引言
在分布式系统和高并发场景中,redis 作为高性能内存数据库的地位举足轻重。对于 java 开发者而言,掌握 redis 的连接与操作是进阶必备技能。然而,从基础的 jedis 原生客户端到 spring 封装的 redistemplate,不同连接方式的原理与适用场景常让初学者困惑。如何选择合适的连接方式?序列化配置背后的逻辑是什么?生产环境中又该如何优化?
本文从 java 操作 redis 的核心需求出发,通过完整代码示例与逐行解析,系统讲解 jedis 直接连接、连接池、redistemplate 及 stringredistemplate 的使用方法,深入剖析连接原理、序列化机制与性能优化策略。无论你是刚接触 redis 的小白,还是需要规范项目实践的开发者,都能从代码细节与原理分析中获得启发,掌握从基础连接到高级应用的全流程实战技巧。
1. redis 基础概念与 java 生态概览
1.1 redis 是什么?
redis(remote dictionary server)是一个基于内存的高性能键值对存储系统,具有以下核心特性:
- 数据结构丰富:支持 string、hash、list、set、sorted set 等 8 种数据结构
- 内存级性能:读写速度可达 10 万 + 次 / 秒(string 类型)
- 持久化支持:提供 rdb(快照)和 aof(日志)两种持久化方式
- 集群能力:支持主从复制、哨兵模式、cluster 集群
- 多语言支持:提供 java、python、node.js 等多语言客户端
在 java 生态中,主流的 redis 客户端包括:
- jedis:官方提供的原生 java 客户端,支持同步阻塞式 io
- lettuce:基于 netty 的异步非阻塞客户端,支持响应式编程
- spring data redis:spring 封装的高层抽象,支持 jedis/lettuce 作为底层连接
1.2 java 操作 redis 的核心场景
- 缓存系统:降低数据库压力(如商品详情页缓存)
- 分布式会话:解决集群环境下的 session 共享问题
- 计数器:实现点赞计数、接口限流等功能(利用 incr 命令)
- 消息队列:基于 list 的 lpush/rpop 实现简单队列
- 分布式锁:通过 setnx 命令实现分布式锁机制
2.jedis 原生客户端:从直接连接到连接池
2.0 maven依赖
<!-- jedis-->
<dependency>
<groupid>redis.clients</groupid>
<artifactid>jedis</artifactid>
<version>3.7.0</version>
</dependency>
2.1 jedis 直接连接(非池化方式)
2.1.1 核心代码解析
@slf4j
@springboottest
public class jedisdirect {
private jedis jedis;
@beforeeach
public void setup(){
//建立连接
jedis = new jedis("x.x.x.x",6379);
//设置密码
jedis.auth("xxxx");
//选择库
jedis.select(0);
}
@test
public void teststring(){
jedis.set("namepool","zhangsanpool");
string value = jedis.get("name");
log.info("value:"+value);
}
@test
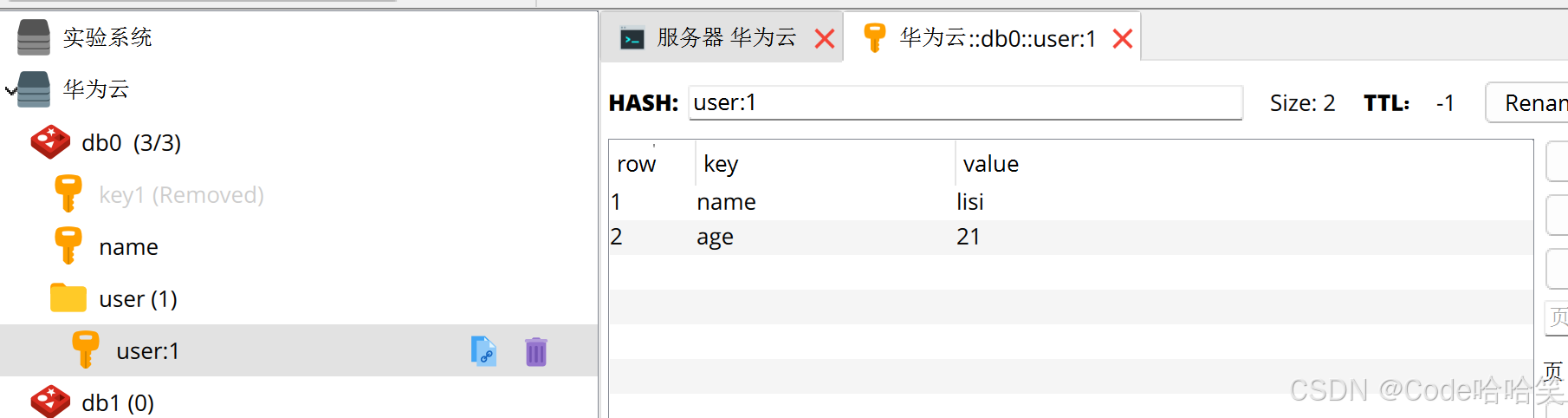
public void testhash(){
jedis.hset("user:2","name","lisipool");
jedis.hset("user:2","age","21");
map<string,string> map = jedis.hgetall("user:1");
log.info("map:"+ map.tostring());
}
@aftereach
public void teardown(){
if(jedis != null){
jedis.close();
}
}
}
代码的执行结果:
结果1:
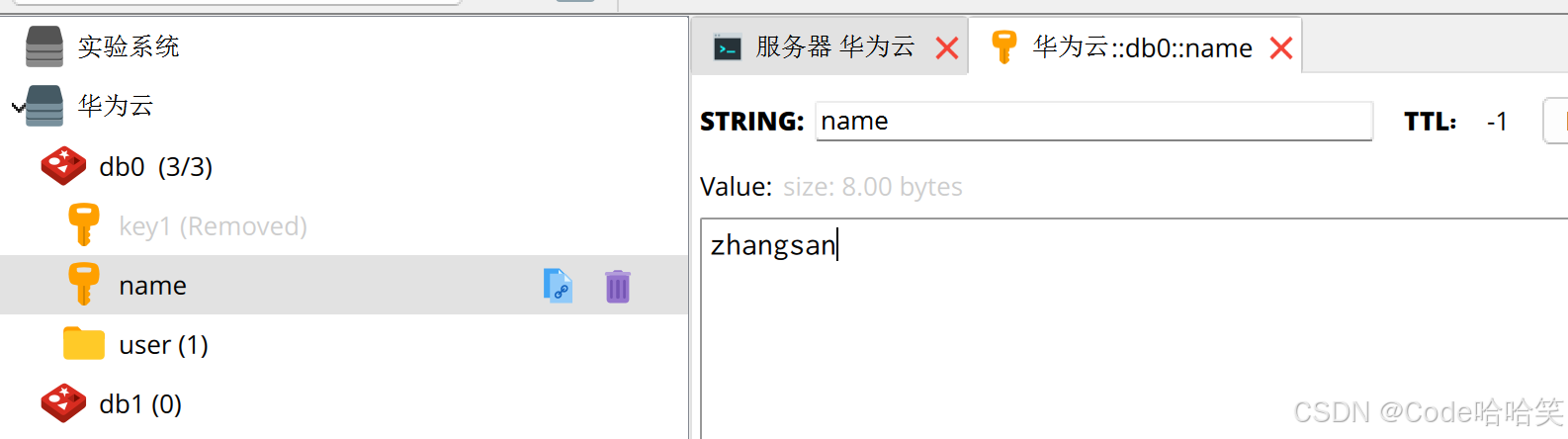
结果2:
2.1.2 核心类与对象
jedis:核心客户端类,封装了所有 redis 命令
构造方法:jedis(string host, int port) 初始化连接
常用方法:
set(string key, string value):存储字符串get(string key):获取字符串hset(string key, string field, string value):存储 hash 字段hgetall(string key):获取 hash 所有字段
@beforeeach/@aftereach:junit5 生命周期注解,分别用于初始化和销毁资源
2.1.3 原理分析
连接过程:
- 创建 jedis 实例时建立 tcp 连接(三次握手)
- 通过 auth 命令进行密码验证(如果配置了密码)
- select 命令选择操作的数据库(默认 0 号库)
命令执行:
- 客户端将命令序列化为字节流发送到 redis 服务器
- 服务器执行命令后返回结果,客户端解析响应
2.1.4 优缺点
- 优点:简单直观,适合学习和小规模测试
- 缺点:
- 每次测试都创建新连接,性能低下(tcp 连接创建开销大)
- 并发场景下可能导致连接风暴
- 没有连接复用机制,资源利用率低
2.2 jedis 连接池(池化连接)
2.2.1 连接池配置类
public class jedisconnectionfactory {
private static final jedispool jedispool;
static{
jedispoolconfig jedispoolconfig = new jedispoolconfig();
//最大连接
jedispoolconfig.setmaxtotal(10);
//最大空闲连接
jedispoolconfig.setmaxidle(10);
//最小空闲连接
jedispoolconfig.setminidle(5);
//设置最长等待时间
jedispoolconfig.setmaxwaitmillis(200);
jedispool = new jedispool(jedispoolconfig,"x.x.x.x",6379,
1000,"xxxx");
}
//获取jedis对象
public static jedis getjedis(){
return jedispool.getresource();
}
}
说明:
jedispool:连接池核心类,管理连接的创建和回收
getresource():从连接池获取可用连接(可能从空闲队列获取或新建)
jedispoolconfig:连接池配置类,常用参数:
maxtotal:最大连接数(控制并发量)maxidle:最大空闲连接数(避免空闲连接过多)minidle:最小空闲连接数(保证基础可用连接)
maxwaitmillis:获取连接超时时间(避免无限阻塞)
2.2.2 连接池工作原理
初始化阶段:
- 启动时创建
minidle数量的空闲连接
获取连接:
- 优先从空闲队列中获取连接
- 若空闲队列为空,且当前连接数小于
maxtotal,则新建连接 - 若连接数已达
maxtotal,则等待maxwaitmillis时间
归还连接:
- 调用
close()方法时,连接不会真正关闭,而是放回空闲队列 - 空闲连接数超过
maxidle时,多余连接会被销毁
2.2.3 使用示例
@slf4j
@springboottest
public class jedispool {
private jedis jedis;
@beforeeach
public void setup(){
//建立连接
jedis = jedisconnectionfactory.getjedis();
//设置密码
jedis.auth("dhj20030916.");
//选择库
jedis.select(0);
}
@test
public void teststring(){
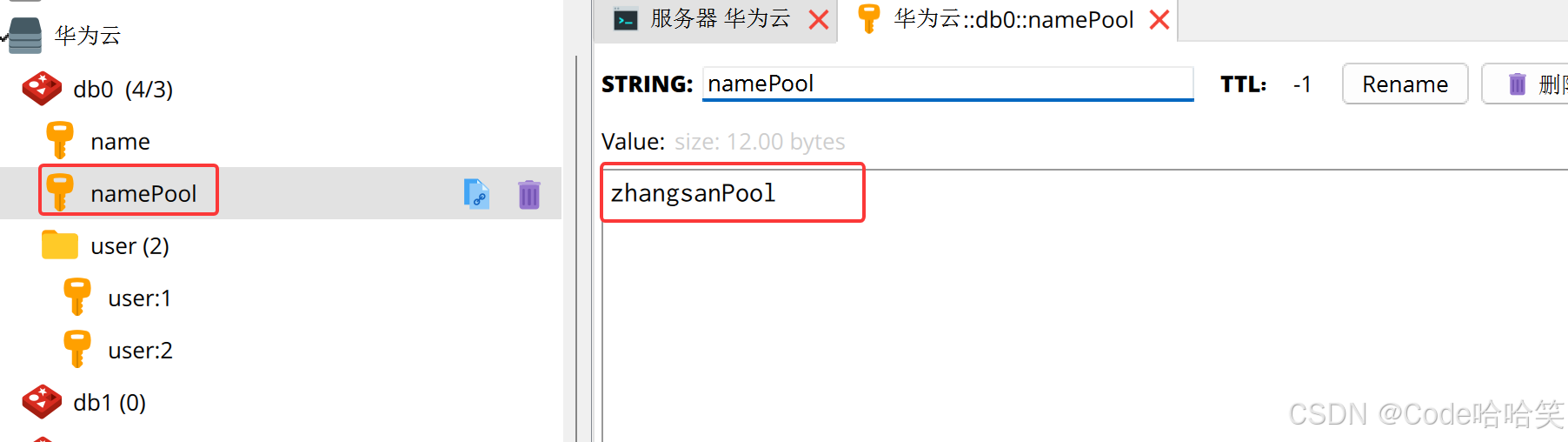
jedis.set("name","zhangsan");
string value = jedis.get("name");
log.info("value:"+value);
}
@test
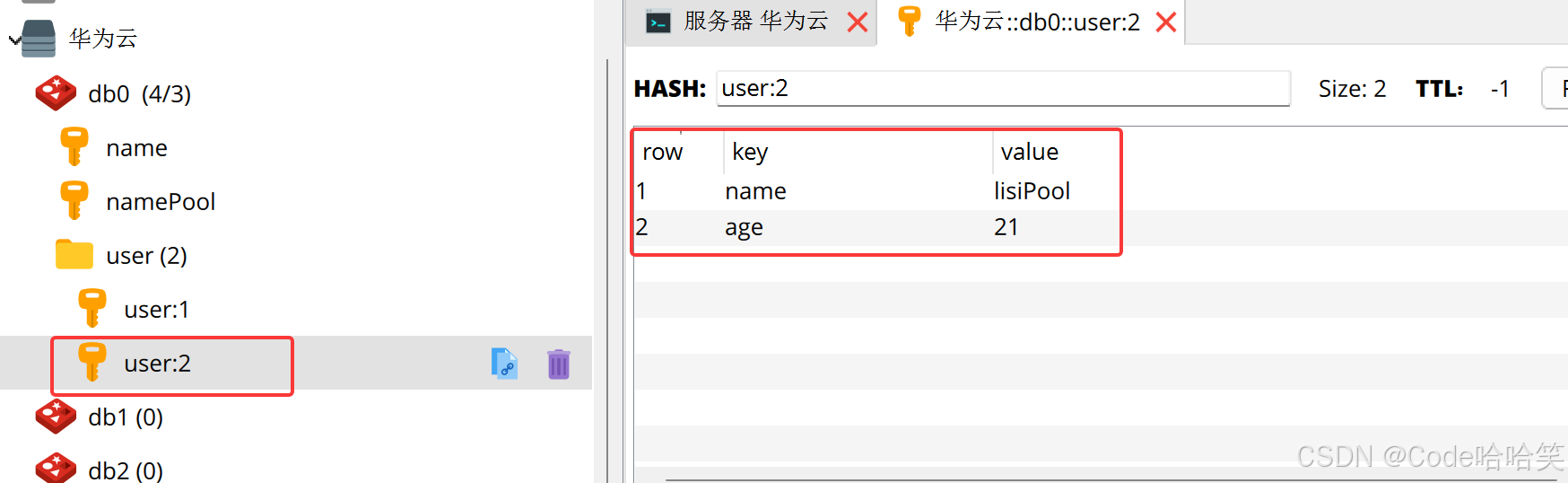
public void testhash(){
jedis.hset("user:1","name","lisi");
jedis.hset("user:1","age","21");
map<string,string> map = jedis.hgetall("user:1");
log.info("map:"+ map.tostring());
}
@aftereach
public void teardown(){
if(jedis != null){
jedis.close();
}
}
}
运行结果:
结果1:
结果2:
2.2.4 优势对比
| 特性 | 直接连接 | 连接池方式 |
|---|---|---|
| 连接创建 | 每次新建 | 复用已有连接 |
| 并发支持 | 差 | 好(控制连接数) |
| 资源利用率 | 低 | 高 |
| 性能 | 差(连接开销) | 好(减少握手) |
| 适用场景 | 单线程测试 | 高并发生产环境 |
3. spring data redis:高层抽象与模板化操作
3.1 核心依赖与配置
3.1.1 maven 依赖
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-data-redis</artifactid>
</dependency>
3.1.2 yaml 配置
spring:
redis:
host: x.x.x.x
port: 6379
password: xxxx
lettuce:
pool:
max-active: 10 #最大连接
max-idle: 10 #最大空闲连接
min-idle: 0 #最小空闲连接
max-wait: 100 #连接等待时间
3.2 redistemplate 核心类解析
3.2.1 基础操作示例
@springboottest
@slf4j
public class redistem {
@autowired
private redistemplate redistemplate;
@test
public void test(){
//插入一条string类型的数据
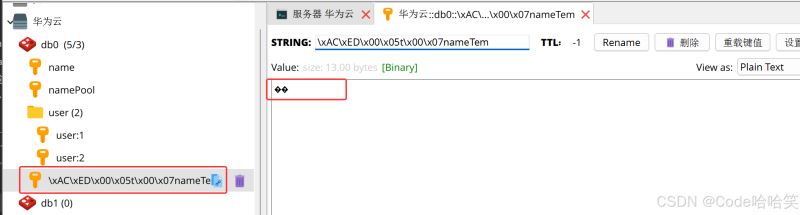
redistemplate.opsforvalue().set("nametem","赵六");
object s = redistemplate.opsforvalue().get("nametem");
log.info("nametem:"+ s);
}
}
运行结果:
3.2.2 核心类结构
redistemplate:
泛型参数:<k, v> 分别表示键和值的类型
核心方法:
opsforvalue():获取字符串操作对象(对应 string 类型)opsforhash():获取 hash 操作对象(对应 hash 类型)opsforlist():获取列表操作对象(对应 list 类型)opsforset():获取集合操作对象(对应 set 类型)opsforzset():获取有序集合操作对象(对应 sorted set 类型)
redisconnectionfactory:
- 连接工厂接口,支持 jedis/lettuce 等多种实现
- spring 自动根据依赖加载对应的实现(如引入 jedis 依赖则使用 jedisconnectionfactory)
3.3 序列化机制详解
3.3.1 默认序列化问题
spring data redis 默认使用jdkserializationredisserializer:
- 序列化后数据冗余(包含类名、版本号等信息)
- 依赖类必须实现
serializable接口 - 跨语言不兼容(如 python 无法解析 jdk 序列化数据)
3.3.2 json 序列化配置
@configuration
public class redisconfig {
@bean
public redistemplate<string, object> redistemplate(redisconnectionfactory connectionfactory) {
// 创建redistemplate对象
redistemplate<string, object> redistemplate = new redistemplate<>();
//设置连接工厂
redistemplate.setconnectionfactory(connectionfactory);
// 创建json序列化工具
genericjackson2jsonredisserializer jsonredisserializer = new genericjackson2jsonredisserializer();
//设置key的序列化
redistemplate.setkeyserializer(redisserializer.string());
redistemplate.sethashkeyserializer(redisserializer.string());
//设置value的序列化
redistemplate.setvalueserializer(jsonredisserializer);
redistemplate.sethashvalueserializer(jsonredisserializer);
return redistemplate;
}
}
3.3.3 序列化流程
存储数据:
- 值对象(如 user 对象)通过 json 序列化工具转为 json 字符串
- 键和 hash 键通过 string 序列化转为字节数组
读取数据:
- 从 redis 获取字节数组后,键反序列化为 string
- 值反序列化为对应的对象(通过 jackson 的类型推断)
3.4 对象存储实战(序列化配置后)
3.4.1 user 实体类
@data
public class user {
private integer id;
private string name;
private integer age;
}
3.4.2 测试代码
@springboottest
@slf4j
public class redistemser {
@autowired
private redistemplate redistemplate;
@test
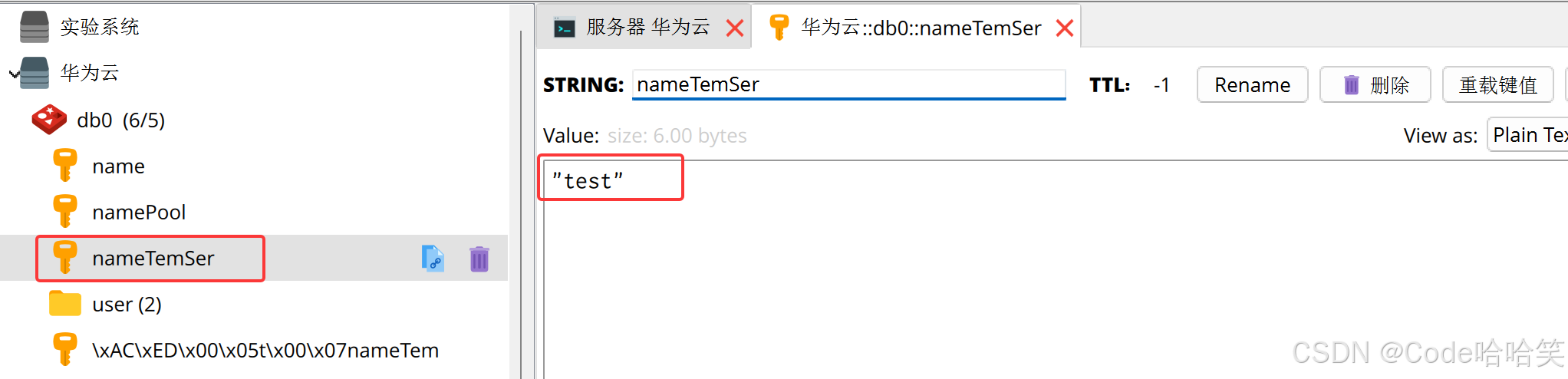
public void teststring(){
redistemplate.opsforvalue().set("nametemser","test");
string value = (string)redistemplate.opsforvalue().get("nametemser");
log.info("value"+ value);
}
@test
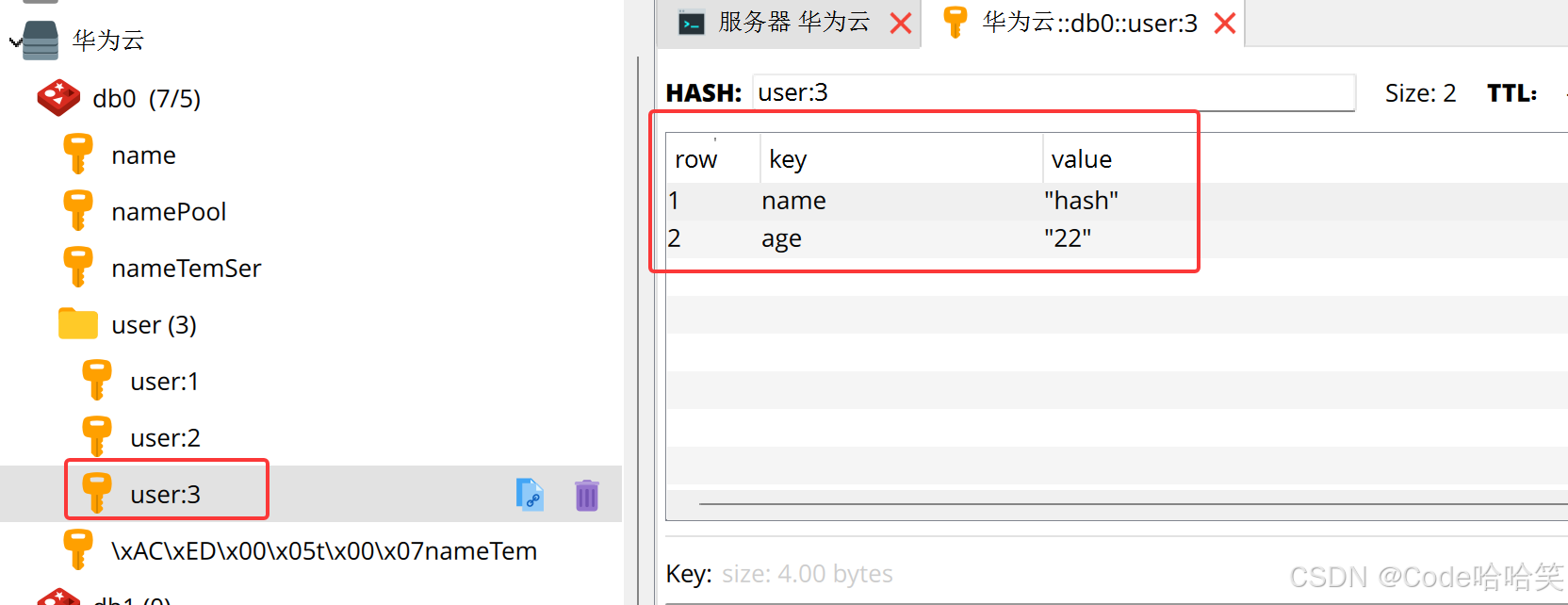
public void testhash(){
redistemplate.opsforhash().put("user:3","name","hash");
redistemplate.opsforhash().put("user:3","age","22");
map<string,object> map = (map<string,object>)redistemplate.opsforhash().entries("user:3");
log.info("map"+ map);
}
@test
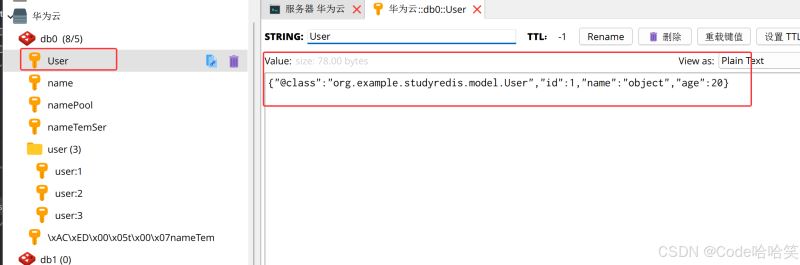
public void testobject(){
user user = new user();
user.setid(1);
user.setname("object");
user.setage(20);
redistemplate.opsforvalue().set("user",user);
object object = redistemplate.opsforvalue().get("user");
log.info("object"+ object);
}
}
运行结果:
结果1:
结果2:
结果3:
3.4.3 关键细节
类型转换:
opsforvalue().set(key, value)支持任意对象,内部自动序列化opsforvalue().get(key)返回 object 类型,需手动强转(依赖序列化配置)
hash 操作:
opsforhash().put(key, field, value)存储 hash 字段,value 自动序列化entries()方法返回 map<string, object>,字段值已反序列化
4. stringredistemplate:专注字符串场景
4.1 基本概念
stringredistemplate 是 redistemplate<string, string> 的子类
默认配置:
- 键序列化:
stringredisserializer(等同于redisserializer.string()) - 值序列化:
stringredisserializer(直接存储字符串)
4.2 对象操作实战
4.2.1 测试代码
@slf4j
@springboottest
public class stringredistem {
@autowired
private stringredistemplate stringredistemplate;
private static final objectmapper mapper = new objectmapper();
@test
public void testobject() throws jsonprocessingexception {
user user = new user();
user.setid(2);
user.setname("stringredistem");
user.setage(20);
// 手动序列化value
string json = mapper.writevalueasstring(user);
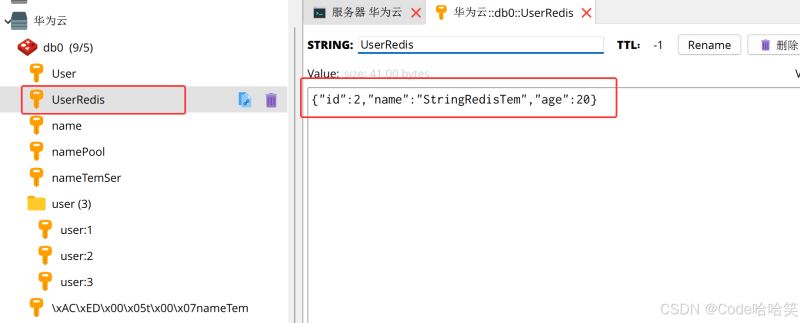
stringredistemplate.opsforvalue().set("userredis", json);
// 获取数据
string val = stringredistemplate.opsforvalue().get("userredis");
// 手动反序列化
user uservalue = mapper.readvalue(val,user.class);
log.info(uservalue.tostring());
}
}
运行结果:
4.2.2 核心步骤解析
序列化:
- 使用 jackson 的
objectmapper将 user 对象转为 json 字符串 - 解决
stringredistemplate只能存储字符串的限制
存储与获取:
opsforvalue().set(key, value)直接存储字符串opsforvalue().get(key)直接获取字符串
反序列化:
- 将获取的 json 字符串转为 user 对象
- 需要处理可能的
jsonprocessingexception异常
4.3 与 redistemplate 的对比
| 特性 | redistemplate | stringredistemplate |
|---|---|---|
| 泛型参数 | <k, v> 任意类型 | <string, string> |
| 序列化 | 支持自定义序列化 | 固定 string 序列化 |
| 对象操作 | 自动序列化 / 反序列化 | 需手动序列化 / 反序列化 |
| 键类型 | 任意类型(需序列化) | 只能是 string 类型 |
| 适用场景 | 复杂数据类型(对象、hash 等) | 纯字符串场景(如缓存文本) |
5. 连接方式深度对比与选型建议
5.1 技术维度对比
| 维度 | jedis 直接连接 | jedis 连接池 | redistemplate | stringredistemplate |
|---|---|---|---|---|
| 连接管理 | 手动创建 | 连接池管理 | 框架管理 | 框架管理 |
| 序列化支持 | 无(需手动) | 无 | 支持自定义 | 仅 string 序列化 |
| spring 集成 | 弱 | 弱 | 强(自动装配) | 强(自动装配) |
| 学习成本 | 低 | 中 | 中 | 低 |
| 并发性能 | 差 | 优 | 优 | 优 |
5.2 场景化选型建议
5.2.1 学习阶段
推荐使用 jedis 直接连接:
- 代码简单,便于理解 redis 基本操作
- 适合单个命令测试(如 get/set/hset 等)
5.2.2 小型项目(非 spring)
推荐 jedis 连接池:
- 避免频繁创建连接,提升性能
- 手动管理连接,适合轻量级项目
5.2.3 spring boot 项目
优先使用 redistemplate:
- 与 spring 生态无缝集成(依赖注入、配置管理)
- 支持复杂数据类型和自定义序列化
- 推荐配置 json 序列化,兼容对象存储
5.2.4 纯字符串场景
使用 stringredistemplate:
- 简化字符串操作(避免泛型转换)
- 性能略优(减少序列化层开销)
5.3 生产环境最佳实践
连接池配置:
maxtotal设置为系统并发量的 1.5-2 倍maxwaitmillis不超过 200ms(避免过长阻塞)minidle设置为 5-10(保证基础连接可用性)
序列化选择:
- 统一使用 json 序列化(
genericjackson2jsonredisserializer) - 键使用 string 序列化(保证可读性和可维护性)
异常处理:
- 添加
try-catch-finally块,确保连接归还 - 处理
jedisconnectionexception等网络异常
监控与调优:
- 监控连接池的空闲连接数、活跃连接数
- 使用 redis 的
info connection命令查看服务器连接状态
6. 常见问题与解决方案
6.1 连接失败问题
现象:
- 抛出
jedisconnectionexception: ``java.net``.connectexception: connection refused
可能原因:
- redis 服务器未启动
- ip 地址或端口错误(检查配置中的 host 和 port)
- 防火墙阻止连接(需开放 6379 端口)
- redis 密码错误(auth 命令失败)
解决方案:
- 确保 redis 服务器正常运行(
redis-cli ping检查连通性) - 核对配置中的连接参数(ip、端口、密码)
- 检查服务器防火墙设置(如 linux 的
firewall-cmd)
6.2 数据乱码问题
现象:
redis 存储的字符串在 java 中获取时出现乱码
可能原因:
- 未正确设置字符编码(jedis 默认使用 utf-8)
- 序列化方式不匹配(如 redistemplate 使用 jdk 序列化,手动使用字符串读取)
解决方案:
jedis 中指定编码:
jedis.get("key", standardcharsets.utf\_8); // 显式指定编码redistemplate 统一使用 string 序列化:
template.setkeyserializer(redisserializer.string());
6.3 对象反序列化失败
现象:
- 从 redis 获取对象时抛出
classnotfoundexception
可能原因:
- 使用 jdk 序列化时,类路径不一致(如部署环境类缺失)
- json 序列化时,对象缺少无参构造函数(jackson 需要)
解决方案:
- 改用 json 序列化(避免类路径问题)
- 确保实体类包含无参构造函数(lombok 的
@data默认生成)
7. 扩展知识:异步客户端 lettuce
7.1 lettuce 简介
- 基于 netty 的异步非阻塞客户端
- 支持响应式编程(reactor 模式)
- 适合高并发、高吞吐量场景
7.2 核心差异
| 特性 | jedis | lettuce |
|---|---|---|
| io 模型 | 同步阻塞 | 异步非阻塞 |
| 连接方式 | 每个线程一个连接 | 单个连接处理多个请求 |
| 线程安全 | 非线程安全 | 线程安全 |
| 适用场景 | 简单同步场景 | 异步 / 反应式场景 |
7.3 配置示例
spring:
redis:
host: 1.94.22.150
port: 6379
password: dhj20030916.
lettuce:
pool:
max-active: 10 #最大连接
max-idle: 10 #最大空闲连接
min-idle: 0 #最小空闲连接
max-wait: 100 #连接等待时间
8. 总结:从入门到实战的成长路径
8.1 学习阶段建议
- 基础操作:掌握 jedis 直接连接,理解 redis 基本命令(set/get/hset 等)
- 性能优化:学习连接池原理,掌握 jedispool 配置与使用
- 框架集成:深入 spring data redis,学会配置 redistemplate 和序列化
- 实战提升:在项目中应用缓存、分布式锁等场景,处理实际问题
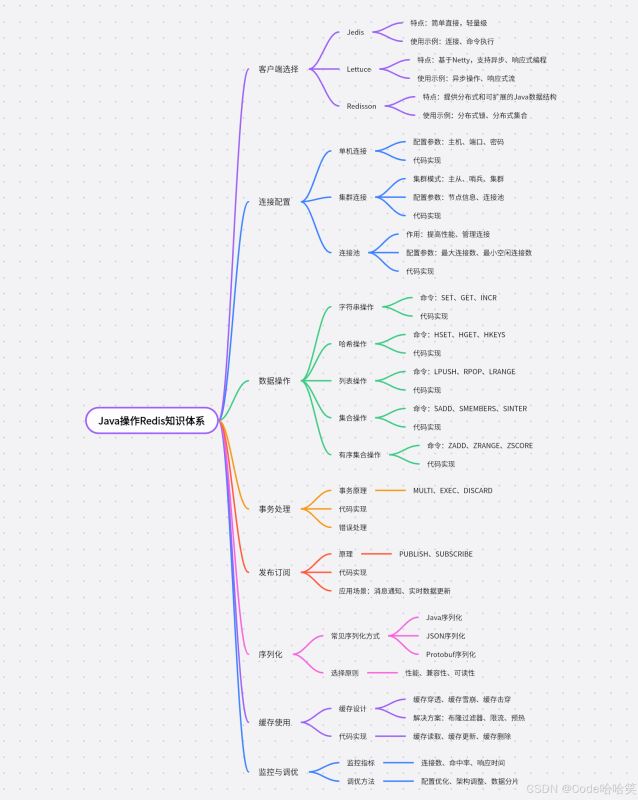
8.2 核心知识图谱
8.3 结语
通过本文的系统学习,读者应能熟练掌握 java 操作 redis 的主流方式,理解不同连接方式的适用场景和底层原理,并能够在实际项目中根据需求选择合适的技术方案。记住,实践是最好的老师,建议通过实际项目练习加深理解,遇到问题时结合官方文档和源码进行分析,逐步提升 redis 开发与运维能力。
以上就是java连接并操作redis超详细教程的详细内容,更多关于java连接并操作redis的资料请关注代码网其它相关文章!





发表评论