dubbo中spi机制的实现原理和优势
确保系统的扩展性是我们开展架构设计工作的核心目标之一。实现扩展性的方法有很多,jdk 本身内置了一个 spi(service provider interface,服务提供者接口)机制,来帮开发人员动态加载各种不同的实现类,只要这些实现类遵循一定的开发规范即可。
另一方面,jdk 自带的 spi 机制存在一定的缺陷,因此市面上有些框架对 jdk 中的 spi 机制做了一些增强,这方面的代表性框架就是 dubbo。
jdk 中的 spi 机制解析
如果我们采用 jdk 中的 spi,具体的开发工作会涉及三个步骤。

对于 spi 的开发者而言,我们需要设计一个服务接口,然后根据业务场景提供不同的实现类,这是第一步。
接下来的第二步是关键,我们需要创建一个以服务接口命名的配置文件,并把这个文件放置到代码工程的 meta-inf/services 目录下。请注意,在这个配置文件中,我们需要指定服务接口对应实现类的完整类名。通过这一步,我们可以得到了一个包含 spi 类和配置的 jar 包。
最后,spi 的使用者就可以加载这个 jar 包并找到其中的这个配置文件,并根据所配置的实现类完整类名对这些类进行实例化。
上图中的后面两个步骤实际上都是为了遵循 jdk 中 spi 的实现机制而进行的配置工作。
为了实现对 spi 实现类的动态记载,jdk 专门提供了一个 serviceloader 工具类,这个工具类的使用方法如下所示:
public static void main(string[] args) {
serviceloader<logprovider> loader = serviceloader.load(logprovider.class);
for (logprovider provider : loader) {
system.out.println(provider.getclass());
provider.info(“testinfo”);
}
}
这里有一个 logprovider 接口,并通过 serviceloader 的 load 方法将这个接口所配置的实现类加载到内存中,从而可以方便地使用这些 spi 实现类所提供的功能。
接下来,让我们来分析一下这个 serviceloader 工具类的实现原理。
serviceloader 本身实现了 jdk 中的 iterable 接口,因此在上面的代码示例中,通过 serviceloader.load 方法我们获取的是一个迭代器,而底层则用到了 serviceloader.lazyiterator 这个迭代器类。
从命名上看,lazyiterator 是一个具备延迟加载机制的迭代器,它有 hasnextservice 和 nexservicet 这两个核心方法。我们先来看 hasnextservice 方法:
//配置文件路径
static final string prefix = "meta-inf/services/";
private boolean hasnextservice() {
if (nextname != null) {
return true;
}
if (configs == null) {
// 通过 prefix 前缀与服务接口的名称,我们可以找到目标 spi 配置文件
string fullname = prefix + service.getname();
// 加载配置文件
if (loader == null)
configs = classloader.getsystemresources(fullname);
else
configs = loader.getresources(fullname);
}
// 对 spi 配置文件进行遍历,并解析配置内容
while ((pending == null) || !pending.hasnext()) {
if (!configs.hasmoreelements()) {
return false;
}
// 解析配置文件
pending = parse(service, configs.nextelement());
}
// 更新 nextname 字段
nextname = pending.next();
return true;
}
可以看到,hasnextservice 方法的核心作用是找到并解析配置文件。而接下来要展开的 nextservice 方法则负责对所配置的类进行实例化,核心实现如下所示:
private s nextservice() {
string cn = nextname;
nextname = null;
// 加载 nextname 字段指定的类
class<?> c = class.forname(cn, false, loader);
// 检测类型
if (!service.isassignablefrom(c)) {
fail(service, "provider " + cn + " not a subtype");
}
// 创建实现类的对象
s p = service.cast(c.newinstance());
// 缓存已创建的对象
providers.put(cn, p);
return p;
}
这里通过 newinstance 方法创建了目标实例,并将已创建的实例对象放到 providers 集合中进行缓存,从而提高访问效率。
dubbo 中的 spi 机制解析
为了实现框架自身的扩展性,dubbo 也采用了类似 jdk 中 spi 的设计思想,但提供了一套新的实现方式,并添加了一些扩展功能。
dubbo 中与 spi 机制相关的注解主要包括@spi、@adaptive 和@activate,其中@spi 注解提供了与 jdk 中 spi 类似的功能。
这三个注解的应用场景各不相同,其中@spi 注解为 dubbo 提供了最基础的 spi 机制,而@adaptive 和@activate 注解都是构建在这个注解之上,因此我们重点介绍@spi 注解。如果在某个接口上添加了这个注解,那么 dubbo 在运行过程中就会去查找接口对应的扩展点实现。
在 dubbo 中,随处可以看到@spi 注解的应用场景。
举个例子,protocol 接口定义如下:
@spi("dubbo")public interface protocol可以看到,在这个接口上使用的就是@spi(“dubbo”) 注解。
请注意,在@spi 注解中可以指定默认扩展点的名称,例如这里的“dubbo”用来表明在 protocol 接口的所有实现类中,dubboprotocol 是它的默认实现。
有了 spi 的定义,我们接下来看一看 dubbo 中 spi 配置信息的存储方式。我们已经知道,jdk 只会把 spi 配置存放在 meta-inf/services/这个目录下,而 dubbo 则提供了三个类似这样的目录:
作为示例,我们继续围绕上面提到的 protocol 接口展开讨论。
针对 protocol 接口,dubbo 提供了 grpcprotocol、dubboprotocol 等多个实现类,并通过 spi 机制完成对具体某种实现方案的加载过程。
让我们分别来到提供这些实现类的代码工程 dubbo-rpc-grpc 和 dubbo-rpc-dubbo,会发现在 meta-inf/dubbo/internal/目录下都包含了一个 com.apache.dubbo.rpc.protocol 配置文件。其中,dubbo-rpc-grpc 工程的代码结构如图所示:

类似的,dubbo-rpc-dubbo 工程的代码结构如下图所示:
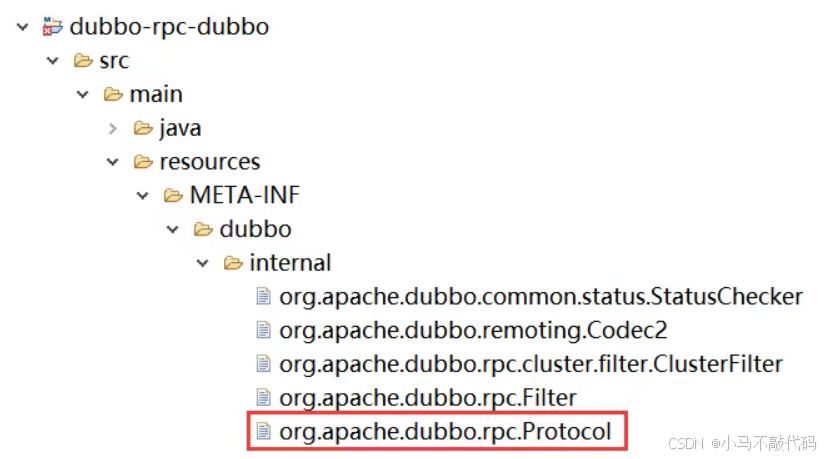
我们分别打开这两个工程的 com.apache.dubbo.rpc.protocol 配置文件,可以发现它们分别指向了 org.apache.dubbo.rpc.protocol.grpc.grpcprotocol 和 org.apache.dubbo.rpc.protocol.dubbo.dubboprotocol 类。
- //dubbo-rpc-grpc 工程:
grpc=org.apache.dubbo.rpc.protocol.grpc.grpcprotocol
- //dubbo-rpc-dubbo 工程:
dubbo=org.apache.dubbo.rpc.protocol.dubbo.dubboprotocol
当 dubbo 在引用具体某一个代码工程时,就可以通过这个工程中的配置项就可以找到 dubbo 接口对应的扩展点实现。
同时,我们从上面配置项中也可以看出,dubbo 中采用的定义方式与 jdk 中的不一样。dubbo 使用的一个 key 值(如上面的 grpc 和 dubbo)来指定具体的配置项名称,而不是采用完整类路径。
介绍完@spi 注解,我们接下来看 dubbo 中的 extensionloader 类,这个类扮演着与 jdk 中 serviceloader 工具类相同的角色。
extensionloader 是实现扩展点加载的核心类,如果我们想要获取 dubboprotocol 这个实现类,那么可以采用以下方式:
dubboprotocol dubboprotocol = extensionloader.getextensionloader(protocol.class).getextension(dubboprotocol.name);
我们来看一下这里 getextension 方法的细节,这个方法代码如下所示:
public t getextension(string name) {
...
//从缓存中获取目标对象
holder<object> holder = cachedinstances.get(name);
if (holder == null) {
//将目标对象放到缓存中
cachedinstances.putifabsent(name, new holder<object>());
holder = cachedinstances.get(name);
}
object instance = holder.get();
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
//创建目标对象
instance = createextension(name);
holder.set(instance);
}
}
}
return (t) instance;
}
我们看到这里同样用到了缓存机制。这个方法会首先检查缓存中是否已经存在扩展点实例,如果没有则通过 createextension 方法进行创建。
我们一路跟踪 createextension 方法,终于看到了熟悉的 spi 机制,如下所示:
private map<string, class<?>> loadextensionclasses() {
final spi defaultannotation = type.getannotation(spi.class);
if (defaultannotation != null) {
//确定缓存名称
}
map<string, class<?>> extensionclasses = new hashmap<string, class<?>>();
//分别从三个目录中加载类实例
loadfile(extensionclasses, dubbo_internal_directory);
loadfile(extensionclasses, dubbo_directory);
loadfile(extensionclasses, services_directory);
return extensionclasses;
}
在这里,我们调用了三次 loadfile 方法,分别在 meta-inf/dubbo/、meta-inf/services/和 meta-inf/dubbo/internal/这三个目录中加载扩展点。在 loadfile 方法中,dubbo 是直接通过 class.forname 的形式加载这些 spi 的扩展类,并进行缓存。
到这里,我们发现,为了提升实例类的加载速度,dubbo 和 jdk 都采用了缓存机制,这是它们的一个共同点。但实际上,我们也已经可以梳理 dubbo 中 spi 机制与 jdk 中 spi 机制的区别,核心有两点,就是 配置文件位置和 获取实现类的条件。
从加载 spi 实例的配置文件位置来看,dubbo 支持更多的加载路径。jdk 只能加载一个固定的 meta-inf/services,而 dubbo 有三个路径。
就获取实现类的条件而言,dubbo 采用的是直接通过名称对应的 key 值来定位具体实现类,而 serviceloader 内部使用的是一个迭代器,在获取目标接口的实现类时,只能通过遍历的方式把配置文件中的类全部加载并实例化,显然这样效率比较低下。
简单来说,dubbo 没有直接沿用 jdk spi 机制,而是自己实现一套的主要目的就是克服这种效率低下的情况,并提供了更多的灵活性。
总结
从 dubbo 配置项的定义中发现,dubbo 采用了与 jdk 不同的实现机制。虽然 dubbo 也采用了 spi 机制,也是从 jar 包中动态加载实现类,但它的实现方式与 jdk 中基于 serviceloader 是不一样的。于是,详细分析了 jdk 和 dubbo 在 spi 机制设计和实现上的差异,并阐明了 dubbo 内部的实现原理和所具备的优势。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。






发表评论