1. 背景与需求分析
1.1 原始需求
我们有一个 logmediaadidcache 类,用于缓存广告位 id,并定期从 redis 刷新数据。原始实现使用 set 存储数据,结构如下:
set logscraping:mediaadid [id1, id2, id3, ...]
但随着业务发展,我们需要存储更多元信息(如广告位名称、状态、更新时间等),仅用 set 已无法满足需求。
1.2 新需求
- 存储结构化数据:每个广告位 id 需要关联额外信息(如
name,status,updatetime)。 - 高效查询:快速获取某个广告位的详细信息。
- 定时监控:每10秒检查 redis 数据变化,确保缓存一致性。
因此,我们决定将数据结构从 set 改为 hash:
hash logscraping:mediaadid
id1 -> { "name": "广告位1", "status": "active" }
id2 -> { "name": "广告位2", "status": "inactive" }
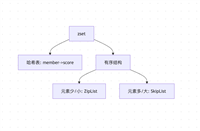
2. redis 数据结构选型:set vs. hash
| 特性 | set | hash |
|---|---|---|
| 存储方式 | 无序唯一集合 | 键值对存储(field-value) |
| 适用场景 | 去重、集合运算(交集、并集) | 结构化数据,需存储额外属性 |
| 查询效率 | o(1) 判断元素是否存在 | o(1) 按 field 查询 value |
| 扩展性 | 只能存储单一值 | 可存储复杂对象(json、map) |
结论:
- 如果仅需存储 id 并判断是否存在,set 更高效。
- 如果需要存储额外信息(如广告位详情),hash 更合适。
3. 代码改造:从 set 迁移到 hash
3.1 改造后的 logmediaadidcache
@component
@slf4j
@requiredargsconstructor
public class logmediaadidcache {
private final redistemplate<string, string> redistemplate;
private volatile set<long> cachedlogmediaadids = collections.emptyset();
public static final string log_redis_key = "logscraping:mediaadid";
@postconstruct
public void init() {
refreshcache();
}
@scheduled(fixedrate = 5 * 1000) // 每5秒刷新一次
public void refreshcache() {
try {
map<object, object> idmap = redistemplate.opsforhash().entries(log_redis_key);
if (idmap != null) {
set<long> newcache = idmap.keyset().stream()
.map(key -> long.valueof(key.tostring()))
.collect(collectors.toset());
this.cachedlogmediaadids = newcache;
log.info("广告位id缓存刷新成功,数量: {}", newcache.size());
}
} catch (exception e) {
log.error("刷新广告位id缓存失败", e);
}
}
public set<long> getlogmediaadids() {
return collections.unmodifiableset(cachedlogmediaadids);
}
public boolean contains(long mediaadid) {
return cachedlogmediaadids.contains(mediaadid);
}
// 新增方法:获取广告位详情
public string getadinfo(long mediaadid) {
return redistemplate.<string, string>opsforhash().get(log_redis_key, mediaadid.tostring());
}
// 新增方法:更新广告位信息
public void updateadinfo(long mediaadid, string info) {
redistemplate.opsforhash().put(log_redis_key, mediaadid.tostring(), info);
refreshcache(); // 立即刷新缓存
}
}
3.2 主要改进点
- 改用
opsforhash()操作 redis hash,支持结构化存储。 - 新增
getadinfo()方法,按广告位 id 查询详情。 - 新增
updateadinfo()方法,支持动态更新数据。
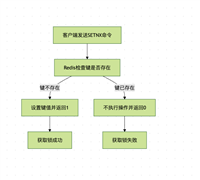
4. 定时任务优化:每10秒监控 redis 数据
4.1 新增 logstatsmonitorjob
@component
@slf4j
@requiredargsconstructor
public class logstatsmonitorjob {
private final redistemplate<string, string> redistemplate;
private static final string log_stats_key = "log:stats:1635474646";
@scheduled(fixedrate = 10 * 1000) // 每10秒执行一次
public void monitorlogstats() {
string currenttimekey = getformattedtime();
string fullkey = log_stats_key + ":" + currenttimekey;
try {
map<object, object> stats = redistemplate.opsforhash().entries(fullkey);
if (stats == null || stats.isempty()) {
log.warn("未找到统计信息: {}", fullkey);
return;
}
log.info("----- 统计信息监控(key: {})-----", fullkey);
stats.foreach((field, value) ->
log.info("{}: {}", field, value));
// 业务处理示例
int total = integer.parseint(stats.getordefault("total", "0").tostring());
if (total > 1000) {
log.warn("警告:数据量过大({}条)", total);
}
} catch (exception e) {
log.error("监控统计信息失败", e);
}
}
private string getformattedtime() {
// 生成格式化的时间戳,如 20250609175050
return localdatetime.now()
.format(datetimeformatter.ofpattern("yyyymmddhhmmss"));
}
}
4.2 功能说明
- 定时任务:每10秒检查 redis hash 数据。
- 动态 key:支持按时间戳生成 key(如 log:stats:1635474646:20250609175050)。
- 异常处理:捕获 redis 操作异常,避免任务中断。
- 业务告警:数据量超过阈值时触发告警。
5. 完整代码实现
5.1 logmediaadidcache(改造后)
(见上文 3.1 节)
5.2 logstatsmonitorjob(新增)
(见上文 4.1 节)
5.3 配置类(可选)
@configuration
@enablescheduling
public class schedulingconfig {
// 启用定时任务
}
6. 总结与最佳实践
6.1 关键改进
- 数据结构升级:从 set → hash,支持结构化存储。
- 定时任务优化:每10秒监控数据,确保实时性。
- 代码健壮性:异常处理 + 日志记录。
6.2 最佳实践
- 合理选择数据结构:根据业务场景选择 set / hash / zset 等。
- 动态 key 设计:如时间戳、业务id等,方便数据分区。
- 定时任务调优:
- 短周期(如10s)适合实时监控。
- 长周期(如1h)适合批量处理。
- 异常处理:避免因 redis 异常导致任务崩溃。
6.3 后续优化方向
- 数据分片:若数据量过大,可采用分片存储。
- 分布式锁:避免多实例任务重复执行。
- 数据过期策略:设置 ttl 自动清理旧数据。
结语
本文通过一个实际案例,演示了如何将 redis 数据结构从 set 迁移到 hash,并实现高效定时监控。合理的数据结构选择 + 定时任务优化,可以显著提升系统性能和可维护性。
以上就是redis定时监控与数据处理实践指南的详细内容,更多关于redis定时监控与数据处理的资料请关注代码网其它相关文章!




发表评论