图片分割是图像处理中的一个重要任务,它的目标是将图像划分为多个区域或者对象,例如分割出物体、前景背景或特定的部分。在 python 中,常用的图片分割方法包括传统的图像处理技术(例如阈值分割、区域生长等)和深度学习技术(例如基于预训练模型的语义分割或实例分割)。以下是详细介绍和示例代码:
1. 基于传统图像处理的分割方法
(1) 使用固定阈值分割图片
使用 opencv 的阈值处理来将前景和背景分离。适合简单的二值图像。
import cv2
import numpy as np
# 加载图片
image = cv2.imread('image.jpg', 0) # 以灰度加载图片
# 应用二值化阈值分割
_, binary = cv2.threshold(image, 128, 255, cv2.thresh_binary)
# 显示分割结果
cv2.imshow('original image', image)
cv2.imshow('binary image', binary)
cv2.waitkey(0)
cv2.destroyallwindows()
参数说明:
128 是阈值,低于此值的像素设置为 0,高于阈值的设置为 255。
cv2.thresh_binary 是二值化模式。
(2) 自适应阈值分割
适合光照不均的情况,使用局部区域的像素值计算阈值。
import cv2
# 加载图片
image = cv2.imread('image.jpg', 0)
# 自适应阈值分割
binary_adaptive = cv2.adaptivethreshold(image, 255, cv2.adaptive_thresh_gaussian_c,cv2.thresh_binary, 11, 2)
# 显示分割结果
cv2.imshow('adaptive threshold', binary_adaptive)
cv2.waitkey(0)
cv2.destroyallwindows()
参数说明:
cv2.adaptive_thresh_gaussian_c 使用高斯加权的邻域计算阈值。
11 是邻域大小。
2 是阈值偏移。
(3) 使用图像边缘检测分割
通过检测图像的边缘将不同的区域分离。
import cv2
# 加载图片
image = cv2.imread('image.jpg', 0)
# 使用canny边缘检测
edges = cv2.canny(image, 100, 200)
# 显示边缘分割结果
cv2.imshow('edge detection', edges)
cv2.waitkey(0)
cv2.destroyallwindows()
参数说明:
100 是低阈值,200 是高阈值,用于检测边缘。
(4) 基于 k-means 的聚类分割
可以将图像的颜色或亮度聚类为k个类别,适合彩色图像分割。
import cv2
import numpy as np
# 加载图片
image = cv2.imread('image.jpg')
image = cv2.cvtcolor(image, cv2.color_bgr2rgb)
z = image.reshape((-1, 3)) # 将图像从二维展开为一维
# 使用 k-means 聚类
z = np.float32(z)
criteria = (cv2.term_criteria_eps + cv2.term_criteria_max_iter, 10, 1.0)
k = 3 # 聚类数
_, labels, centers = cv2.kmeans(z, k, none, criteria, 10, cv2.kmeans_random_centers)
# 将聚类结果映射回图像
centers = np.uint8(centers)
segmented_image = centers[labels.flatten()]
segmented_image = segmented_image.reshape(image.shape)
# 显示分割结果
import matplotlib.pyplot as plt
plt.imshow(segmented_image)
plt.show()参数说明:
k 是分割的颜色聚类数,譬如设置为3会将图像分割成3种颜色区域。
2. 深度学习分割方法
对于复杂分割任务,深度学习可以提供更高的精度。典型方法包括使用预训练的分割模型(如 deeplab、mask r-cnn 等)。
(1) 使用 opencv dnn 模块加载预训练的 deeplabv3+ 模型
deeplabv3+ 是一种流行的语义分割模型。
import cv2
import numpy as np
# 加载 deeplabv3+ 模型
net = cv2.dnn.readnetfromtensorflow('deeplabv3.pb')
# 加载图像
image = cv2.imread('image.jpg')
blob = cv2.dnn.blobfromimage(image, scalefactor=1.0/255, size=(513, 513),
mean=(127.5, 127.5, 127.5), swaprb=true, crop=false)
# 推理
net.setinput(blob)
output = net.forward()
# 解析结果
segmentation_map = np.argmax(output[0], axis=0)
# 显示分割结果
segmentation_map = cv2.resize(segmentation_map.astype(np.uint8), (image.shape[1], image.shape[0]))
cv2.imshow("segmentation map", segmentation_map)
cv2.waitkey(0)
cv2.destroyallwindows()
(2) 使用 pytorch 或 tensorflow 加载分割模型
如果需要灵活的操作,可以使用深度学习框架加载分割模型进行推理。
import torch
from torchvision import models
from torchvision import transforms
from pil import image
import matplotlib.pyplot as plt
# 加载预训练的 deeplabv3 模型
model = models.segmentation.deeplabv3_resnet101(pretrained=true)
model.eval()
# 加载图片并预处理
image = image.open("image.jpg")
transform = transforms.compose([
transforms.totensor(),
transforms.resize((520, 520)),
transforms.normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
input_image = transform(image).unsqueeze(0)
# 推理
output = model(input_image)['out'][0]
segmentation_map = torch.argmax(output, dim=0).numpy()
# 显示分割结果
plt.imshow(segmentation_map)
plt.show()cv2.threshold(), cv2.adaptivethreshold(), cv2.canny(),cv2.kmeans() 函数详解
1.cv2.threshold()
作用:图像二值化,将灰度图像转为黑白图像或多级阈值图像。
retval, dst = cv2.threshold(src, thresh, maxval, type)
参数说明:
src: 输入图像,必须是灰度图(单通道,uint8 类型)。
thresh: 阈值,将灰度图中的像素值与该阈值进行比较。
maxval: 如果满足阈值规则,输出像素值将设置为该值。
type: 阈值类型,有以下几种:
- 1、cv2.thresh_binary: 大于阈值的像素置为 maxval,否则置为 0。
- 2、cv2.thresh_binary_inv: 小于阈值的像素置为 maxval,否则置为 0。
- 3、cv2.thresh_trunc: 大于阈值的像素置为阈值,否则保持原值。
- 4、cv2.thresh_tozero: 小于阈值的像素置为 0,否则保持原值。
- 5、cv2.thresh_tozero_inv: 大于阈值的像素置为 0,否则保持原值。
主要用途:
图像二值化(将物体与背景分离)。
特定场景下的简单图像分割。
2.cv2.adaptivethreshold()
作用:图像局部自适应二值化,根据局部区域内的灰度值确定阈值。这种方法在光照条件不均匀的情况下很有优势。
dst = cv2.adaptivethreshold(src, maxvalue, adaptivemethod, thresholdtype, blocksize, c)
参数说明:
src: 输入图像,必须是灰度图。
maxvalue: 满足阈值条件的像素的赋值。
adaptivemethod: 自适应阈值算法,有以下两种:
cv2.adaptive_thresh_mean_c: 阈值是局部窗口的平均值减去 c。
cv2.adaptive_thresh_gaussian_c: 阈值是局部窗口的加权平均值减去 c。
thresholdtype: 阈值类型(通常为 cv2.thresh_binary 或 cv2.thresh_binary_inv)。
blocksize: 局部区域的尺寸,必须为奇数(如 3、5、11)。
c: 从局部平均值中减去常数 c。
主要用途:
- 图像自适应二值化。
- 光照不均情况下的前景分离。
3.cv2.canny()
作用:边缘检测,采用 canny 算法从图像中提取显著边缘。
dst = cv2.canny(image, threshold1, threshold2[, aperturesize[, l2gradient]])
参数说明:
image: 输入图像,需为灰度图。
threshold1: 较小的阈值,用于边缘连接。
threshold2: 较大的阈值,用于检测显著边缘。
aperturesize: sobel 算子的核大小,默认值为 3。通常是 3, 5, 7。
l2gradient: 是否使用更精确的 l2 范数计算梯度,默认为 false
主要用途:
图像边缘提取。
准备图像分割的轮廓信息。
4.cv2.kmeans()
作用:基于 k-means 算法对输入数据进行聚类,适合图像颜色分割或亮度分割。
retval, labels, centers = cv2.kmeans(data, k, bestlabels, criteria, attempts, flags)
参数说明:
data: 输入数据(通常是图像的像素值矩阵,需转换为 np.float32)。
k: 聚类数,即分割的类别数量。
bestlabels: 初始标签(通常为 none)。
criteria: k-means 的终止条件,例如迭代次数或误差:
(cv2.term_criteria_eps + cv2.term_criteria_max_iter, max_iter, epsilon)。
max_iter 是最大迭代次数,epsilon 是误差容忍度。
attempts: 尝试执行 k-means 聚类的次数,输出至少达到局部最优解。
flags: 初始化中心的方法,常用:
cv2.kmeans_pp_centers: 使用 k-means++ 初始化中心点。
cv2.kmeans_random_centers: 使用随机选择初始化中心点。
cv2.dnn.blobfromimage(),transforms.compose()函数详解
1.cv2.dnn.blobfromimage()
功能:
cv2.dnn.blobfromimage() 是 opencv 的 dnn(深度学习)模块中的方法,用于将输入图像转换为深度学习模型可以接受的标准化张量(“blob”)。具体包括:
重新调整图像大小。
归一化图像像素(例如缩放到 [0,1] 或减去均值)。
转换通道顺序(例如将图片从 bgr 转换为 rgb)。
转换维度顺序(从 hwc -> chw,即 [高度, 宽度, 通道] -> [通道, 高度, 宽度])。
cv2.dnn.blobfromimage(image, scalefactor=1.0, size=(width, height),
mean=(meanr, meang, meanb), swaprb=true, crop=false)
参数说明:
- image: 输入图像,通常是三通道(bgr)图像或单通道图像。
- scalefactor: 缩放因子,用于将像素值归一化。例如,设置 scalefactor=1/255 将像素值从 [0,255] 缩放到 [0,1]。
- size: 重新调整后的图像尺寸,通常根据模型的输入需求设置(如 (224, 224))。
- mean: 均值,用于归一化(针对每个通道减去均值)。例如:(meanr, meang, meanb)。
- swaprb: 是否交换 r 和 b 通道(将 bgr 转为 rgb),默认为 true。
- crop: 是否在调整大小后裁剪图像,如果为 true,会将图像裁剪到目标大小。
返回值:
返回一个预处理后的 blob,即一个多维的 numpy 数组,形状通常为:
[batch_size, channels, height, width]
对单张图像而言,batch_size = 1。
import cv2
# 读取图像(通常是 bgr 格式)
image = cv2.imread('image.jpg')
# 创建 blob
blob = cv2.dnn.blobfromimage(image, scalefactor=1/255.0, size=(224, 224),
mean=(0, 0, 0), swaprb=true, crop=false)
# 输出 blob 的形状:通常为 (1, 3, 224, 224),对应 [batch, channels, height, width]
print("blob shape:", blob.shape)
# 将 blob 传入模型
# net.setinput(blob)
# output = net.forward()
常见参数设置:
- 归一化:如果模型输入要求的像素范围是 [0, 1],可以通过 scalefactor = 1/255 实现归一化。
- 均值减法:一些预训练模型会要求每个通道的均值为特定值,如 (123.68, 116.78, 103.94)(vgg 或 resnet 等常用)。
- 图像尺寸:目标模型的输入尺寸通常固定,如 (224, 224) 或 (300, 300)。
2.transforms.compose()
功能:
transforms.compose() 是 pytorch 的 torchvision.transforms 模块中的方法,用来对图像数据进行多步组合式处理,例如裁剪、缩放、归一化等。它允许将多个图像变换操作(transforms)链接在一起。
transforms.compose([transform1, transform2, ..., transformn])
参数说明:
- transform1, transform2, …, transformn:每个变换操作都是一个 torchvision.transforms 的实例。 例如:
- transforms.resize(size): 缩放图像到指定大小。
- transforms.centercrop(size): 从图像中央裁剪到指定大小。
- transforms.normalize(mean, std): 标准化张量,减去均值并除以标准差。
- transforms.totensor(): 将图像从 pil 格式转换为 pytorch 张量,并归一化到 [0, 1] 范围。
- transforms.randomhorizontalflip§: 随机水平翻转,概率为 p。
使用场景:
用于对图像数据的批量预处理,尤其是在训练深度学习模型前对数据进行标准化和增强处理。
import torch
from torchvision import transforms
from pil import image
# 加载图像
image = image.open("image.jpg")
# 定义数据变换
data_transforms = transforms.compose([
transforms.resize((224, 224)), # 调整大小到 (224, 224)
transforms.totensor(), # 转为 pytorch 张量
transforms.normalize(mean=[0.485, 0.456, 0.406], # 按通道归一化 (均值减去)
std=[0.229, 0.224, 0.225]) # 按通道归一化 (标准差除以)
])
# 对图像应用变换
tensor_image = data_transforms(image)
# 检查结果
print("tensor shape:", tensor_image.shape) # 通常为 (3, 224, 224)
print("tensor values (normalized):", tensor_image)常用的变换操作:
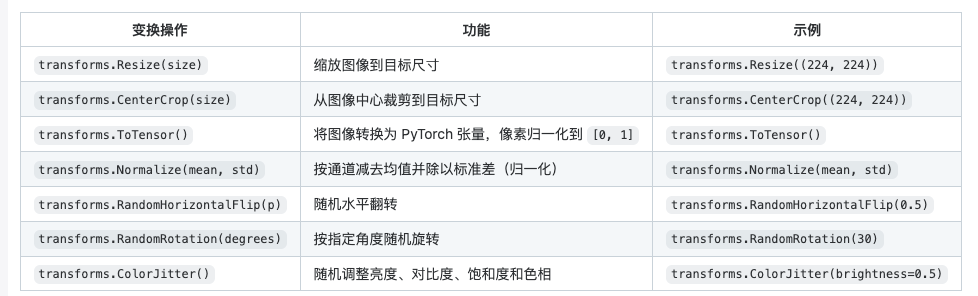
组合数据增强处理示例:
import torchvision.transforms as transforms
from pil import image
# 加载图像
image = image.open("image.jpg")
# 定义数据增强变换
data_transforms = transforms.compose([
transforms.randomrotation(30), # 随机旋转 ±30 度
transforms.randomhorizontalflip(p=0.5), # 随机水平翻转 50% 概率
transforms.colorjitter(brightness=0.2, contrast=0.3), # 随机调整亮度和对比度
transforms.resize((224, 224)), # 调整大小到 (224, 224)
transforms.totensor(), # 转为 pytorch 张量
])
# 应用变换
tensor_image = data_transforms(image)
print("augmented tensor shape:", tensor_image.shape)cv2.dnn.blobfromimage() vs transforms.compose()
这两者主要是针对不同框架的图像预处理功能:
cv2.dnn.blobfromimage() :主要用于 opencv dnn 模型,侧重于将输入格式标准化为深度学习模型的张量。
transforms.compose() :是 pytorch 的高级操作,用于批量构造灵活的数据增强和标准化流程。
到此这篇关于python实现图片分割的多种方法总结的文章就介绍到这了,更多相关python图片分割内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论