dict基本结构
dict我们可以想象成目录,要翻看什么内容,直接通过目录能找到页数,翻过去看。如果没有目录,我们需要一页一页往后翻,这样时间复杂度就与遍历的o(n)一样了,而用了dict我们就可以在o(1)的时间复杂度内快速找到键对应的值。说到这里,大家会觉得dict与java中的哈希表功能差不多,其实,redis的dict数据结构底层实现正是哈希表,不过维护了2个哈希表。redis实现dict数据结构创建了三个重要的结构体,分别是dict、dictht和dictentry。下面先给出dict的整体结构帮助大家更好的理解一下:
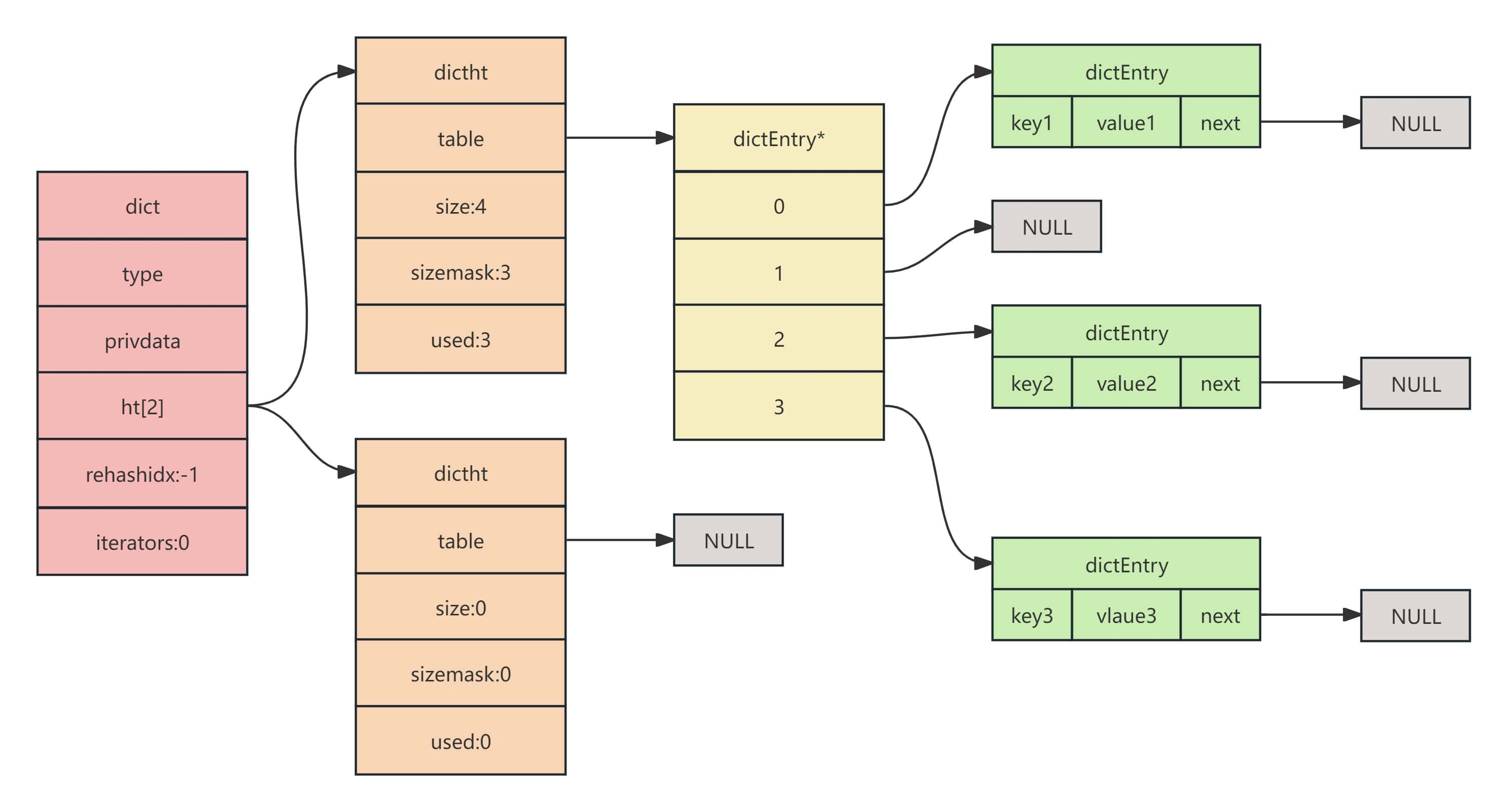
dict
typedef struct dict{
dicttype *type;
void *privdata;
dictht ht[2];
long rehashidx;
unsigned long iterators;
} dict;- ht[2]:表示在一个dict结构中,包含有两个dictht的结构,也就是我们说的两张哈希表。
- rehashidx:是dict在rehash时的偏移索引,具体如何工作在后边的rehash过程中会详细讲。
dictht
typedef struct dictht{
dictentry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
}dictht
- table:指向实际hash存储。存储可以看做是一个数组,所以是*table表示。(源码中的**table是一个二级指针,也就是指向dictentry*的指针)。
- size:哈希表的大小。实际就是dictentry有多少元素空间。
- sizemask:哈希表大小的掩码表示,总是等于size-1.这个属性和哈希值一起决定一个键应该被放到table数组的哪个索引上面,索引计算规则是index=hash&sizemask,前提是size的大小是二次方幂,这一点与java哈希表底层计算索引是一样的原理。
- used:表示已经使用的节点数量。通过这个字段可以很方便地查询到目前dict元素总量。
dictentry
typedef struct dictentry{
void *key;
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
struct dictentry *next;
}dictentry
- *key:存储键。
- v:用来存储具体的值,可以看到,值可以是一个指针,可以是uint64_t整数,也可以是int64_t整数。
- *next:用于采用拉链法将相同索引的dictentry串起来,解决哈希冲突问题。(采用的是头插法,java中jdk8之后采用的是尾插法,留个小问题,为什么java中不延续使用头插法?)
dict的渐进式扩容机制
想必大家有一个疑问,为什么dict底层要维护两张哈希表,实际存储的话使用一张哈希表不就可以了吗。其实,第二张哈希表的存在是为了给第一张哈希表的扩容提供支持。下面我们来详细介绍一下dict中哈希表的渐进式扩容流程和扩容时机。
dict渐进式扩容流程
首先,当向字典添加新元素时,发现第一张哈希表ht[0]需要扩容,就会进行rehash操作,为第二张哈希表ht[1]分配空间。ht[1]表的大小为大于等于ht[0]表used值的2倍的2次方幂。举个例子,如果ht[0]中已经使用的节点数量为500,那么扩容时ht[1]被分配的空间是1024而不是1000。这么做是为了维护扩容后表的大小始终是2次方幂。
接着,dict的rehashidx由静默状态(-1)变为开始工作状态(0)。
最后,迁移ht[0]中的数据到ht[1],也就是将数据从旧表中迁移到新表中。在rehash进行期间,每次对dict执行增删改查操作,程序会顺带迁移当前rehashidx在ht[0]上对应的数据,并更新偏移索引。与此同时,部分情况周期函数也会进行迁移。如果rehashidx刚好在一个已删除的空位置上,那么是直接返回还是尝试往下找?我们来看一下dictrehash函数的源码:
//int empty_visits = n*10;//max number of empty buckets to visit.
while(d->ht[0].table[d->rehashidx] == null) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}可以看到,答案是会继续往下去找,但是有个上限是n*10,即最多再找这么多次,n是传进来的参数,调用的时候实际值为1,即最多往后再找10个,这么做是防止因为连续碰到空位置导致主线程操作被阻塞。
随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被rehash到ht[1],此时再将ht[1]和ht[0]指针对象互换,同时将rehashidx设置为-1,表示rehash工作已经完成。这个事情也是在rehash函数做的,每次迁移完一个元素,会检查是否已经完成了整个迁移:
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictreset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}总结一下,渐进式扩容的核心就是删改查操作时顺带迁移,其中增的操作直接增到新表中。
dict渐进式扩容时机
redis提出了一个负载因子的概念(与java中的负载因子不同),用于表示目前dict的使用情况,是情况良好还是已经堵塞不堪。设负载椅子为f,那么负载因子计算公式为f=ht[0].used/ht[0].size,也就是使用空间大小和总空间大小的比值。redis会根据负载因子的情况来进行扩容。
当负载因子的值小于1时,认为dict的使用情况良好,不需要进行扩容。
当负载因子的值大于等于1时,说明此时的dict空间已经非常紧张了,新增的数据会发生哈希冲突在链表上堆叠。如果此时服务器没有执行bgsave或者bgrewriteaof这两个复制命令,就会立刻进行扩容,反之则不会立刻扩容。
当负载因子的值大于5时,说明此时的dict中哈希冲突已经非常严重了,哈希表的搜索性能严重退化向链表。此时不管服务器是否在执行复制命令,都会立刻对哈希表进行扩容操作。
dict为什么采用渐进式扩容机制?
在java中,哈希表其实也有扩容操作,并且是在单张表上完成的rehash操作。但是对于redis中的dict来说,两者存放的数据量不在一个量级上,由于redis是单线程的,如果对dict中存放的大量数据进行一次性rehash,那么耗费的时间会非常久,从而造成主线程的长时间阻塞。为了性能考虑,dict采用空间换时间的方法,多花费一张表的空间,配合渐进式扩容机制,几乎完全消除rehash可能造成的主线程阻塞。
dict的渐进式缩容机制
扩容是数据太多装不下,那么对应的缩容就是空间太富裕造成了浪费。缩容的过程其实和扩容是相似的,也是渐进式缩容,这里就不详细展开了。
同样的,redis也通过负载因子来控制什么时候缩容:
当负载因子大于等于0.1时,认为dict的空间合适,不需要进行缩容。
当负载因子小于0.1时,认为dict的空间太大造成浪费,进行缩容。ht[1]的大小为第一个大于等于ht[0]中used值的2次方幂(最小为4,如果已经是4了那就保持不变)。
同样的,如果有bgsave或者bgrewriteaof这两个复制操作正在执行,缩容也会受影响,不会进行。
总结
dict数据结构提供了快速索引数据的能力,其结构的设计和渐进式扩容的设计很值得大家学习。
到此这篇关于redis底层数据结构之字典(dict)的实现的文章就介绍到这了,更多相关redis 字典内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论