锁是计算机协调多个线程访问同一个系统资源的机制
锁的分类:
- 从数据的操作类型分为:读锁和写锁
- 从数据的操作粒度分为:行锁和表锁
表锁
偏读,myisam存储引擎,开销小,加锁快,无死锁,锁定粒度大,并发度最低
添加锁
lock table 数据表名 read/write,数据表2 read/write... -- 比如我要给mylock表加读锁,给book表加写锁 lock table mylock read,book write;
查看那些表被加了锁
show open tables;
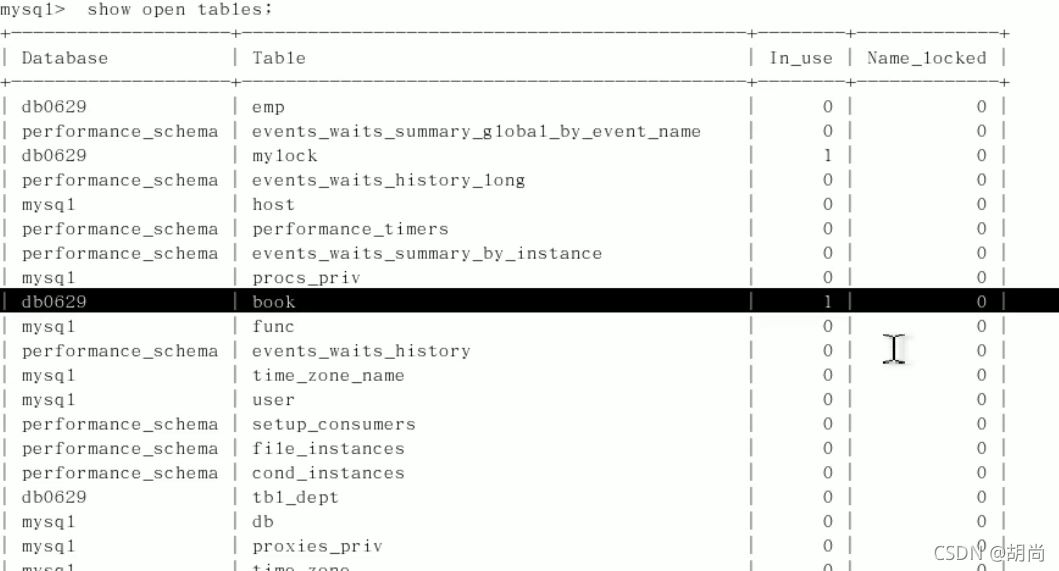
第三列in_use字段如果为1则表示加锁了
释放所有表的锁
unlock tables;
执行完该命令后在执行show open tables; 命令就会发现所有数据表的in_use字段都为0了。
加锁对我们的数据操作和系统性能有什么影响
结论:
如果在会话1中给某个数据表加了读锁,其他会话就只能查看该表的数据,会话1不能对当前表进行修改操作,会报错;会话1也不能查询其他未加锁的数据表。而其他会话如果对该数据表进行修改操作会一直阻塞,但不会报错,直到会话1执行unlock tables; 命令将锁释放掉 才会解除阻塞状态进而执行成功修改操作。其他会话还是可以查询其他表的数据。
如果在会话1中给某个数据表加了写锁,会话1能对当前表进行查询修改操作,但不能查询其他未加锁的数据表,其他会话不能对加了写锁的数据表进行查询修改操作,会阻塞住。
简而言之,读锁会阻塞写操作,但不会阻塞读操作;写锁会阻塞其他会话的增删改查操作。
具体步骤如下:
首先是读锁,
首先在当前会话1 对mylock数据表加读锁
lock table mylock read;
然后查看表的当前数据
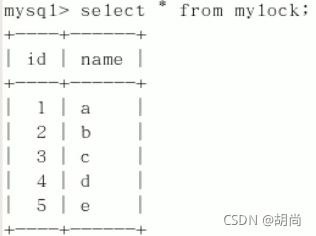
另一个会话,另一个命令行窗口也能查看mylock数据表内容。
然后在会话1中 查询其他未锁定的表的数据,发现还是报错了
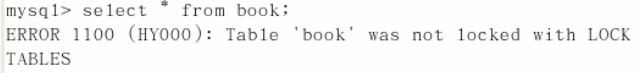
但会话2 还是可以查询其他表的数据,
这个时候在会话1 中对mylock数据表进行修改操作
update mylock set name='aaa' where id=1;
执行就会发现报错了,这是因为加了读锁后不能再对数据表进行修改操作了。
会话2 也如果对mylock表进行修改操作,会一直阻塞住,但不会报错。如果这个时候会话1执行unlock tables;进行解锁,会话2的修改操作就会立刻执行成功。
然后是写锁
在会话1中对mylock表加写锁
lock table mylock write;
会话1中读取自己当前锁的表,发现能读
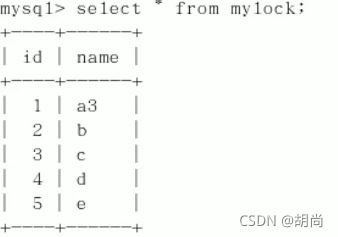
但是会话2 读取mylock数据表就会出现阻塞,也不会报错 就一直等待,当会话1释放锁后就能读取到数据了。如果在会话1释放锁之前 会话2也能读取到数据,那原因是mysql有缓存,如果之前查询过一次,第二次查询就会从缓存中取数据。
会话1 对mylock表进行修改操作,发现也能成功

但会话2 连查询都不可以 修改操作也肯定不行。
会话1 查询其他未锁的表,会报错
会话2 查询其他表,能正常查询。
分析表的锁定
show status like 'table%';
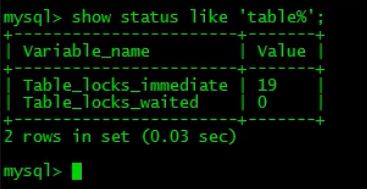
这里两个状态变量记录mysql内部表级锁定的情况,两个变量分析如下:
- table_locks_immediate : 产生表级锁定的次数,表示可以立即获取锁的查询次数,每立刻获取锁加1
- table_locks_waited: 锁的等待情况,每等待一次,值加1,如果该数值很高则表示存在严重的表级锁争用情况
此外:myisam存储引擎读写锁调度是写优先,也就是说它不适合做为写为主的表的存储引擎。因为写锁后,其他线程就不能进行任何操作,会阻塞。
行锁
偏向于innodb存储引擎,开销大、加锁慢、会出现死锁、锁定粒度最小、发生锁冲突的概率最低,并发度最高。
myisam和innodb存储引擎最大的区别是:事务是否支持,表锁与行锁
接下里就是会行锁的理解,首先是建一个数据表,并且为这个数据表的两列都创建了单值索引
create index idx_til_a on text_innodb_lock(a); create index idx_til_a on text_innodb_lock(b);
然后查询一次数据

首先还是一样开两个会话,mysql事务的隔离级别默认是可重复读。两个会话都想将自动提交关闭set autocommite=0;, 然后会话1对一个表进行修改操作,但没有提交,会话2查询这个表的数据能看到的是会话1修改前的值,然后会话1会话2都提交,会话2再读就写修改后的值了。这是之前事务的知识。
假如这两个会话,会话1先对这个数据表a=1的数据进行了修改,但没有提交,这个时候会话2也对a=1的数据进行修改操作,会话2的修改操作就会阻塞住,但不会报错。然后会话1提交,这时候会话2的修改操作也就解除阻塞了,然后会话2再提交
也就是两个会话 不能对同一行数据进行操作,会话2的更新操作会阻塞,需要等到会话1提交事务才能解除阻塞。
但如果两个会话 不是操作同一行数据则不会阻塞。
索引失效,行锁变表锁
在我们的sql如果导致了索引失效,那么就会把本来的行锁变为表锁
上面的数据表text_innodb_lock中 a字段是数字型,b字段是字符型
首先还是开两个会话,
关闭自动提交set autocommit=0;
会话1执行update tets_innodb_lock set b='4001' where a=4; 对a=4进行修改操作,但还没有提交
然后会话2执行update tets_innodb_lock set b='9001' where a=9; 对a=9进行修改操作,因为不是操作同一行数据,所以不会阻塞。
但如果索引失效,行锁就会变为表锁
会话1 对第三行进行修改操作,但未提交,这里故意将b=‘4000’ 写成了b=4000 使索引失效

然后会话2 对其他行进行修改,就阻塞住了

间隙锁
现在表的数据如下
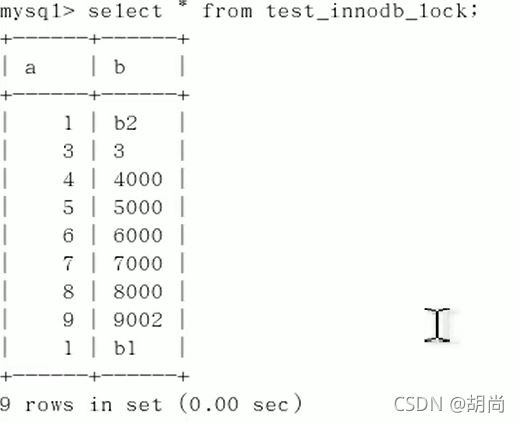
为了做云计算和大数据分析,数据最好是连续的,可是上面并没有a=2的记录。
这个时候会话1 进行一个范围性的修改操作,回车后,未提交
update test_innodb_lock set b='aaa' where a>1 and a<6;
会话2 进行一个新增操作,插入一个a=2的记录。 这边就会被阻塞住。
然后会话1提交后 会话2的阻塞才会被解除。
当我们使用范围条件而不是相等条件检索数据,innodb会给符合条件的已有数据记录的索引项加锁,对于符合范围查询条件但并不存在的记录就交间隙。
危害就是:它会锁定整个范围内的所有索引键值,即使这个键值不存在,某些场景下会对系统的性能造成伤害。
如何手动锁定一行
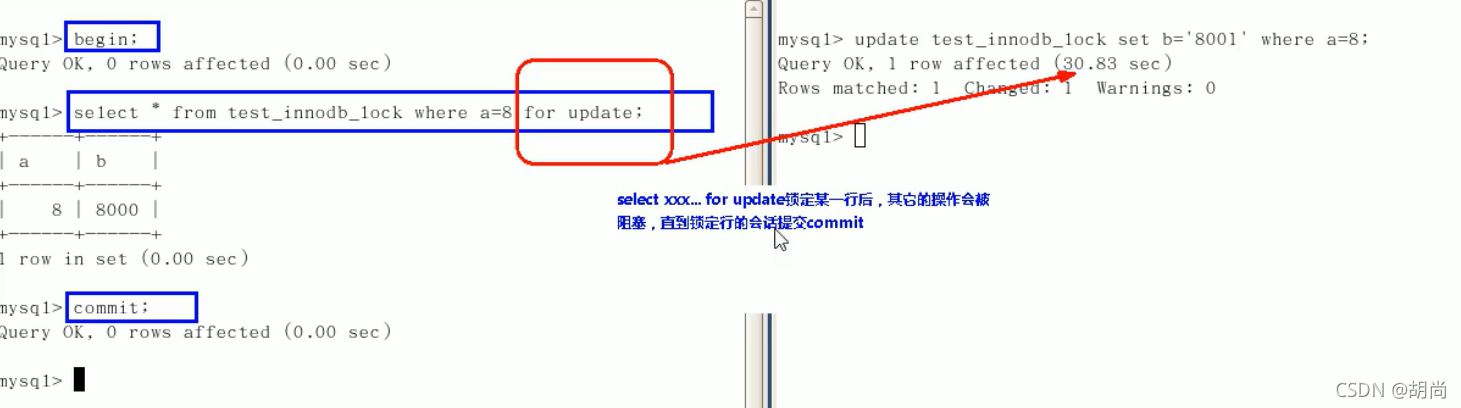
首先在命令行输入begin;
然后要锁的哪一行,就先查询那一行,在where条件后面加上for update
这个时候这一行的数据就被锁了 你只需要进行你的操作即可,然后你再提交
在上面的表锁 可以通过show status like 'table%'命令来查看表的一些锁定情况,
当然 行锁也有show status like 'innodb_row_lock%'
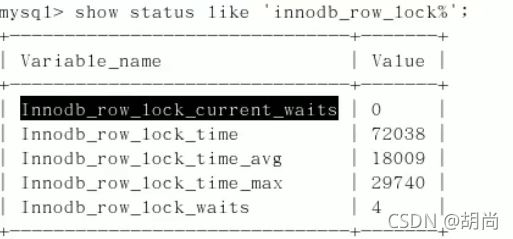
这各个参数的意思是:
- innodb_row_locak_current_waits:当前正在等待锁定的数量
- innodb_row_locak_time:从系统启动到现在,锁定总时间长度
- innodb_row_locak_time_avg:每次等待所花的平均时间
- innodb_row_locak_time_max:从系统启动到现在,等待时间最长的一次时间
- innodb_row_locak_waits:系统启动后到现在,总共等待的次数
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。




发表评论