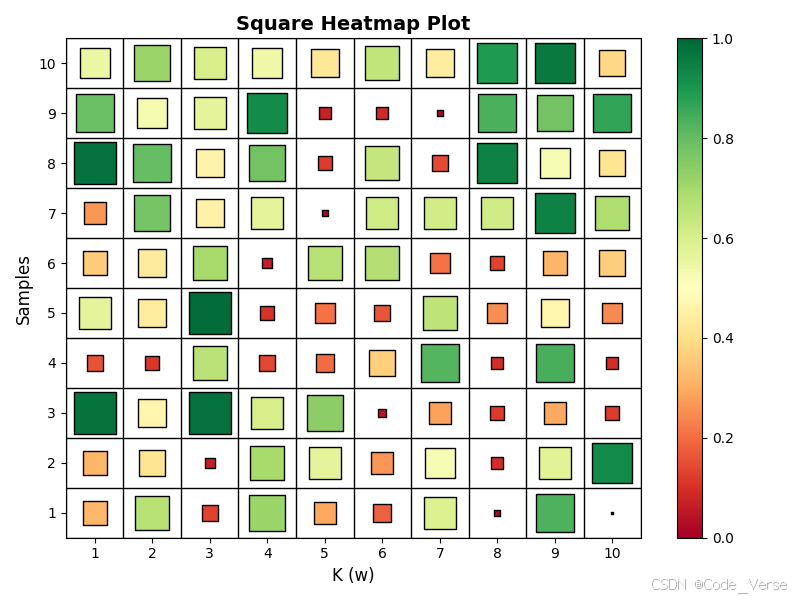
核心组件拆解:每一行代码都在做什么?
1. 数据准备:打造可视化的基石
np.random.seed(0) data = np.random.rand(10, 10)
np.random.seed(0) 是为了保证结果可复现,就像给随机数生成器设定一个 “起点”,这样别人运行代码时能得到和你一样的数据~
np.random.rand(10, 10) 生成一个 10x10 的随机矩阵,数值范围在 0 到 1 之间。这里就是替换自己数据的关键位置!你可以:
- 从文件读取数据:data = np.loadtxt('your_data.csv', delimiter=',')
- 加载已有的 numpy 数组:data = np.array(your_custom_data)
- 甚至手动定义矩阵:data = np.array([[0.1, 0.5], [0.8, 0.3]])
提示: 如果你的数据值域不在 0-1 之间,后续的颜色映射和大小计算需要相应调整哦~
2. 画布搭建:准备好展示数据的舞台
fig, ax = plt.subplots(figsize=(8, 6))
plt.subplots() 创建一个 figure 对象和一个 axes 对象,这是 matplotlib 绘图的标准流程~
figsize=(8, 6) 设置画布大小为 8 英寸宽、6 英寸高,你可以根据数据量调整这个参数,比如数据是 20x20 的,可以设为 (10,10) 让每个方块更清晰。
3. 颜色系统:让数据穿上绚丽的外衣
cmap = plt.cm.rdylgn norm = plt.normalize(vmin=0, vmax=1)
cmap = plt.cm.rdylgn 选择了一个从红色到黄色再到绿色的颜色映射,数值小的地方显示红色,数值大的地方显示绿色,中间过渡自然~
你可以换成其他颜色映射:
- plt.cm.viridis(蓝绿黄渐变,适合连续数据)
- plt.cm.coolwarm(蓝红渐变,适合正负值对比)
- plt.cm.blues(单色系蓝色,适合单一趋势数据)
norm = plt.normalize(vmin=0, vmax=1) 定义了数值到颜色的映射规则,将数据范围归一化到 0-1,这样颜色变化能准确反映数值差异。如果你的数据值域是 5-100,这里要改成vmin=5, vmax=100哦!
4. 方块绘制:数据可视化的核心逻辑
for i in range(data.shape[0]):
for j in range(data.shape[1]):
value = data[i, j]
color = cmap(norm(value))
size = value * 900 # 控制面积大小(最大 900)
ax.scatter(j + 1, 10 - i, s=size, c=[color], marker='s', edgecolor='black')
这部分是代码的灵魂!我们通过双重循环遍历矩阵的每个元素:
value = data[i, j] 取出当前位置的数值
color = cmap(norm(value)) 将数值转换为对应的颜色,这里用到了前面定义的颜色映射和归一化规则
size = value * 900 计算方块面积,数值越大方块越大。这里的 900 是一个缩放因子,你可以调整它来控制方块的大小范围,比如改成 500 让方块更小,或者 1500 让差异更明显~
ax.scatter(...) 是绘制方块的关键函数:
- j + 1, 10 - i 是方块的坐标,注意这里10 - i是为了让 y 轴从上到下递增,符合矩阵的行列索引习惯
- s=size 控制面积大小
- c=[color] 设置颜色,注意用列表包裹颜色值
- marker='s' 将散点形状设为正方形(square),也可以换成'o'圆形、'^'三角形等
- edgecolor='black' 添加黑色边框,让每个方块更清晰可辨
5. 细节优化:让图表更专业美观
# 设置坐标轴
ax.set_xticks(np.arange(1, 11))
ax.set_yticks(np.arange(1, 11))
ax.set_xticklabels(np.arange(1, 11))
ax.set_yticklabels(np.arange(1, 11))
ax.set_xlabel("k (w)", fontsize=12)
ax.set_ylabel("samples", fontsize=12)
# 添加标题
ax.set_title("square heatmap plot", fontsize=14, fontweight='bold')
# 添加颜色条
sm = plt.cm.scalarmappable(cmap=cmap, norm=norm)
sm.set_array([])
cbar = plt.colorbar(sm, ax=ax)
cbar.set_label("")
# 添加网格线模拟边框
ax.set_xlim(0.5, 10.5)
ax.set_ylim(0.5, 10.5)
ax.set_xticks(np.arange(0.5, 11.5, 1), minor=true)
ax.set_yticks(np.arange(0.5, 11.5, 1), minor=true)
ax.grid(which='minor', color='black', linewidth=1)
ax.tick_params(which='minor', length=0)
这部分是让图表从 “能用” 到 “精美” 的关键:
- 坐标轴设置:明确 x 轴和 y 轴的刻度位置和标签,ax.set_xlabel和ax.set_ylabel可以换成你自己的变量名称,比如 “时间(小时)”“用户活跃度” 等。
- 标题添加:ax.set_title让图表有一个清晰的主题,fontweight='bold'让标题更醒目。
- 颜色条:这是热力图的 “翻译器”,告诉读者颜色对应的数值范围。sm.set_array([])是一个小技巧,用于初始化颜色映射对象。
- 网格线与边框:这里用了一个巧妙的方法 —— 通过设置次要刻度(minor ticks)并绘制网格线,模拟出每个方块的边框。ax.set_xlim(0.5, 10.5)将坐标轴范围扩展到 0.5-10.5,这样 10x10 的矩阵刚好占据整个区域,网格线就像一个个小格子~
自定义你的可视化:从模仿到创新
1. 替换成你自己的数据
正如前面提到的,数据生成部分是最容易替换的地方。假设你有一个从 excel 中导出的 15x15 的用户行为数据矩阵,路径为user_behavior.csv,你可以这样做:
# 从csv文件读取数据
data = np.loadtxt('user_behavior.csv', delimiter=',')
# 或者使用pandas读取(更灵活)
import pandas as pd
data = pd.read_csv('user_behavior.csv').values
如果你的数据值域不是 0-1,比如是 10-100,需要调整颜色映射和大小计算:
# 假设数据值域是10-100 vmin, vmax = 10, 100 norm = plt.normalize(vmin=vmin, vmax=vmax) size = (value - vmin) / (vmax - vmin) * 900 # 归一化后计算大小
2. 调整颜色映射和视觉效果
如果你不喜欢 rdylgn 颜色映射,可以尝试其他方案:
# 冷色调到暖色调(适合显示数值递增趋势) cmap = plt.cm.blues # 红黄色调(适合突出高数值区域) cmap = plt.cm.orrd # 彩虹色调(适合展示复杂模式) cmap = plt.cm.rainbow
3. 优化大数据量场景
如果你的数据是 100x100 的大矩阵,直接绘制可能会显得拥挤,这时可以:
- 调整画布大小:fig, ax = plt.subplots(figsize=(12, 12))
- 减小边框和网格线宽度:ax.grid(which='minor', color='black', linewidth=0.5)
- 取消边框:ax.spines['top'].set_visible(false) ax.spines['right'].set_visible(false) ax.spines['left'].set_visible(false)
4. 添加交互功能(进阶)
如果想让图表更动态,可以使用matplotlib的交互功能或结合ipywidgets:
from matplotlib.widgets import slider
# 创建滑块来调整大小缩放因子
ax_slider = plt.axes([0.25, 0.02, 0.65, 0.03])
slider = slider(ax_slider, 'size scale', 100, 2000, valinit=900)
def update(val):
scale = slider.val
for i in range(data.shape[0]):
for j in range(data.shape[1]):
value = data[i, j]
size = value * scale
# 这里需要先清除之前的散点,再重新绘制
# 由于scatter返回的是pathcollection对象,可以保存后更新
fig.canvas.draw_idle()
slider.on_changed(update)
应用场景:让可视化解决实际问题
这种双变量热力图在实际场景中能做什么?举几个栗子:
1. 机器学习特征重要性可视化
假设你训练了一个随机森林模型,想展示各特征的重要性:
# 假设feature_importances是形状为(20,)的数组 data = feature_importances.reshape(4, 5) # 调整为4x5的矩阵便于可视化
2. 市场份额分析
展示不同地区、不同产品的市场占有率:
# 行:地区(华北、华东、华南、西北、西南)
# 列:产品(a、b、c、d)
data = np.array([
[0.35, 0.25, 0.15, 0.25],
[0.28, 0.32, 0.18, 0.22],
[0.40, 0.20, 0.15, 0.25],
[0.22, 0.30, 0.25, 0.23],
[0.25, 0.25, 0.30, 0.20]
])
3. 图像像素强度可视化
将灰度图像转换为热力图展示:
from skimage import data import matplotlib.pyplot as plt # 加载示例图像 image = data.camera() # 归一化到0-1 data = image / 255.0
注意事项:避坑指南
方块重叠问题:当数值差异很大时,大的方块可能会覆盖小的方块。可以通过调整size的缩放因子或添加透明度来解决:
ax.scatter(..., alpha=0.8) # 添加透明度
坐标轴标签旋转:当 x 轴标签较多时,可能会重叠,可以旋转标签:
ax.set_xticklabels(np.arange(1, 11), rotation=45, ha='right')
性能问题:处理超大矩阵(如 1000x1000)时,双重循环会很慢。可以改用pcolormesh结合patchcollection优化,但需要重写绘制逻辑~
颜色对比度:选择颜色映射时要考虑色盲友好性,plt.cm.viridis是一个不错的选择,或者使用seaborn的调色板:
import seaborn as sns
cmap = sns.color_palette("coolwarm", as_cmap=true)
结语:让数据开口说话
可视化的魅力在于将抽象的数字转化为直观的视觉信号,帮助我们理解数据背后的故事。今天分享的方块热力图通过颜色和大小双重维度,让数据呈现更加立体生动。无论是科研数据展示、商业数据分析还是日常数据探索,这种可视化方式都能为你增添一份力量~
现在,快试试用你自己的数据绘制吧!只需要替换data变量的定义部分,调整颜色映射和大小参数,就能得到属于你的专属可视化作品~
以上就是使用python绘制动态方块热力图的详细内容,更多关于python绘制热力图的资料请关注代码网其它相关文章!




发表评论