windows下c++使用sqlite
1、安装
进入sqlite download page页面,下载sqlite-dll-win-x86-*.zip、sqlite-amalgamation-*.zip、sqlite-tools-win-x64-*.zip三个包,这三个包里分别包含dll文件和def文件、头文件、exe工具。
使用vs命令行工具生成.lib文件:进入dll和def文件所在的目录,执行lib /def:sqlite3.def /out:sqlite3.lib /machine:x86后获得.lib文件,这样就可以通过dll文件、lib文件、头文件来开发sqlite了。
exe工具可以进行sqlite操作,比如下面为创建数据库和表(输入.quit结束命令,sql语句以分号结尾):
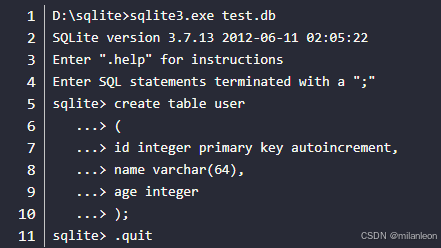
2、代码示例
#include <iostream>
#include "sqlite3.h"
//sql语句查询结果回调,比如对于select来说,查询到的每一条数据都会执行callback方法一次
static int callback(void* data/*sqlite3_exec()的第四个参数*/, int argc/*结果的列个数*/,
char** argv/*结果字段值*/, char** azcolname/*结果列名*/) {
for (int i = 0; i < argc; i++) {
printf("%s = %s\n", azcolname[i], argv[i] ? argv[i] : "null");
}
printf("\n");
return 0;
}
int main()
{
sqlite3* pdb = nullptr;
char* zerrmsg = nullptr;
const char* sql = nullptr;
const char* data = "callback function called";
//打开数据库,不存在则创建
int nres = sqlite3_open("d:\\sqlite\\test.db", &pdb);
if (nres) {
fprintf(stderr, "can't open database: %s\n", sqlite3_errmsg(pdb));
exit(0);
}
//创建表,已存在则创建失败
sql = "create table company("\
"id integer primary key autoincrement,"\
"name text not null,"\
"age integer not null);";
nres = sqlite3_exec(pdb, sql, 0, 0, &zerrmsg);
if (nres != sqlite_ok) {
fprintf(stderr, "sql error: %s\n", zerrmsg);
sqlite3_free(zerrmsg);
}
//插入数据
sql = "insert into company (id,name,age) values(1, 'paul', 32); " \
"insert into company (id,name,age) values (2, 'allen', 25); " \
"insert into company (id,name,age) values (3, 'teddy', 23);";
nres = sqlite3_exec(pdb, sql, 0, 0, &zerrmsg);
if (nres != sqlite_ok) {
fprintf(stderr, "sql error: %s\n", zerrmsg);
sqlite3_free(zerrmsg);
}
//查询数据
sql = "select * from company";
nres = sqlite3_exec(pdb, sql, callback, (void*)data, &zerrmsg);
if (nres != sqlite_ok) {
fprintf(stderr, "sql error: %s\n", zerrmsg);
sqlite3_free(zerrmsg);
}
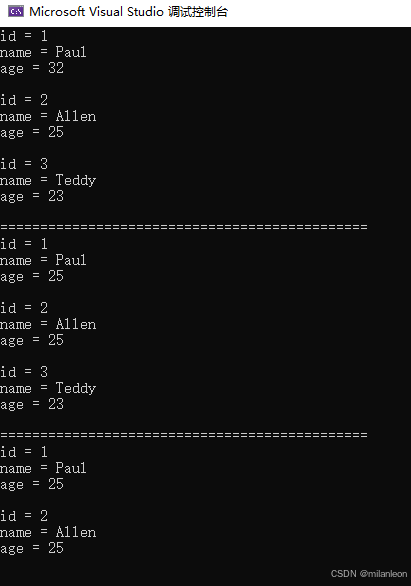
printf("==============================================\r\n");
//修改数据
sql = "update company set age = 25 where id=1; select * from company";
nres = sqlite3_exec(pdb, sql, callback, (void*)data, &zerrmsg);
if (nres != sqlite_ok) {
fprintf(stderr, "sql error: %s\n", zerrmsg);
sqlite3_free(zerrmsg);
}
printf("==============================================\r\n");
//删除数据
sql = "delete from company where id=3; select * from company";
nres = sqlite3_exec(pdb, sql, callback, (void*)data, &zerrmsg);
if (nres != sqlite_ok) {
fprintf(stderr, "sql error: %s\n", zerrmsg);
sqlite3_free(zerrmsg);
}
sqlite3_close(pdb);
}
补充:cppsqlite:c++轻松操作sqlite3数据库
cppsqlite:c++轻松操作sqlite3数据库
简介:cppsqlite是一个c++库,提供了一个简化的接口来操作sqlite3数据库。
sqlite3是一个轻量级、开源、自包含且无服务器的事务性sql数据库引擎。cppsqlite通过提供直观的api和封装,让开发者更容易执行sql查询、管理数据库事务和处理结果集,同时支持异常处理和内存管理。该库支持跨平台使用,高效且功能丰富,适合嵌入式和移动应用开发。
1. cppsqlite库介绍
cppsqlite是一个用c++封装sqlite数据库的库,它将sqlite的功能通过c++的面向对象特性提供给开发者,让数据库操作更加直观和简便。这个库专注于提供一个轻量级、易于集成的解决方案,以便在c++项目中能够快速地实现本地数据存储和管理。
在本章中,我们将首先探讨cppsqlite的基本特性和优势,然后逐步介绍如何在实际项目中集成和使用cppsqlite。我们会了解它的安装和配置步骤,以及如何进行初步的数据操作。本章节旨在为读者提供一个快速的入门指南,使他们能够轻松地掌握cppsqlite的基本使用方法。
2. sqlite3数据库特性
2.1 数据库架构和存储机制
2.1.1 页面存储和事务日志
sqlite是一个轻量级的数据库管理系统,其核心特性之一是页面存储机制。所有数据库内容,包括表、索引、触发器等,都是存储在一个或多个磁盘文件中的。这些文件被称为数据库文件,它们是普通的文件系统文件,因此可以被任何文件i/o api访问。
数据库文件被分割成固定大小的页或块(通常为1024字节),这种设计允许sqlite高效地读写磁盘,提高了i/o性能。数据库文件的开始是一个特殊的页,称为页0,包含了数据库的头部信息,包括数据库格式版本号、根页号等。紧跟其后的是实际的数据库内容页,这些页可能包含b-树节点、自由页列表或溢出页。
事务日志(wal,write-ahead logging)是sqlite用于实现事务安全的机制之一。传统的数据库通常使用回滚日志,而sqlite通过wal提供一种不同的方法来保证事务的原子性、一致性、隔离性和持久性(acid属性)。wal机制通过将对数据库的更改写入到一个单独的日志文件中来实现,然后在适当的时候将这些更改应用到数据库文件中。这种方式可以提高并发访问的性能,并且有助于简化数据库的备份和恢复过程。
wal模式下,数据库文件本身保持不变,直到事务被提交,这减少了写放大(write amplification)效应,并且允许读取操作和写入操作并发执行,从而提升性能。但是,wal也有其自身的挑战,例如日志文件的管理,以及可能由于日志文件过大而导致的性能问题。
2.1.2 数据库文件格式和版本
sqlite数据库文件遵循特定的文件格式,这种格式是经过精心设计的,以便在不同的系统和平台上保持一致性和兼容性。sqlite的文件格式是在版本之间向前兼容的,意味着较新版本的sqlite可以读取较旧版本的数据库文件,但是旧版本的sqlite可能无法理解新版本中引入的新特性。
每个数据库文件的开头都有一个头部页面,该页面包含了数据库的元数据和文件格式信息。如果文件格式有所改变,那么头部页面会更新以反映新的格式。sqlite数据库文件的头部信息中通常包含如下字段:
- 文件格式标识符:用于识别文件是否为sqlite数据库。
- 格式版本号:指示文件创建时所使用的sqlite版本。
- 页大小:数据库中使用的页的大小,以字节为单位。
- 可用的b树页面数量:数据库中可用的b树页面总数。
- 分配位图页码:位图页用于跟踪哪些页被分配了。
- 根页码:b-树的根节点所在的页码。
- 数据库创建日期和版本:创建数据库的日期以及数据库的版本号。
了解数据库文件格式对于开发者而言至关重要,特别是在进行故障恢复或需要对数据库文件进行低级操作时。版本信息允许开发者判断一个数据库文件是否可以被他们所使用的sqlite版本处理,或者是否需要升级。
2.2 数据库性能和优化
2.2.1 索引的使用和优化
索引在sqlite数据库中扮演了至关重要的角色,它能够显著提升查询效率,尤其是对于大型数据库。索引是数据库表中数据的一种辅助结构,允许sqlite快速定位到表中特定数据的位置,从而减少了数据检索时间。
索引的工作原理依赖于b-树结构,这种结构特别适合磁盘存储,因为它可以保持数据的排序状态,并且可以实现高效的查询和插入操作。当你在表上创建索引时,sqlite会为索引字段创建一个b-树,每个节点包含索引字段的值和指向对应行的指针。
使用索引时需要注意以下几点:
- 索引选择 :并非所有的列都适合创建索引。通常,只对经常用于查询条件的列或作为join操作依据的列创建索引。
- 索引维护成本 :每次数据变更(insert、update、delete)时,相应的索引也需要更新,这会带来额外的性能开销。
- 索引碎片 :当索引数据被频繁修改时,可能会导致索引页之间的存储变得分散,降低查询效率。定期重建索引可以帮助解决这一问题。
- 覆盖索引 :如果查询只需要索引中的数据,而不需要表中的其他列数据,那么索引可以完全覆盖查询,这称为覆盖索引。
优化索引的策略包括:
- 使用
explain query plan命令来查看查询计划,评估索引是否正在被有效使用。 - 定期运行
analyze命令来更新表的统计信息,这有助于优化器做出更好的决策。 - 适时删除不再需要或性能低效的索引。
2.2.2 查询计划和执行分析
查询计划是sqlite执行sql查询的步骤说明。通过分析查询计划,开发者可以理解sqlite是如何解析、优化和执行sql语句的。 explain query plan 命令可以提供这一信息,但不执行实际查询。
例如,一个简单的查询可能会显示以下类型的步骤:
- 扫描表:遍历表中的每一行。
- 使用索引:利用索引快速定位到表中行。
- 排序:对结果集进行排序操作。
- 分组和聚合:对数据进行聚合操作,如count、sum等。
explain query plan select * from my_table where condition;
查询计划的输出会以表格形式展示,每一行代表查询中的一个步骤,其中可能包含如下列:
- id: 与查询中每一部分相关的唯一标识符。
- parent: 当前步骤的父步骤的id。
- detail: 对当前步骤操作的详细描述。
- order: 如果有多个步骤,这个数字表示步骤的执行顺序。
通过了解查询计划,开发者可以识别哪些操作是低效的,例如全表扫描或索引未被有效利用。一旦识别了低效操作,开发者可以通过添加或修改索引来优化查询。
执行分析通常需要结合具体的查询语句和数据库使用案例来进行。开发者可以使用 explain query plan 命令获取信息,然后根据反馈调整数据库设计或查询语句。必要时,开发者可能需要调整表结构或索引策略,或者重构查询来提高效率。
3. cppsqlite核心功能
3.1 封装库与sqlite3接口
3.1.1 接口封装的优势与限制
cppsqlite作为一个封装库,其优势在于为开发人员提供了一个更为简单、直接的api来操作sqlite数据库,而不是直接与底层的sqlite3 c api打交道。这使得c++程序能够以面向对象的方式与sqlite交互,同时保持了sqlite数据库的高效性和跨平台特性。封装库还能够处理一些底层细节,比如资源管理、错误处理等,从而降低出错的几率和提高开发效率。
然而,封装同时也会带来一定的限制。首先,封装层可能会增加额外的性能开销,尤其是在性能敏感的应用中。封装库需要转换数据类型、处理异常等,这些操作都可能消耗额外的时间和资源。其次,封装库可能会限制对sqlite内部功能的直接访问。如果封装库没有提供某个特定功能的接口,那么开发者可能需要直接调用底层的sqlite c api来实现。
3.1.2 cppsqlite对sqlite3功能的扩展
cppsqlite在封装sqlite3功能的同时,也添加了一些扩展来更好地适应c++的特性。例如,cppsqlite提供了异常安全性的支持,开发者可以利用c++的异常处理机制来处理数据库操作中可能出现的错误。此外,cppsqlite对一些复杂的数据库操作提供了更高级的接口,使得这些操作的实现更为便捷和直观。
cppsqlite还允许开发人员扩展sql函数和聚合函数,使得自定义的sql函数可以与c++代码无缝结合,提供了更丰富的数据操作能力。这些扩展功能使得cppsqlite在保持了sqlite3强大功能的基础上,进一步增强了其在c++环境中的适用性和易用性。
3.2 核心类和方法介绍
3.2.1 数据库连接和执行sql
cppsqlite中的核心类之一是 sqlite::connection ,它负责建立与sqlite数据库的连接。通过这个类的对象,开发者可以打开数据库文件、执行sql语句以及进行事务管理等操作。
下面是一个使用 sqlite::connection 类执行sql语句的基本示例:
#include <sqlitepp.h>
int main() {
try {
sqlite::connection conn("example.db"); // 打开数据库文件,如果不存在则创建
conn.executenonquery("create table if not exists users (id integer primary key, name text, age integer)");
conn.executenonquery("insert into users (name, age) values ('john doe', 30)");
// 更多操作...
} catch (const sqlite::exception& e) {
std::cerr << "数据库操作异常: " << e.what() << std::endl;
}
return 0;
}在这段代码中,我们首先包含了必要的头文件 sqlitepp.h ,然后使用 sqlite::connection 类打开了名为 example.db 的数据库文件。如果文件不存在,则会创建一个新的数据库文件。接下来,我们使用 executenonquery 方法执行了两个sql语句:创建一个名为 users 的表(如果该表不存在的话),并向其中插入了一条记录。
异常处理机制是 sqlite::connection 类中的一个重要特性。如果在执行sql语句时发生任何异常,比如语法错误、数据类型不匹配等, sqlite::connection 会抛出 sqlite::exception 异常,开发者可以捕获这个异常并进行相应的处理。
3.2.2 事务的自动管理
事务是数据库管理系统的一个重要特性,它确保了一系列的操作要么全部成功,要么全部失败,从而保持数据的一致性和完整性。cppsqlite通过 sqlite::transaction 类自动管理事务,提供了更加便捷和安全的事务处理方式。
下面是一个使用 sqlite::transaction 类处理事务的示例代码:
#include <sqlitepp.h>
int main() {
try {
sqlite::connection conn("example.db");
{
sqlite::transaction t(&conn); // 创建事务对象,开启事务
conn.executenonquery("insert into users (name, age) values ('jane doe', 25)");
conn.executenonquery("update users set age = age + 1 where id = 1");
t.commit(); // 提交事务
}
// 如果发生异常,事务会自动回滚
} catch (const sqlite::exception& e) {
std::cerr << "数据库操作异常: " << e.what() << std::endl;
}
return 0;
}在这段代码中,我们通过创建 sqlite::transaction 类的对象 t 来管理事务。这个对象在构造时会自动开始一个新事务,并在对象被销毁时(即代码块结束时)尝试提交事务。如果在事务处理过程中发生异常,事务将自动回滚到事务开始前的状态,保证了数据不会因为操作失败而被破坏。
cppsqlite的事务管理不仅支持自动回滚,还支持显式地提交或回滚事务。通过调用 sqlite::transaction 对象的 commit() 方法可以显式提交事务,而调用 rollback() 方法可以显式回滚事务。这种灵活的事务管理方式使得开发者可以更精确地控制数据库操作的执行流程。
通过本章节的介绍,我们深入了解了cppsqlite的核心功能,包括其接口封装的优势与限制,以及核心类和方法的具体使用。在下一章节中,我们将进一步探讨cppsqlite的使用步骤,涵盖环境搭建、配置以及简单的操作实例。
4. cppsqlite使用步骤
4.1 环境搭建与配置
4.1.1 开发环境的搭建
要开始使用cppsqlite,首先需要搭建一个适合的开发环境。cppsqlite是一个c++库,它提供了对sqlite3数据库的访问接口,因此你的开发环境需要能够编译c++代码。对于大多数系统来说,这意味着安装一个c++编译器,如gcc或clang,在windows上通常会使用microsoft visual studio。
对于跨平台开发,推荐使用cmake作为项目管理工具。cmake可以通过配置文件(cmakelists.txt)简化构建过程,并且可以生成针对不同操作系统的构建系统。
安装好必要的工具后,你还需要确保系统上安装了sqlite3库。在linux上这通常意味着安装开发包版本的sqlite,例如在debian系列的系统中,你可以使用以下命令:
sudo apt-get install libsqlite3-dev
在windows上,你可以从sqlite官方网站下载预编译的二进制文件或者源代码。
4.1.2 依赖项和编译选项
cppsqlite依赖于sqlite3库,因此在编译时,需要包含sqlite3的头文件并链接到sqlite3库。如果你是使用cmake来管理你的项目,你可以在cmakelists.txt中添加以下内容来找到sqlite3并链接库:
find_package(sqlite3 required)
include_directories(${sqlite3_include_dirs})
target_link_libraries(<你的项目名称> ${sqlite3_libraries})如果你没有使用cmake,确保在编译器的包含目录中添加sqlite3的头文件路径,以及在链接器的库目录中添加sqlite3的库文件路径。对于gcc或clang,这通常可以通过添加-i和-l标志来实现。
编译时,你也需要确保包含了cppsqlite库。如果你已经下载并解压了cppsqlite,确保它的头文件路径和库文件路径被正确地添加到了你的编译命令中。
4.2 简单操作实例
4.2.1 创建和连接数据库
创建数据库的第一步是包含cppsqlite库,并且创建一个数据库对象。以下是一个简单的示例代码,展示了如何创建一个新的sqlite数据库:
#include "sqlite3.h"
#include <iostream>
int main() {
sqlite3* db;
int rc = sqlite3_open("example.db", &db);
if (rc != sqlite_ok) {
std::cerr << "error opening database: " << sqlite3_errmsg(db) << std::endl;
return 1;
} else {
std::cout << "opened database successfully." << std::endl;
}
// 记得在完成数据库操作后关闭数据库
sqlite3_close(db);
return 0;
}在这段代码中,我们首先包含了sqlite3.h头文件,这是使用cppsqlite的入口点。然后,我们使用 sqlite3_open 函数尝试打开(或创建)一个名为 example.db 的数据库文件。如果文件成功打开, sqlite3_open 会返回 sqlite_ok ,并且数据库对象 db 会被填充。如果发生错误,我们将通过 sqlite3_errmsg 函数获取并输出错误信息。最后,我们使用 sqlite3_close 函数关闭数据库连接。
4.2.2 执行基本的crud操作
一旦我们成功连接到数据库,接下来就可以执行基本的crud(创建、读取、更新、删除)操作了。以下是如何执行这些操作的一个简单例子:
#include "sqlite3.h"
#include <iostream>
int main() {
sqlite3* db;
int rc = sqlite3_open("example.db", &db);
if (rc != sqlite_ok) {
std::cerr << "error opening database: " << sqlite3_errmsg(db) << std::endl;
return 1;
}
// 创建表
const char* create_table_sql = "create table if not exists test_table ("
"id integer primary key autoincrement, "
"data text not null);";
char* err_msg = nullptr;
rc = sqlite3_exec(db, create_table_sql, nullptr, nullptr, &err_msg);
if (rc != sqlite_ok) {
std::cerr << "sql error: " << err_msg << std::endl;
sqlite3_free(err_msg);
}
// 插入数据
const char* insert_sql = "insert into test_table (data) values ('sample data');";
rc = sqlite3_exec(db, insert_sql, nullptr, nullptr, &err_msg);
if (rc != sqlite_ok) {
std::cerr << "sql error: " << err_msg << std::endl;
sqlite3_free(err_msg);
}
// 查询数据
const char* select_sql = "select * from test_table;";
rc = sqlite3_exec(db, select_sql, [](void* data, int argc, char** argv, char** azcolname) -> int {
for (int i = 0; i < argc; i++) {
std::cout << azcolname[i] << " = " << (argv[i] ? argv[i] : "null") << std::endl;
}
std::cout << std::endl;
return 0;
}, nullptr, &err_msg);
if (rc != sqlite_ok) {
std::cerr << "sql error: " << err_msg << std::endl;
sqlite3_free(err_msg);
}
// 更新数据
const char* update_sql = "update test_table set data = 'updated data' where id = 1;";
rc = sqlite3_exec(db, update_sql, nullptr, nullptr, &err_msg);
if (rc != sqlite_ok) {
std::cerr << "sql error: " << err_msg << std::endl;
sqlite3_free(err_msg);
}
// 删除数据
const char* delete_sql = "delete from test_table where id = 1;";
rc = sqlite3_exec(db, delete_sql, nullptr, nullptr, &err_msg);
if (rc != sqlite_ok) {
std::cerr << "sql error: " << err_msg << std::endl;
sqlite3_free(err_msg);
}
// 关闭数据库连接
sqlite3_close(db);
return 0;
}在上面的代码中,我们首先创建了一个名为 test_table 的表,这个表有两个字段: id 作为主键, data 作为存储文本数据的字段。然后我们插入了一条包含文本数据的记录,查询该表中的所有数据,并且将第一条记录的数据更新为"updated data"。最后,我们删除了这条记录。
以上代码通过 sqlite3_exec 函数执行sql命令。 sqlite3_exec 的第三个参数为回调函数,它在查询操作完成后被调用,用于处理查询结果。这里使用了一个lambda表达式作为回调函数来输出每一行查询结果的内容。
请注意,在实际的生产代码中,你需要更加谨慎地处理可能出现的错误,并且考虑使用语句( sqlite3_stmt )对象来执行sql命令,这提供了更多的灵活性和安全性,特别是在处理包含变量的sql语句时。
5. 跨平台支持与性能优化
5.1 跨平台编译和运行
5.1.1 不同操作系统下的兼容性
cppsqlite作为一款轻量级的sqlite封装库,其设计目标之一便是跨平台兼容性。这允许开发者在不同的操作系统上编译和运行相同的代码库,而无需修改代码。在windows、linux和macos等主流操作系统上,cppsqlite都能实现稳定运行。然而,不同的操作系统可能在文件路径表示、系统调用等底层机制上有所差异,这就要求开发者在编译时对这些差异进行适配。
为了确保跨平台编译的成功,需要确保几个关键点:
- 编译器兼容性 :确定使用的是一个跨平台编译器,比如gcc、clang或msvc,并且是在其支持的平台上编译。
- 依赖库 :确保所有第三方依赖库,如sqlite本身,都已经支持目标操作系统。
- 构建系统 :使用如cmake或meson这类跨平台构建系统,它们能够为多种操作系统生成正确的构建脚本。
5.1.2 版本差异和特定平台的注意事项
即使cppsqlite致力于跨平台兼容,但在不同操作系统或编译器的版本间还是可能遇到差异。因此,开发者在部署前需要做细致的测试。另外,特定平台可能会有特定的性能特性或限制,例如:
- windows上的unicode支持 :在windows平台上,使用宽字符版本的api和库可能会更合适。
- macos上的系统集成 :由于macos的高度集成特性,可能需要额外处理代码签名和沙盒权限问题。
- linux上的动态库版本控制 :确保正确处理.so文件的版本依赖关系,避免运行时错误。
5.2 性能优化和内存管理
5.2.1 优化查询和索引策略
在数据库操作中,性能优化至关重要,尤其是查询优化和索引策略。一个良好的查询计划能够显著减少数据库的i/o操作和提高响应速度。
- 查询优化 :可以使用explain query plan命令来分析查询计划,了解数据库如何执行特定查询,并据此调整sql语句。
- 索引策略 :合理创建索引可以极大提升查询效率,但索引过多也会造成写入操作的性能下降。需要根据查询模式和数据访问频率,平衡索引的创建和维护。
5.2.2 内存泄漏检测和管理
cppsqlite作为sqlite的封装库,同样继承了sqlite高效的内存管理机制。然而,在复杂的应用场景下,内存泄漏仍然是需要注意的问题。
- 内存泄漏检测工具 :使用valgrind这类内存检查工具来检测程序中的内存泄漏问题。
- 资源管理 :利用c++的raii(resource acquisition is initialization)特性,通过智能指针管理资源,确保在对象生命周期结束时,相关资源被正确释放。
// 示例代码展示使用智能指针管理cppsqlite数据库连接对象
#include <cppsqlite3/database.hpp>
void usedatabase() {
// 使用std::unique_ptr智能指针管理数据库连接
std::unique_ptr<cppsqlite3::database> db(new cppsqlite3::database("example.db"));
// 执行sql操作...
// 当unique_ptr离开作用域时,自动释放数据库连接
}在上述示例代码中, std::unique_ptr 智能指针负责管理数据库连接对象。当 unique_ptr 离开其作用域时,会自动调用析构函数释放数据库连接。这种方法可以有效避免内存泄漏。
代码逻辑分析:
#include <cppsqlite3/database.hpp>:包含cppsqlite3库的database类头文件。std::unique_ptr<cppsqlite3::database> db(new cppsqlite3::database("example.db"));:创建一个unique_ptr智能指针,并用它来管理一个新的database对象。new关键字分配了数据库对象的内存,并且unique_ptr负责在不再需要时自动释放这部分内存。db->execute("..."):调用数据库对象的execute方法来执行sql操作。 当usedatabase函数执行完毕,db作为局部变量,会超出其作用域,从而触发unique_ptr的析构函数,自动释放数据库连接对象所占用的内存资源。
这种方式确保了即使在发生异常时,数据库连接也能被安全地关闭和资源释放。
6. 异常处理与数据库事务
6.1 异常处理机制
在任何的软件开发过程中,错误处理是不可或缺的一部分,尤其是数据库编程中。cppsqlite作为sqlite的一个封装库,它在异常处理机制方面继承了sqlite的优点并结合c++的异常处理特性,提供了一套完整的异常处理机制。
6.1.1 cppsqlite异常类型和处理方法
cppsqlite定义了多种异常类型,以区分不同类型的错误。例如,数据库操作错误、连接失败、事务问题等都有对应的异常类型。处理这些异常的常见做法是在代码中使用try-catch块捕获并处理它们。
#include <cppsqlite3/database.hpp>
#include <iostream>
using namespace cppsqlite3;
int main() {
database db;
try {
db.open("example.db");
db.exec("create table if not exists test(id integer primary key, name text)");
// 更多数据库操作...
} catch (const exception &e) {
std::cerr << "sqlite error: " << e.geterrorcode() << " message: " << e.what() << std::endl;
// 异常处理逻辑
}
return 0;
}在上面的代码示例中,我们尝试打开一个数据库并创建一个表。如果操作失败,将抛出异常,我们可以捕获并打印出错误信息。
6.1.2 异常安全性和错误传播
异常安全性是软件设计中的一个重要概念,它涉及到异常发生时对象状态的正确性。cppsqlite的异常处理机制确保了异常安全性,即当数据库操作中出现错误时,不会破坏数据库的一致性。
关于错误传播,cppsqlite允许开发者决定是否在发生异常时终止程序,或者将异常信息记录下来并继续执行。这取决于你如何设计你的异常处理逻辑。
6.2 事务处理和一致性保证
事务是保证数据库数据一致性的核心机制之一。cppsqlite提供了对事务的支持,确保了数据库操作的acid特性(原子性、一致性、隔离性、持久性)。
6.2.1 事务的级别和隔离性
事务的隔离级别决定了数据在并发访问时的状态。cppsqlite支持四种事务隔离级别,分别是 read_uncommitted 、 read_committed 、 repeatable_read 和 serializable 。
try {
db.exec("begin transaction");
// 执行一系列sql命令
db.exec("commit"); // 或者 rollback
} catch (const exception &e) {
db.exec("rollback");
std::cerr << "transaction error: " << e.what() << std::endl;
}在上述示例中,通过执行 begin transaction 开始一个事务,然后执行一系列sql操作。如果过程中出现错误,可以通过 rollback 命令撤销事务中的所有操作。如果一切正常,执行 commit 命令提交事务。
6.2.2 事务控制和故障恢复
事务控制是指对数据库操作中事务的开启、提交、回滚进行控制。cppsqlite库中的事务控制非常灵活,允许开发者在出现异常时采取必要的恢复措施。
例如,如果在事务执行过程中程序崩溃,cppsqlite在下一次打开数据库时可以自动进行恢复。而对于程序异常退出,建议在程序开始时检查数据库状态,以确定是否需要进行故障恢复。
if (db.isintransaction()) {
// 如果检测到数据库处于事务中,则自动回滚
db.exec("rollback");
}在上面的代码中,我们检查数据库是否处于事务状态,如果是,则执行回滚操作。
综上所述,异常处理和事务管理是cppsqlite中确保数据库操作安全性和一致性的重要机制。了解并正确使用这些机制,可以帮助开发者编写健壮的数据库操作代码。
到此这篇关于windows下c++使用sqlite的文章就介绍到这了,更多相关c++使用sqlite内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论