1. 重复数据插入问题分析
1.1 问题本质
在 mysql 中,当我们使用主键或唯一索引来确保数据唯一性时,如果插入重复数据,mysql 会抛出类似这样的异常:
java.sql.sqlintegrityconstraintviolationexception: duplicate entry 'xxx' for key 'xxx'
这个异常本质上是数据库告诉我们:"兄 dei,这条数据已经存在了,别再塞了!"
唯一键定义:唯一键可以是主键或唯一索引,二者在触发唯一性约束时行为一致。主键是特殊的唯一索引,区别在于主键不允许 null 值且一个表只能有一个主键,而唯一索引则可以有多个且允许 null 值。需注意,对于普通唯一索引,mysql 将多个 null 视为不同值,因此可以插入多条 null 唯一键的记录;而主键则完全不允许 null。选择约束类型时应考虑字段是否允许为 null 的业务需求。
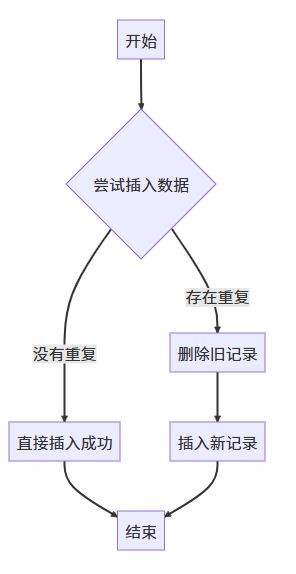
1.2 常见场景图

2. 基础解决方案:使用异常捕获
最基础的方案是使用 try-catch 捕获异常,代码如下:
public void insertuser(user user) {
try {
usermapper.insert(user);
log.info("用户数据插入成功");
} catch (org.springframework.dao.duplicatekeyexception e) {
// spring框架对sqlintegrityconstraintviolationexception的封装
log.warn("用户数据已存在: {}", user.getusername());
// 可以选择忽略或更新现有数据
} catch (java.sql.sqlintegrityconstraintviolationexception e) {
// 使用jdbc直接操作时可能遇到的原生异常
log.warn("用户数据已存在(jdbc原生异常): {}", user.getusername());
// 同样可以处理重复数据
}
}
这种方法的缺点是:每次遇到重复数据都会产生一个异常,异常的创建和捕获会带来额外的性能开销,尤其在批量操作时性能损耗更明显。
3. 改进方案:预检查+条件插入
一个改进思路是先检查数据是否存在,再决定插入或更新:
public void insertuserwithcheck(user user) {
user existinguser = usermapper.selectbyusername(user.getusername());
if (existinguser == null) {
usermapper.insert(user);
} else {
// 处理重复数据,比如更新或忽略
}
}
这种方案的核心价值是减少数据库异常抛出,而非保证数据唯一性。在并发环境下存在竞态条件:检查和插入是两个独立操作,中间可能有其他事务插入相同数据。
解决竞态条件的正确方式:
- 必须结合数据库唯一索引作为兜底保障
- 即使发生并发冲突,最终由数据库约束保证数据唯一性
- 应用层做好异常捕获处理,保证业务流程正常进行
在高并发场景下,可以考虑使用分布式锁进一步控制并发问题,增加续租机制确保业务完成前锁不会释放:
@transactional(rollbackfor = exception.class)
public void insertuserwithlock(user user) {
// 获取分布式锁(采用redisson实现自动续租)
string lockkey = "user_register:" + user.getusername();
rlock lock = redissonclient.getlock(lockkey);
try {
// 尝试获取锁,设置自动续租(看门狗机制)
boolean locked = lock.trylock(5, 30, timeunit.seconds);
if (locked) {
user existinguser = usermapper.selectbyusername(user.getusername());
if (existinguser == null) {
usermapper.insert(user);
} else {
// 处理重复数据
}
} else {
throw new businessexception("操作频繁,请稍后重试");
}
} catch (interruptedexception e) {
thread.currentthread().interrupt();
throw new businessexception("操作被中断");
} finally {
// 确保锁释放
if (lock.isheldbycurrentthread()) {
lock.unlock();
}
}
}
4. 高效解决方案
4.1 insert ignore 语句
mysql 提供了 insert ignore 语句,当遇到重复数据时会自动忽略错误:
@insert("insert ignore into user(username, email, password) values(#{username}, #{email}, #{password})")
int insertignore(user user);
执行流程如下:

注意:受影响的行数是实际成功插入的行数,被忽略的行不计入受影响的行数。这点在批量操作时尤为重要,返回值只反映实际插入的记录数,而非处理的总记录数。
4.2 on duplicate key update 语句
如果需要在遇到重复时更新数据,可以使用 on duplicate key update:
@insert("insert into user(username, email, password, login_count) " +
"values(#{username}, #{email}, #{password}, #{logincount}) " +
"on duplicate key update " +
"email = if(email = values(email), email, values(email)), " + // 仅当值变化时更新,避免无谓更新
"login_count = login_count + 1") // 累加操作必然更新
int insertorupdatelogincount(user user);
这条语句会在遇到重复主键或唯一索引时,执行 update 操作而不是插入。
注意:使用if(字段 = values(字段), 字段, values(字段))可以避免"静默更新"问题——当新值与旧值相同时,mysql 不会真正执行更新操作,受影响的行数为 0。这种写法确保只有在值真正变化时才更新。
受影响的行数意义:
- 1: 新插入记录或更新了已有记录(值发生变化)
- 0: 行被更新但值未变化
- 2: 合并了多个唯一索引冲突的记录(较少见)
4.3 replace into 语句
replace into 是另一种处理方式,它会先尝试插入数据,如果出现重复则删除旧记录,再插入新记录:
@insert("replace into user(id, username, email, password) values(#{id}, #{username}, #{email}, #{password})")
int replaceuser(user user);
执行过程:
重要风险提示:
- 如果表存在外键约束,删除旧记录可能触发级联删除,导致关联数据丢失
- 使用自增主键时,每次 replace 都会生成新的主键值,导致主键值跳跃
- 大量使用 replace 会导致更频繁的行删除再插入,增加表碎片和锁竞争
适用场景:无外键依赖、无需保留历史版本、完全覆盖旧数据的场景。
5. 批量处理优化
对于批量数据处理,逐条插入效率低下。下面是更安全的批量插入方案(避免 sql 注入风险):
@mapper
public interface usermapper {
@insert("<script>" +
"insert into user(username, email, password) values " +
"<foreach collection='users' item='user' separator=','>" +
"(#{user.username}, #{user.email}, #{user.password})" +
"</foreach>" +
" on duplicate key update " +
"email = values(email), " +
"password = values(password)" +
"</script>")
int batchinsertorupdate(@param("users") list<user> users);
@insert("<script>" +
"insert ignore into user(username, email, password) values " +
"<foreach collection='users' item='user' separator=','>" +
"(#{user.username}, #{user.email}, #{user.password})" +
"</foreach>" +
"</script>")
int batchinsertignore(@param("users") list<user> users);
}
使用 jdbctemplate 时也要注意避免 sql 注入:
public int batchinsertwithjdbctemplate(list<user> users) {
string sql = "insert into user(username, email, password) values (?, ?, ?) " +
"on duplicate key update email = values(email)";
return jdbctemplate.batchupdate(sql, new batchpreparedstatementsetter() {
@override
public void setvalues(preparedstatement ps, int i) throws sqlexception {
user user = users.get(i);
ps.setstring(1, user.getusername());
ps.setstring(2, user.getemail());
ps.setstring(3, user.getpassword());
}
@override
public int getbatchsize() {
return users.size();
}
}).length;
}
6. spring boot 整合方案
在 spring boot 项目中,我们可以结合 mybatis 实现更优雅的解决方案:
@service
public class userservice {
@autowired
private usermapper usermapper;
/**
* 插入用户数据,遇到重复则更新
*/
@transactional(rollbackfor = exception.class)
public boolean insertorupdateuser(user user) {
return usermapper.insertorupdate(user) > 0;
}
/**
* 批量插入用户数据,忽略重复
*/
@transactional(rollbackfor = exception.class)
public int batchinsertignore(list<user> users) {
if (collectionutils.isempty(users)) {
return 0;
}
// 大批量数据,分批处理避免事务过大
int batchsize = 500; // 根据实际数据大小和数据库配置调整
int totalinserted = 0;
for (int i = 0; i < users.size(); i += batchsize) {
list<user> batch = users.sublist(i, math.min(users.size(), i + batchsize));
totalinserted += usermapper.batchinsertignore(batch);
}
return totalinserted;
}
}
// usermapper接口
public interface usermapper {
@insert("insert into user(username, email, password) " +
"values(#{username}, #{email}, #{password}) " +
"on duplicate key update " +
"email = values(email), password = values(password)")
int insertorupdate(user user);
@insert("<script>insert ignore into user(username, email, password) values " +
"<foreach collection='list' item='user' separator=','>" +
"(#{user.username}, #{user.email}, #{user.password})" +
"</foreach></script>")
int batchinsertignore(@param("list") list<user> users);
}
7. 实用异常处理封装
为了使代码更健壮,我们可以封装一个通用的异常处理工具:
public class mysqlexceptionhelper {
// mysql错误码常量
public static final int er_dup_entry = 1062; // 重复键错误码
/**
* 执行可能出现重复键的数据库操作
* @param operation 数据库操作
* @param duplicatekeyhandler 重复键处理器
* @return 处理结果
*/
public static <t> t executewithduplicatekeyhandling(
supplier<t> operation,
function<exception, t> duplicatekeyhandler) {
try {
return operation.get();
} catch (dataaccessexception e) {
// 提取原始异常
throwable cause = e.getcause();
if (cause instanceof sqlexception) {
sqlexception sqlex = (sqlexception) cause;
// 通过错误码判断,而非不可靠的字符串匹配
if (sqlex.geterrorcode() == er_dup_entry) {
// 调用重复键处理器
return duplicatekeyhandler.apply((exception) cause);
}
}
// 重新抛出其他异常
throw e;
}
}
}
使用示例:
public boolean insertusersafely(user user) {
return mysqlexceptionhelper.executewithduplicatekeyhandling(
// 正常插入逻辑
() -> {
int rows = usermapper.insert(user);
return rows > 0;
},
// 重复键处理逻辑
ex -> {
log.warn("用户{}已存在,尝试更新", user.getusername());
int rows = usermapper.updatebyusername(user);
return rows > 0;
}
);
}
8. 不同方案性能对比
下面是各种方案在不同场景下的性能对比(基于实际测试数据):

性能测试环境:mysql 8.0, 16g 内存, ssd 存储, 1 万条记录,20%重复率
索引扫描对性能的影响:
insert ignore和on duplicate key update直接利用唯一索引的 b+树结构快速判断重复,仅需一次索引查找操作- 预检查方案则需要额外的索引查询和多次与数据库交互,增加网络延迟和查询成本
- 当使用唯一索引的前缀索引(如
create unique index idx_name on user(username(20)))时,判断重复只比较前 n 个字符,需确保前缀长度足够区分业务数据
事务隔离级别的影响: 在 rr(repeatable read)隔离级别下,预检查方案可能读到旧版本数据,而在实际插入时才发现数据已被其他事务插入,导致出现明明检查过却仍触发唯一键异常的问题。而在 rc(read committed)隔离级别下,on duplicate key update使用快照读,可能减少锁等待;而 rr 隔离级别下可能触发间隙锁,增加锁范围,进一步影响并发性能。
9. 方案原理对比
各种方案在锁机制、事务行为上存在显著差异:

比较表:
| 方案 | 锁行为 | 锁范围 | 事务复杂度 | 主键变化 | 并发友好度 |
|---|---|---|---|---|---|
| insert ignore | 只锁冲突时不操作 | 最小 | 简单 | 不变 | 最高 |
| on duplicate key update | 锁已有行并更新 | 中等 | 中等 | 不变 | 中等 |
| replace into | 锁已有行,删除后再插入 | 最大 | 复杂(删除+插入) | 自增主键会变化 | 最低 |
| 分布式锁+预检查 | 全局分布式锁 | 跨服务 | 高 | 不变 | 较低 |
在高并发写入场景,insert ignore的锁竞争最小,性能最优;而replace into可能导致更多的锁等待和死锁风险。
10. 应用场景案例
10.1 用户注册场景
用户注册时,需要确保用户名或邮箱唯一:
@service
public class userregistrationservice {
@autowired
private usermapper usermapper;
public registerresult register(registerrequest request) {
user user = new user();
user.setusername(request.getusername());
user.setemail(request.getemail());
user.setpassword(encryptpassword(request.getpassword()));
user.setcreatetime(new date());
try {
// 使用insert ignore插入
int result = usermapper.insertignore(user);
if (result > 0) { // 成功插入新用户
return registerresult.success();
} else { // 用户名已存在
// 查询是否是用户名冲突
user existinguser = usermapper.selectbyusername(user.getusername());
if (existinguser != null) {
return registerresult.usernameexists();
} else {
// 可能是邮箱冲突
return registerresult.emailexists();
}
}
} catch (exception e) {
log.error("注册异常", e);
return registerresult.error("系统异常");
}
}
}
10.2 数据导入场景
批量导入用户数据,忽略重复记录:
@service
public class dataimportservice {
@autowired
private usermapper usermapper;
@autowired
private metricsservice metricsservice; // 监控服务
@transactional(rollbackfor = exception.class)
public importresult importusers(list<userdto> userdtos) {
importresult result = new importresult();
// 数据预处理和验证
list<user> validusers = userdtos.stream()
.filter(this::isvaliduserdata)
.map(this::converttouser)
.collect(collectors.tolist());
if (validusers.isempty()) {
result.setmessage("没有有效数据");
return result;
}
// 分批处理,每批500条
int batchsize = 500;
list<list<user>> batches = new arraylist<>();
for (int i = 0; i < validusers.size(); i += batchsize) {
batches.add(validusers.sublist(i, math.min(validusers.size(), i + batchsize)));
}
int totalimported = 0;
int totalduplicated = 0;
list<string> errors = new arraylist<>();
for (list<user> batch : batches) {
try {
int batchcount = batch.size();
int imported = usermapper.batchinsertignore(batch);
totalimported += imported;
totalduplicated += (batchcount - imported);
// 记录监控指标
metricsservice.recordmetrics(
"user_import_success", imported,
"user_import_duplicate", batchcount - imported,
"user_import_duplicate_ratio", (batchcount - imported) * 100.0 / batchcount
);
} catch (exception e) {
log.error("导入批次异常", e);
errors.add("批次导入错误: " + e.getmessage());
}
}
result.settotalprocessed(validusers.size());
result.setsuccesscount(totalimported);
result.setduplicatecount(totalduplicated);
result.seterrors(errors);
return result;
}
}
10.3 分布式 id 生成器场景
基于数据库序列的分布式 id 生成方案,确保生成的 id 全局唯一:
@service
public class sequencegenerator {
@autowired
private jdbctemplate jdbctemplate;
/**
* 获取指定业务类型的id序列段
* @param type 业务类型
* @param step 步长(一次获取多少个id)
* @return 起始id,应用可在内存中递增使用
*/
public long getnextidbatch(string type, int step) {
// 使用悲观锁确保并发安全
string selectsql = "select current_id from id_generator where type = ? for update";
long currentid = jdbctemplate.queryforobject(selectsql, long.class, type);
if (currentid == null) {
// 首次使用,初始化序列
string insertsql = "insert into id_generator(type, current_id, step) values(?, 0, ?)";
jdbctemplate.update(insertsql, type, step);
currentid = 0l;
}
// 更新序列值
string updatesql = "update id_generator set current_id = current_id + ? where type = ?";
jdbctemplate.update(updatesql, step, type);
// 返回当前批次的起始id
return currentid;
}
}
// id生成器表结构
/*
create table id_generator (
type varchar(50) primary key,
current_id bigint not null,
step int not null default 1000,
update_time timestamp default current_timestamp on update current_timestamp
);
*/
10.4 金融交易场景的幂等性设计
金融系统中,支付交易必须确保幂等性,避免重复扣款:
@service
public class paymentservice {
@autowired
private transactionmapper transactionmapper;
@autowired
private accountmapper accountmapper;
/**
* 执行支付交易(幂等操作)
* 通过订单号+交易类型作为唯一键,确保同一笔交易只执行一次
*/
@transactional(rollbackfor = exception.class)
public paymentresult pay(string orderno, string accountid, bigdecimal amount) {
// 创建交易记录(使用唯一约束确保幂等)
transactiondo transaction = new transactiondo();
transaction.setorderno(orderno);
transaction.settype("payment");
transaction.setaccountid(accountid);
transaction.setamount(amount);
transaction.setstatus("processing");
transaction.setcreatetime(new date());
// 尝试插入交易记录,如果已存在则返回0
int affected = transactionmapper.insertignore(transaction);
if (affected == 0) {
// 交易已存在,查询状态返回
transactiondo existingtx = transactionmapper.selectbyordernoandtype(orderno, "payment");
return new paymentresult(existingtx.getstatus(), "交易已处理");
}
try {
// 执行实际扣款逻辑(此部分必须保证原子性)
boolean success = accountmapper.deductbalance(accountid, amount) > 0;
// 更新交易状态
if (success) {
transactionmapper.updatestatus(orderno, "payment", "success");
return new paymentresult("success", "支付成功");
} else {
transactionmapper.updatestatus(orderno, "payment", "failed");
return new paymentresult("failed", "余额不足");
}
} catch (exception e) {
// 异常情况更新交易状态
transactionmapper.updatestatus(orderno, "payment", "error");
throw e; // 向上抛出异常触发事务回滚
}
}
}
@mapper
public interface transactionmapper {
@insert("insert ignore into transactions(order_no, type, account_id, amount, status, create_time) " +
"values(#{orderno}, #{type}, #{accountid}, #{amount}, #{status}, #{createtime})")
int insertignore(transactiondo transaction);
@select("select * from transactions where order_no = #{orderno} and type = #{type}")
transactiondo selectbyordernoandtype(@param("orderno") string orderno, @param("type") string type);
@update("update transactions set status = #{status}, update_time = now() " +
"where order_no = #{orderno} and type = #{type}")
int updatestatus(@param("orderno") string orderno, @param("type") string type, @param("status") string status);
}
10.5 实时数据同步场景
设备实时数据采集系统,确保只保留每台设备每个时间点的最新数据:
@service
public class devicemetricsservice {
@autowired
private metricsmapper metricsmapper;
/**
* 记录设备实时指标数据
* 使用device_id+timestamp作为唯一键,确保同一时间点只保留最新数据
*/
public void recordmetric(string deviceid, date timestamp, double value, string metrictype) {
devicemetric metric = new devicemetric();
metric.setdeviceid(deviceid);
metric.settimestamp(timestamp);
metric.setvalue(value);
metric.setmetrictype(metrictype);
metric.setcreatetime(new date());
// 使用replace into确保只保留最新值
metricsmapper.replacemetric(metric);
}
/**
* 批量记录设备指标(高性能版本)
*/
public void batchrecordmetrics(list<devicemetric> metrics) {
if (collectionutils.isempty(metrics)) {
return;
}
// 分批处理,每批200条
int batchsize = 200;
for (int i = 0; i < metrics.size(); i += batchsize) {
list<devicemetric> batch = metrics.sublist(i, math.min(metrics.size(), i + batchsize));
metricsmapper.batchreplacemetrics(batch);
}
}
}
@mapper
public interface metricsmapper {
@insert("replace into device_metrics(device_id, timestamp, metric_type, value, create_time) " +
"values(#{deviceid}, #{timestamp}, #{metrictype}, #{value}, #{createtime})")
int replacemetric(devicemetric metric);
@insert("<script>" +
"replace into device_metrics(device_id, timestamp, metric_type, value, create_time) values " +
"<foreach collection='metrics' item='metric' separator=','>" +
"(#{metric.deviceid}, #{metric.timestamp}, #{metric.metrictype}, " +
"#{metric.value}, #{metric.createtime})" +
"</foreach>" +
"</script>")
int batchreplacemetrics(@param("metrics") list<devicemetric> metrics);
}
11. 跨库分表场景的去重方案
在分库分表架构中,数据被分散到不同的物理表中,单靠数据库唯一索引无法跨库保证唯一性:
实现示例:
@service
public class shardinguserservice {
@autowired
private list<usermapper> shardedmappers; // 不同分片的mapper
@autowired
private consistenthash consistenthash; // 一致性哈希服务
/**
* 跨分片用户注册,确保用户名全局唯一
*/
public registerresult registerwithsharding(registerrequest request) {
// 1. 先查询全局唯一索引表,确认用户名不存在
string username = request.getusername();
// 使用分布式锁防止并发插入
string lockkey = "user:register:" + username;
try (redislockwrapper lock = new redislockwrapper(redissonclient, lockkey)) {
if (!lock.trylock(5, timeunit.seconds)) {
return registerresult.busy();
}
// 2. 检查全局用户名索引
if (usernameindexmapper.exists(username)) {
return registerresult.usernameexists();
}
// 3. 生成全局唯一用户id
string userid = snowflakeidgenerator.nextid();
// 4. 确定分片(使用一致性哈希算法)
int shardindex = consistenthash.getshardindex(username);
usermapper targetmapper = shardedmappers.get(shardindex);
// 5. 插入用户数据到对应分片
user user = createuserfromrequest(request, userid);
targetmapper.insert(user);
// 6. 插入全局用户名索引(使用insert ignore防止并发)
usernameindex index = new usernameindex(username, userid, shardindex);
usernameindexmapper.insertignore(index);
return registerresult.success(userid);
} catch (exception e) {
log.error("分片用户注册异常", e);
return registerresult.error("系统异常");
}
}
}
/**
* 基于虚拟节点的一致性哈希实现
*/
@component
public class consistenthash {
private final treemap<long, integer> virtualnodes = new treemap<>();
private final int numberofreplicas; // 虚拟节点数量
private final int shardcount; // 实际分片数
public consistenthash(@value("${sharding.virtual-nodes:160}") int numberofreplicas,
@value("${sharding.shard-count:4}") int shardcount) {
this.numberofreplicas = numberofreplicas;
this.shardcount = shardcount;
// 初始化虚拟节点
for (int i = 0; i < shardcount; i++) {
addshard(i);
}
}
private void addshard(int shardindex) {
for (int i = 0; i < numberofreplicas; i++) {
string nodekey = shardindex + "-" + i;
long hash = hash(nodekey);
virtualnodes.put(hash, shardindex);
}
}
public int getshardindex(string key) {
if (virtualnodes.isempty()) {
return 0;
}
long hash = hash(key);
// 找到第一个大于等于hash的节点
map.entry<long, integer> entry = virtualnodes.ceilingentry(hash);
// 如果没有找到,则取第一个节点
if (entry == null) {
entry = virtualnodes.firstentry();
}
return entry.getvalue();
}
private long hash(string key) {
// 使用murmurhash获得更均匀的哈希分布
return hashing.murmur3_128().hashstring(key, standardcharsets.utf_8).aslong();
}
}
12. 总结
下面表格全面总结了各种 mysql 重复数据处理方案的特性和适用场景:
| 方案 | 优点 | 缺点 | 适用场景 | 锁粒度 | 事务复杂度 | 实现复杂度 | 维护成本 |
|---|---|---|---|---|---|---|---|
| try-catch 异常捕获 | 实现简单,通用性强 | 性能较低,异常开销大 | 单条插入,低频操作 | 插入行 | 简单 | 低 | 低 |
| 预检查+条件插入 | 逻辑清晰 | 存在并发问题,需要额外查询 | 单用户操作,并发低场景 | 查询+插入行 | 中等 | 中 | 中 |
| insert ignore | 语法简单,性能最佳 | 无法获知哪些记录被忽略 | 只需插入不存在记录场景 | 仅冲突行 | 简单 | 低 | 低 |
| on duplicate key update | 一条语句完成插入或更新 | sql 较长,需要指定更新字段 | 需要更新已存在记录场景 | 已有行 | 中等 | 中 | 中(需维护更新字段) |
| replace into | 语法简单,总是保证最新数据 | 会删除并重建记录,可能引发级联删除 | 需要完全覆盖已有数据场景 | 旧行+新行 | 复杂(删除+插入) | 低 | 中(需注意外键) |
| 批量插入方案 | 高性能,减少数据库交互 | 实现较复杂 | 大批量数据导入场景 | 多行 | 较大 | 中 | 中 |
| 分布式锁+唯一索引 | 从源头避免重复数据 | 实现复杂度高 | 分布式系统,跨库场景 | 全局分布式锁 | 高(跨服务) | 高 | 高(需维护锁服务) |
| 跨库分表去重 | 支持分库分表架构 | 实现极其复杂 | 大规模分布式系统 | 分片+全局索引 | 极高 | 极高 | 极高(需分片路由逻辑) |
通过合理选择和实现这些方案,我们可以有效解决 mysql 中的重复数据处理问题,提高系统的健壮性和性能。实际项目中,往往需要根据具体场景组合使用不同策略,例如高并发场景下可能同时使用分布式锁、全局唯一 id 和数据库唯一索引作为多重保障。
这些方案各有优劣,选择时需考虑业务需求、数据量大小、并发级别和系统架构等因素。在大多数场景下,使用insert ignore和on duplicate key update是既简单又高效的解决方案,而在分布式系统中,还需要加入全局唯一 id 和分布式锁等机制确保数据一致性。
以上就是mysql重复数据处理的七种高效方法的详细内容,更多关于mysql重复数据处理的资料请关注代码网其它相关文章!




发表评论