1、canal下载
canal实现mysql数据同步可以直接安装canal server就可以了,但是为了方便管理(instance配置,canal server状态管理,集群等),需要安装canal admin,应用下载地址:releases · alibaba/canal · github
进入页面可以选择需要安装的版本
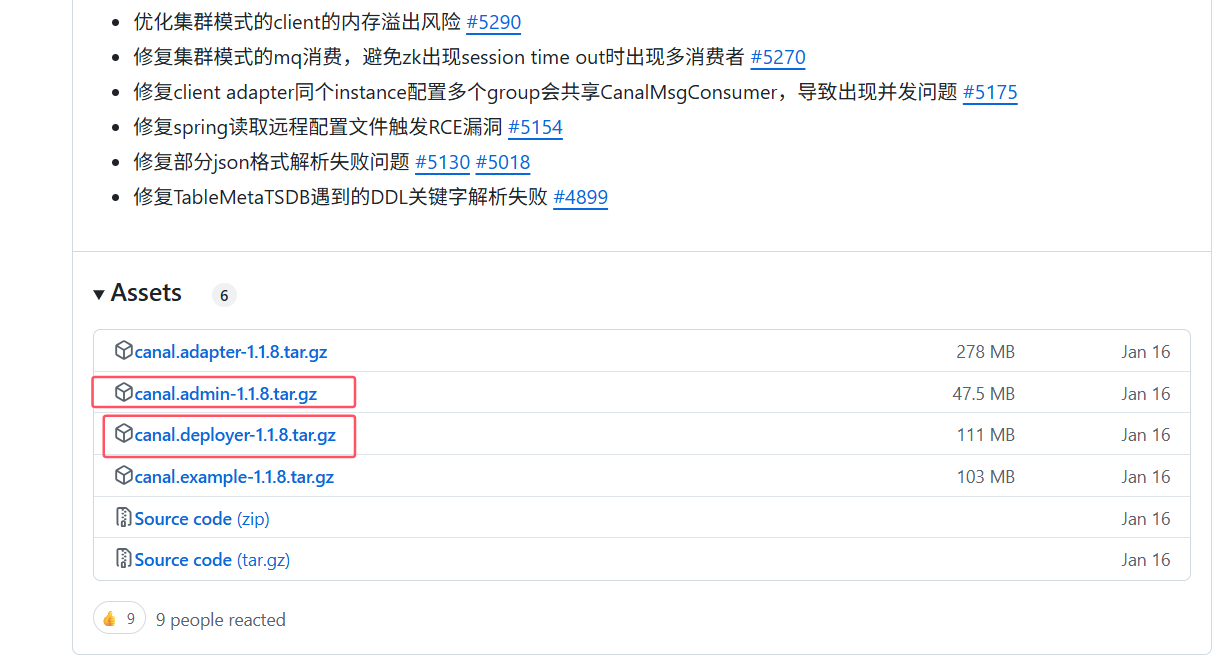
下载canal.deployer-1.1.8.tar.gz和canal.admin-1.1.8.tar.gz
2、mysql同步用户创建和授权
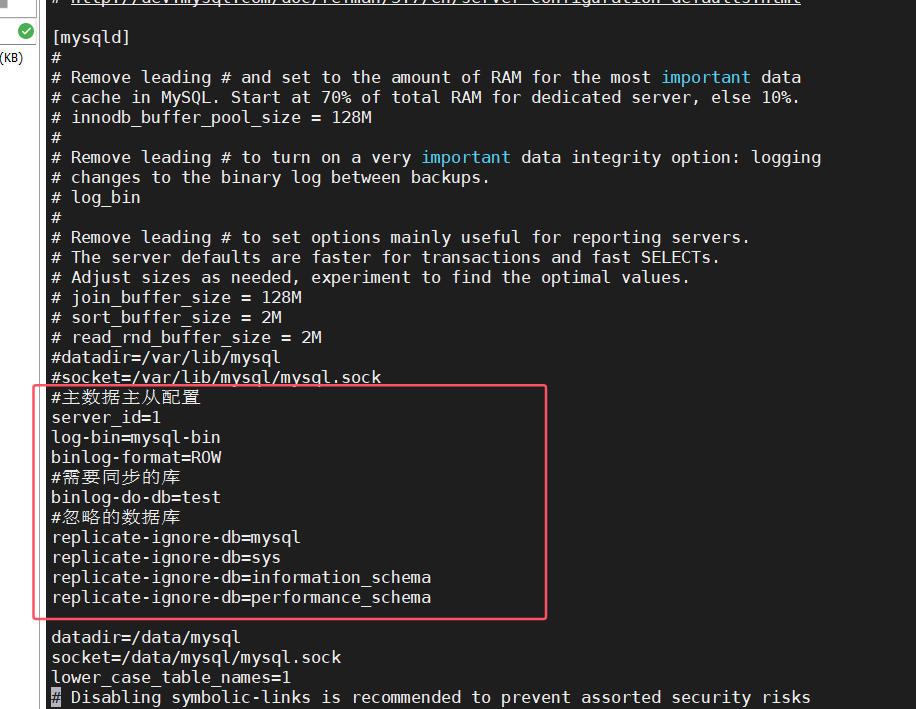
登录mysql mysql -h 127.0.0.1 -p 3306 -u root -p 创建同步用户 repl 密码设为123456 create user 'repl'@'%' identified by '123456'; 给予同步权限 grant replication slave on *.* to 'repl'@'%' identified by '123456'; 给予repl只读test库的权限,test库是用来同步数据的 grant select on test.* to 'repl'@'%' identified by '123456'; canal_manager是canal admin需要的,给予repl对该库的读写权限 grant all privileges on canal_manager.* to 'repl'@'%' identified by '123456'; mysql my.cnf配置文件增加主从配置master数据库的配置信息 #主数据主从配置 唯一id server_id=1 #开启logbin log-bin=mysql-bin #写入模式 row binlog-format=row #需要同步的库 binlog-do-db=test #忽略的数据库 replicate-ignore-db=mysql replicate-ignore-db=sys replicate-ignore-db=information_schema replicate-ignore-db=performance_schema
在canal-admin解压文件的conf中有一个canal_manager.sql,导入到master数据库
3、canal admin安装和启动
把canal.admin-1.1.8.tar.gz上传到linux
解压 tar -zvxf canal.admin-1.1.8.tar.gz
进入conf目录下,编辑application.yml配置文件。
server:
port: 8089
spring:
jackson:
date-format: yyyy-mm-dd hh:mm:ss
time-zone: gmt+8
spring.datasource:
address: 127.0.0.1:3306
database: canal_manager
username: repl
password: 123456
driver-class-name: com.mysql.jdbc.driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useunicode=true&characterencoding=utf-8&usessl=false&allowpublickeyretrieval=true
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminuser: admin
adminpasswd: 123456重点介绍以下几个参数:
address:我们需要订阅(也就是mysql master服务器)mysql所在的服务器ip和数据库端口。
database:canal.admin web系统必须的几张表,需要在mysql master服务器上初始化conf/canal_manager.sql文件。
sername和password就是mysql master服务器创建的用于复制的用户和密码,也就是我们在canal server中配置的repl 和 123456。
driver-class-name:mysql的驱动,默认是mysql5的驱动,如果你的mysql是8的(我的就是),要将驱动改为com.mysql.cj.jdbc.driver。
另外,还需要在mysql连接后面加上allowpublickeyretrieval=true,不然启动时,有可能报错。
启动canal.admin
进入bin目录,执行如下命令,启动canal.admin:
./startup.sh
查看 admin 日志
2022-12-10 03:13:58.995 [main] info o.s.jmx.export.annotation.annotationmbeanexporter -
located mbean 'datasource': registering with jmx server as mbean [com.zaxxer.hikari:name=datasource,type=hikaridatasource]
2022-12-10 03:13:59.015 [main] info org.apache.coyote.http11.http11nioprotocol - starting protocolhandler ["http-nio-8089"]
2022-12-10 03:13:59.038 [main] info org.apache.tomcat.util.net.nioselectorpool - using a shared selector for servlet write/read
2022-12-10 03:13:59.214 [main] info o.s.boot.web.embedded.tomcat.tomcatwebserver - tomcat started on port(s): 8089 (http) with context path ''
2022-12-10 03:13:59.221 [main] info com.alibaba.otter.canal.admin.canaladminapplication - started canaladminapplication in 14.281 seconds (jvm running for 15.894)
如果出现上述日志,说明启动成功!
登录admin
通过http://127.0.0.1:8089/访问,默认密码:admin/123456。
注意,ip和密码需要改成你自己配置的。如果是在服务器上配置的,别忘记放开8089端口。
输入用户名和密码之后,出现上述页面说明配置成功!
如果需要修改密码,直接通过执行 select upper(sha1(unhex(sha1('1234567')))) 这个sql得到结果,然后复制到canal_manager库的canal_user表的password字段中就可以了,其中1234567是明文密码,执行上述sql会得到一个密码。
4、canal server安装和启动
把canal.deployer-1.1.8.tar.gz上传到linux
解压 tar -zvxf ccanal.deployer-1.1.8.tar.gz
进入conf目录下,编辑canal.properties配置文件。
注意,如果直接编辑canal.properties,可能无法启动,报如下错误:

可以通过如下方式修改
mv canal.properties canal.properties_bak cp canal_local.properties canal.properties vim canal.properties
canal.properties文件全部内容如下:
# register ip canal.register.ip = # canal admin config canaladmin 的链接、端口、用户名和md5密码 canal.admin.manager = 127.0.0.1:8089 canal.admin.port = 11110 canal.admin.user = admin canal.admin.passwd =6f32482bafc60f23b7736044cefc1799166e5cdb # admin auto register canal server启动后自动注入到canal admin管理模块 canal.admin.register.auto = true canal.admin.register.cluster = canal.admin.register.name =
一般只需要修改下面这3个
canal.admin.manager = 127.0.0.1:8089
canal.admin.user = admin
canal.admin.passwd =6f32482bafc60f23b7736044cefc1799166e5cdb
启动canal.server
进入bin目录,执行如下命令,启动canal.server:
./startup.sh
查看canal日志

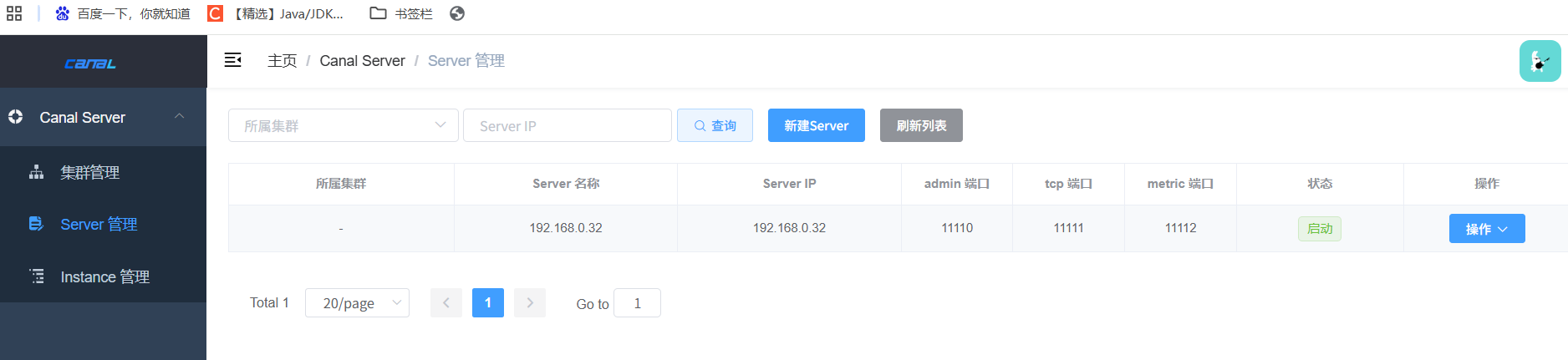
启动后,canaladmin的server管理模块,对应创建的canal server会动态识别到,状态变为启动
5、canal数据同步
5.1、java 端集成监听canal 同步的mysql数据
1、引入依赖
<dependency>
<groupid>com.alibaba.otter</groupid>
<artifactid>canal.client</artifactid>
<version>1.1.4</version>
</dependency>2、编写测试代码
package com.hy.das.config;
import com.alibaba.fastjson.jsonobject;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.client.canalconnectors;
import com.alibaba.otter.canal.protocol.canalentry;
import com.alibaba.otter.canal.protocol.message;
import com.google.protobuf.bytestring;
import org.springframework.beans.factory.initializingbean;
import org.springframework.stereotype.component;
import java.net.inetsocketaddress;
import java.util.list;
@component
public class canalclient implements initializingbean{
private final static int batch_size = 1000;
@override
public void afterpropertiesset() throws exception {
// 创建链接 此处的11111为tcp端口 在canal admin server管理模块可以查看
canalconnector connector = canalconnectors.newsingleconnector(new inetsocketaddress("127.0.0.1", 11111),
"test", "", "");
try {
//打开连接
connector.connect();
//订阅数据库表,全部表
connector.subscribe(".*\\..*");
//回滚到未进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始拿
connector.rollback();
while (true) {
// 获取指定数量的数据
message message = connector.getwithoutack(batch_size);
system.out.println(message.getentries().size());
//获取批量id
long batchid = message.getid();
//获取批量的数量
int size = message.getentries().size();
//如果没有数据
if (batchid == -1 || size == 0) {
try {
//线程休眠2秒
thread.sleep(2000);
} catch (interruptedexception e) {
e.printstacktrace();
}
} else {
system.out.println("----------------");
//如果有数据,处理数据
//遍历entries,单条解析
for (canalentry.entry entry : message.getentries()) {
//获取表名
string tablename = entry.getheader().gettablename();
//获取类型
canalentry.entrytype entrytype = entry.getentrytype();
//获取序列化后的数据
bytestring storevalue = entry.getstorevalue();
//判断entry类型是否为rowdata类型
if (canalentry.entrytype.rowdata.equals(entrytype)){
//反序列化
canalentry.rowchange rowchange = canalentry.rowchange.parsefrom(storevalue);
//获取当前事件操作类型
canalentry.eventtype eventtype = rowchange.geteventtype();
//获取数据集
list<canalentry.rowdata> rowdataslist = rowchange.getrowdataslist();
//遍历
for (canalentry.rowdata rowdata : rowdataslist) {
//改变前数据
jsonobject jsonobjectbefore = new jsonobject();
list<canalentry.column> beforecolumnslist = rowdata.getbeforecolumnslist();
for (canalentry.column column : beforecolumnslist) {
jsonobjectbefore.put(column.getname(),column.getvalue());
}
//改变后数据
jsonobject jsonobjectafter = new jsonobject();
list<canalentry.column> aftercolumnslist = rowdata.getaftercolumnslist();
for (canalentry.column column : aftercolumnslist) {
jsonobjectafter.put(column.getname(),column.getvalue());
}
system.out.println("table:"+tablename+",eventtpye:"+eventtype+",before:"+jsonobjectbefore+",after:"+jsonobjectafter);
}
}else {
system.out.println("当前操作类型为:"+entrytype);
}
}
}
//进行 batch id 的确认。确认之后,小于等于此 batchid 的 message 都会被确认。
connector.ack(batchid);
}
} catch (exception e) {
e.printstacktrace();
} finally {
connector.disconnect();
}
}
}
newsingleconnector方法里面的test是一个instance实列,定义了需要同步的master库的信息(ip、端口、用户名、密码、binlog文件名称、同步位置、需要同步的库、不需要同步的库等)
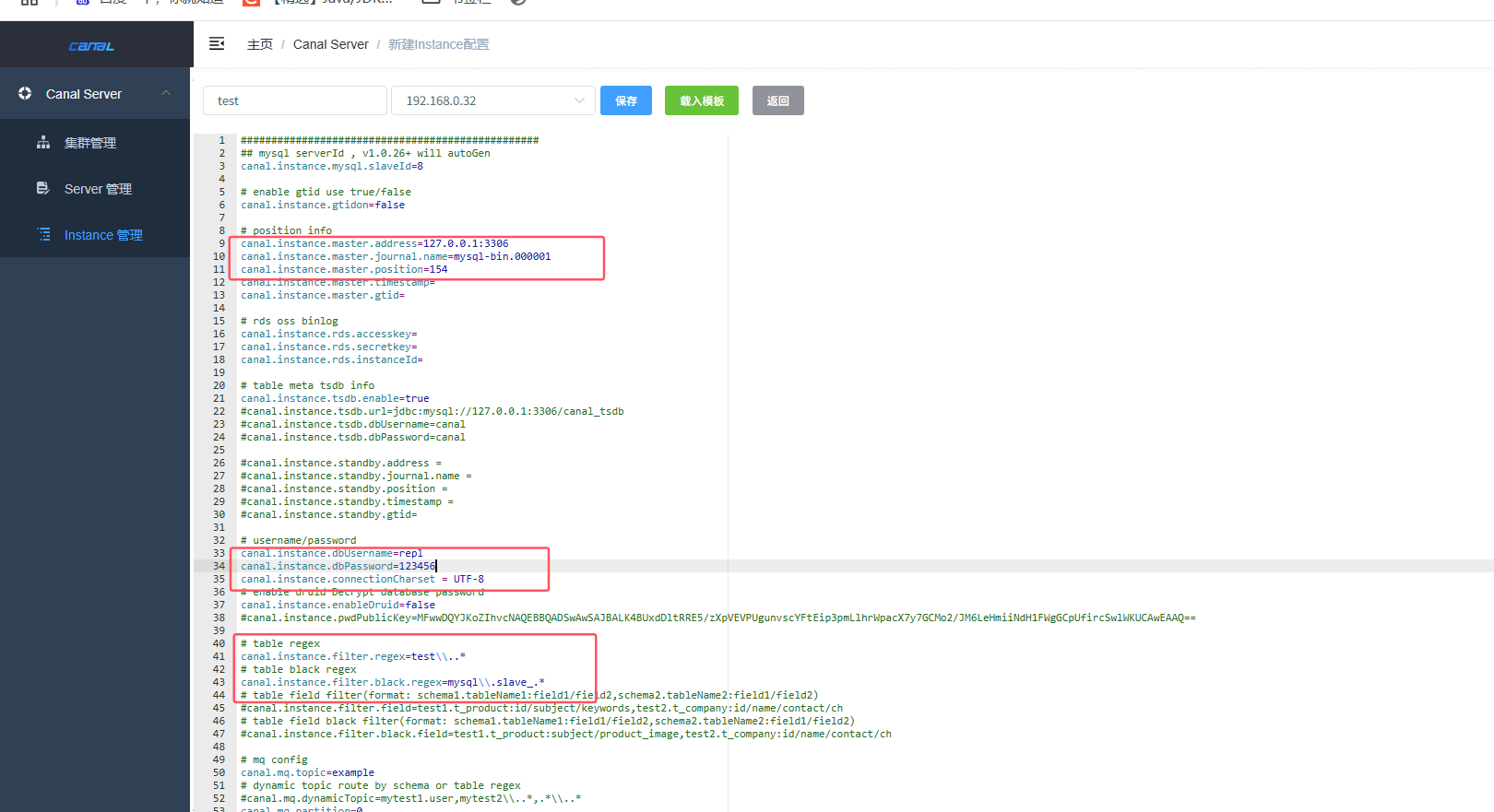
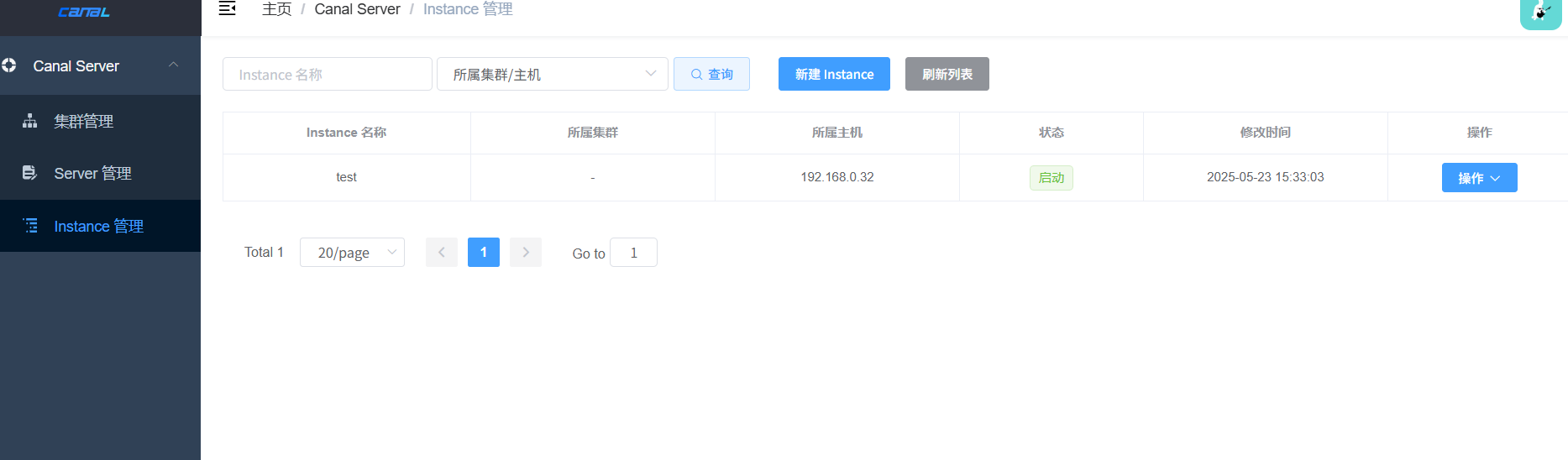
在canal admin web管理界面的instance 管理模块,点击新建instance进行创建,新建页面的instance名称就是test,这个可以随便填写,代码对应修改就行,所属集群/主机,因为我这里是单机部署,直接选择自动注入的canal server就行,点击载入模板,获取配置初始信息,下图中标出的信息按照实际的修改填入就行,点击保存后,启动这个instance。
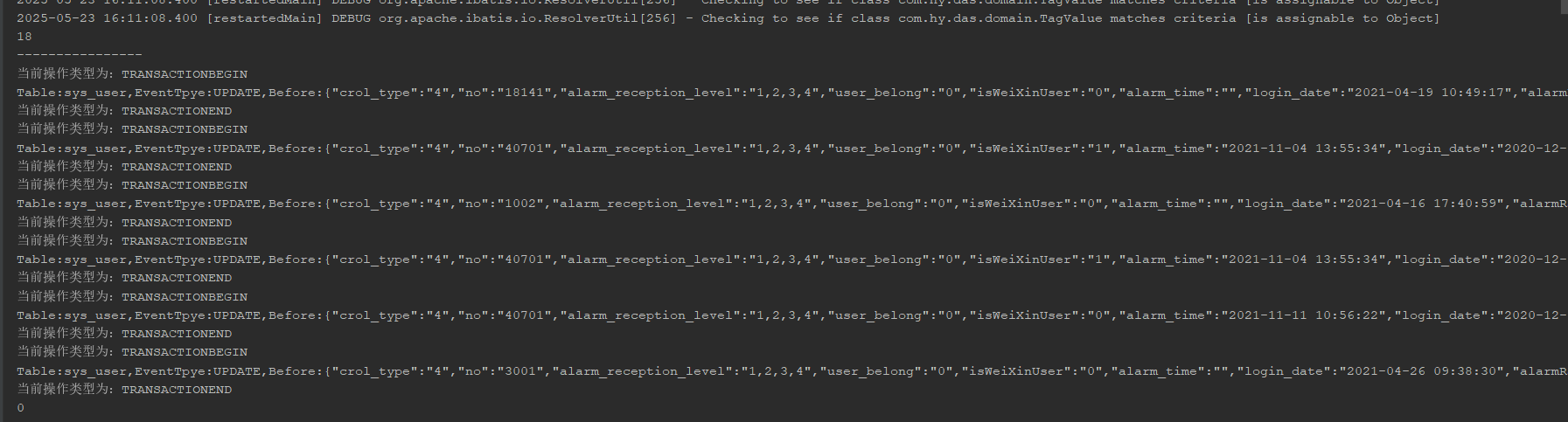
3、启动服务,对test库的sys_user表进行数据更新,可以看到后台已经收到变更数据
5.2、kafka同步数据
1:canal.properties配置文件增加如下配置
#数据变更发送到kafka # 设置输出目标为 kafka canal.servermode = kafka # kafka 地址 canal.mq.servers = xx.xx.xx.xx:9092 # 投递失败的重试次数,默认0,改为2 canal.mq.retries = 2 # kafka batch.size,即producer一个微批次的大小,默认16k,这里加倍 canal.mq.batchsize = 32768 # kafka max.request.size,即一个请求的最大大小,默认1m,这里也加倍 canal.mq.maxrequestsize = 2097152 # kafka linger.ms,即sender线程在检查微批次是否就绪时的超时,默认0ms,这里改为200ms # 满足batch.size和linger.ms其中之一,就会发送消息 canal.mq.lingerms = 200 # kafka buffer.memory,缓存大小,默认32m canal.mq.buffermemory = 33554432 # 获取binlog数据的批次大小,默认50 canal.mq.canalbatchsize = 50 # 获取binlog数据的超时时间,默认200ms canal.mq.canalgettimeout = 200 # 是否将binlog转为json格式。如果为false,就是原生protobuf格式 canal.mq.flatmessage = true # 压缩类型,官方文档没有描述 canal.mq.compressiontype = none # kafka acks,默认all,表示分区leader会等所有follower同步完才给producer发送ack # 0表示不等待ack,1表示leader写入完毕之后直接ack canal.mq.acks = all # kafka消息投递是否使用事务 # 主要针对flatmessage的异步发送和动态多topic消息投递进行事务控制来保持和canal binlog位置的一致性 # flatmessage模式下建议开启 canal.mq.transaction = true
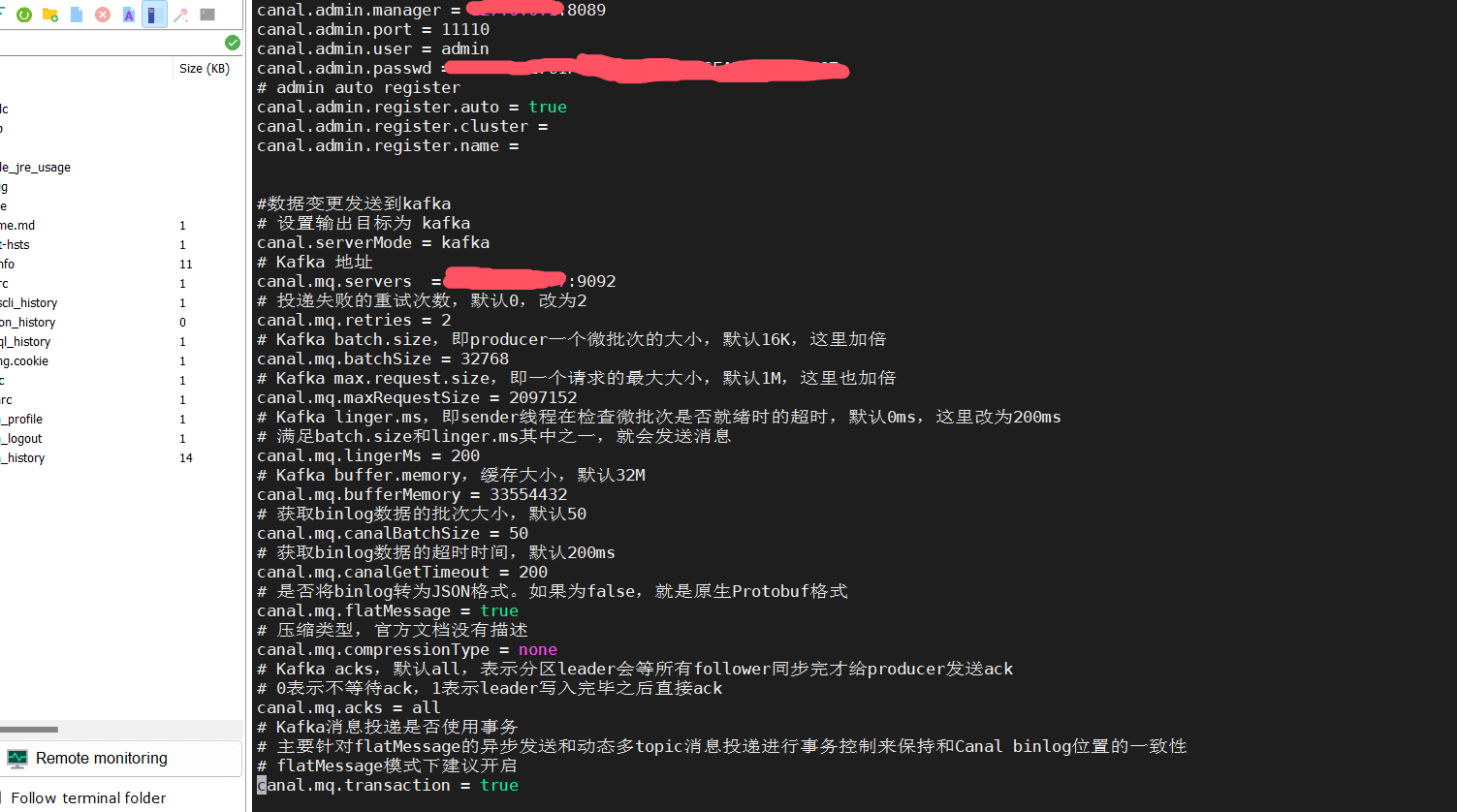
2:在canal admin web界面修改instance mq配置,增加数据同步到kakfa的topic
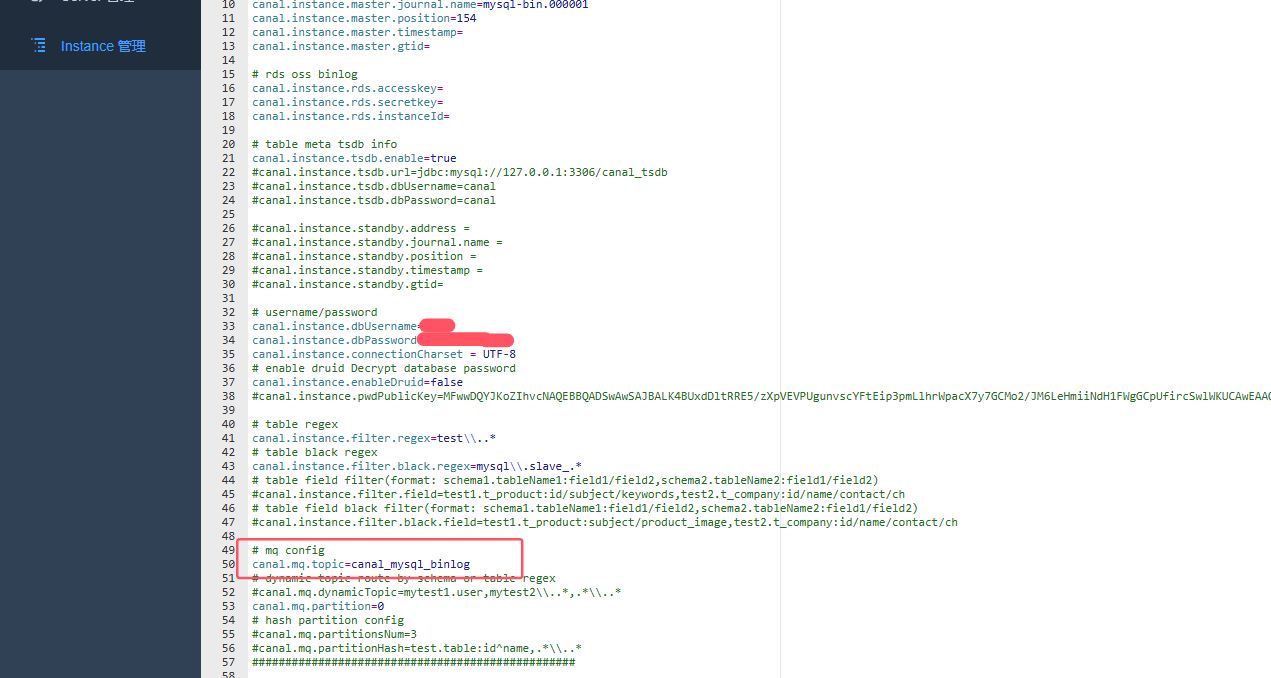
3:如上两步配置完成重启后,在kafka监听配置的topic就可以接收到数据了
6、java tcp同步只是其中一种方式,还可以通过kafka、rabbitmq等方式进行数据同步
注意上面需要提供对外访问的端口需要开通安全组,比如8089、11111等端口。
参考文章:
https://zhuanlan.zhihu.com/p/590705531
到此这篇关于canal实现mysql数据同步的文章就介绍到这了,更多相关canal mysql数据同步内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论