1. 线程的生命周期
java 线程有明确的生命周期状态:
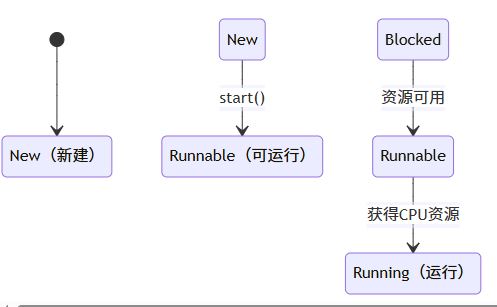
- 新建状态(new):创建 thread 对象后(如 new mythread()),线程尚未启动
- 可运行状态(runnable):调用 start() 后,线程进入就绪队列
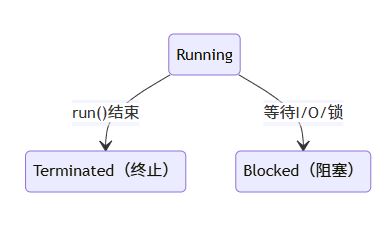
- 运行状态(running):线程获得 cpu 时间片,执行 run() 方法
- 终止状态(terminated):run() 执行完毕
关键点:只有调用 start() 才能使线程从 new 进入 runnable 状态!
2. start() vs run() 的本质区别
| 方法 | 工作方式 | 线程数量 | 执行位置 |
|---|---|---|---|
start() | jvm 创建新线程并执行 run() | 新线程 | 独立调用栈 |
run() | 直接调用普通方法 | 当前线程 | 当前线程调用栈 |
错误示例:
thread thread = new thread(() -> system.out.println("执行中"));
thread.run(); // 错误!在主线程同步执行
正确示例:
thread.start(); // 正确!启动新线程异步执行
3. 为什么必须通过 start() 启动线程?
(1) 资源分配
调用 start() 时,jvm 会:
- 为线程分配独立调用栈(stack)
- 注册线程到系统调度器
- 触发操作系统级别的线程创建
(2) 异步执行
start()使任务在后台异步执行,不阻塞当前线程- 直接调用
run()会同步执行,阻塞当前线程
(3) 线程调度控制
只有通过 start() 启动的线程才能被:
- 线程调度器管理(优先级、时间片分配)
- 正确响应中断(
interrupt()) - 加入线程池统一管理
(4) 状态合规性
多次调用 start() 会抛出 illegalthreadstateexception,而 run() 可重复调用。这保证了线程状态机的正确性。
4. 底层机制
当调用 start() 时:
public synchronized void start() {
if (threadstatus != 0) // 检查状态是否为new
throw new illegalthreadstateexception();
group.add(this); // 加入线程组
boolean started = false;
try {
start0(); // 关键!调用本地方法
started = true;
} finally {
// ...错误处理
}
}
private native void start0(); // jvm实现的本地方法
start0()是native方法,由 jvm 通过操作系统 api 创建真实线程- 新线程创建后自动执行
run()方法
5. 实际应用场景
假设需要同时下载3个文件:
// 错误方式(顺序下载)
new downloadtask("url1").run(); // 阻塞主线程
new downloadtask("url2").run(); // 等待前一个完成
new downloadtask("url3").run();
// 正确方式(并行下载)
new thread(new downloadtask("url1")).start(); // 异步
new thread(new downloadtask("url2")).start(); // 异步
new thread(new downloadtask("url3")).start(); // 异步
结论
| 操作 | 结果 | 是否启动线程 |
|---|---|---|
new thread() | 创建线程对象(new状态) | ❌ |
start() | 启动线程(进入runnable状态) | ✅ |
run() | 普通方法调用 | ❌ |
必须调用 start() 才能:
- 创建真正的操作系统线程
- 实现任务异步执行
- 符合线程生命周期规范
- 利用多核cpu实现并行计算
直接调用 run() 只是普通方法调用,完全违背了多线程的设计目的!
到此这篇关于java中实现线程的创建和启动的方法的文章就介绍到这了,更多相关java线程创建和启动内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论