1. 概述
在数据分析、报表整理、数据库管理等工作中,数据清洗是不可或缺的一步。原始excel数据常常存在格式不统一、空值、重复数据等问题,影响数据的准确性和可用性。本篇文章将详细介绍一款高效的excel数据清洗工具,帮助您轻松处理杂乱数据,提高数据质量。
2. 功能使用
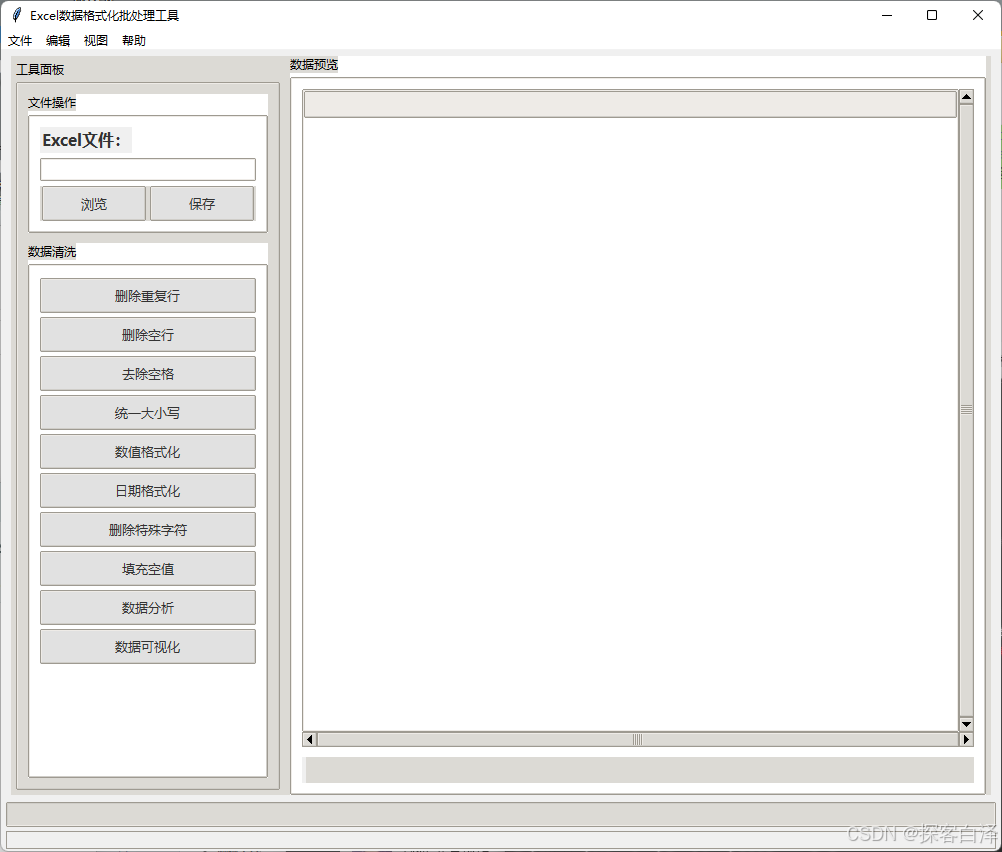
基本操作流程
使用本工具进行数据清洗的操作流程如下:
- 打开文件:点击"浏览"按钮,或使用菜单栏"文件 > 打开"选择需要处理的excel文件。
- 数据清洗:在左侧工具面板选择需要的清洗操作,例如删除重复行、格式化日期等。
- 预览结果:右侧区域实时显示数据变化,确保清洗效果符合预期。
- 保存文件:点击"保存"按钮,或使用菜单栏"文件 > 保存",将处理后的文件存储。
3. 主要功能说明
1. 删除重复行
作用:删除数据表中完全相同的行,确保数据唯一性。
2. 删除空行
作用:清除所有值均为空的行,避免无效数据干扰分析。
3. 去除空格
作用:移除文本字段中的首尾空格,防止隐藏字符影响计算。
4. 统一大小写
作用:可选择转换为小写、大写或首字母大写,以确保数据格式一致。
5. 数值格式化
作用:统一数值的小数位数(默认保留2位),保证数据规范。
6. 日期格式化
作用:提供多种日期格式选项,避免因格式混乱导致的数据处理错误。
7. 删除特殊字符
作用:去除文本中的标点符号、特殊字符,适用于纯文本数据处理。
8. 填充空值
作用:支持多种空值填充方式(平均值、中位数、众数等),提高数据完整性。
4. 适用场景
4.1 典型使用场景
数据预处理:在进行数据分析前,先对原始数据进行标准化处理。
报表整理:整合不同来源的数据,保证格式统一。
数据库导入准备:清理excel数据,使其符合数据库字段要求。
数据迁移:在不同系统之间转移数据时,保证格式一致。
日常办公:快速整理杂乱的excel表格,提高工作效率。
4.2 适用人群
数据分析师
财务/行政人员
市场研究人员
数据库管理员
任何需要处理excel数据的办公人员
5. 注意事项
5.1 使用前注意事项
备份原始数据:建议在处理前保存一份原始文件,以免数据丢失。
数据量限制:预览功能仅显示前100行,但清洗操作会应用于所有数据。
文件格式:支持.xlsx和.xls格式,建议使用.xlsx以获得更好的兼容性。
5.2 操作注意事项
撤销功能:当前版本不支持撤销操作,请谨慎执行。
特殊字符处理:删除特殊字符可能影响某些编码数据,请提前检查。
日期识别:自动识别日期列可能不够准确,建议手动确认。
数值处理:非数值字段尝试数值格式化可能导致错误。
6.系统要求
本工具依赖python环境,使用以下库来处理数据:
- python 3.6+
- pandas(数据处理核心库)
- numpy(数值运算支持)
- openpyxl(用于excel文件操作)
- tkinter(用于gui界面,python自带)
- matplotlib(可视化功能支持)
7.高级技巧
大型文件处理:对于超过10mb的文件,处理可能较慢,建议分批处理。
数据可视化:工具提供基本的可视化功能,适用于数值型数据分析。
快速数据分析:可查看基本统计信息,如均值、中位数、方差等,帮助快速了解数据分布。
8.相关源码
import pandas as pd
import numpy as np
from tkinter import *
from tkinter import ttk, filedialog, messagebox
import os
from tkinter.scrolledtext import scrolledtext
import threading
from queue import queue
import logging
from datetime import datetime
# 配置日志
logging.basicconfig(
filename='excel_cleaner.log',
level=logging.info,
format='%(asctime)s - %(levelname)s - %(message)s'
)
# 模拟 datahandler, columnselector, parameterdialog 类
class datahandler:
def __init__(self):
self.df = none
self.operation_history = []
self.redo_history = []
def load_excel(self, file_path):
self.df = pd.read_excel(file_path)
return self.df
def save_excel(self, file_path):
self.df.to_excel(file_path, index=false)
def get_statistics(self):
return {
'row_count': len(self.df),
'column_count': len(self.df.columns)
}
def get_column_types(self):
return self.df.dtypes
def remove_spaces(self, columns):
for col in columns:
if self.df[col].dtype == object:
self.df[col] = self.df[col].str.strip()
return self.df
def normalize_case(self, case_type, columns):
for col in columns:
if self.df[col].dtype == object:
if case_type == 'lower':
self.df[col] = self.df[col].str.lower()
elif case_type == 'upper':
self.df[col] = self.df[col].str.upper()
elif case_type == 'title':
self.df[col] = self.df[col].str.title()
return self.df
def format_numbers(self, decimal_places, columns):
for col in columns:
if pd.api.types.is_numeric_dtype(self.df[col]):
self.df[col] = self.df[col].round(decimal_places)
return self.df
def format_dates(self, date_format, columns):
for col in columns:
if pd.api.types.is_datetime64_any_dtype(self.df[col]):
self.df[col] = self.df[col].dt.strftime(date_format)
return self.df
def remove_special_chars(self, pattern, columns):
for col in columns:
if self.df[col].dtype == object:
self.df[col] = self.df[col].str.replace(pattern, '', regex=true)
return self.df
def fill_empty_values(self, method, value=none, columns=none):
if columns is none:
columns = self.df.columns
for col in columns:
if method == 'value':
self.df[col].fillna(value, inplace=true)
elif method == 'mean':
self.df[col].fillna(self.df[col].mean(), inplace=true)
elif method == 'median':
self.df[col].fillna(self.df[col].median(), inplace=true)
elif method == 'mode':
self.df[col].fillna(self.df[col].mode()[0], inplace=true)
elif method == 'ffill':
self.df[col].fillna(method='ffill', inplace=true)
elif method == 'bfill':
self.df[col].fillna(method='bfill', inplace=true)
return self.df
class columnselector:
def __init__(self, parent, columns, column_types, title, callback):
self.callback = callback
self.selected_columns = []
self.window = toplevel(parent)
self.window.title(title)
ttk.label(self.window, text="选择列:").pack(pady=10)
self.listbox = listbox(self.window, selectmode=multiple)
for col in columns:
self.listbox.insert(end, col)
self.listbox.pack(fill=both, expand=true, padx=10, pady=10)
button_frame = ttk.frame(self.window)
button_frame.pack(fill=x, padx=10, pady=10)
ttk.button(button_frame, text="确定", command=self.on_confirm).pack(side=left, padx=10)
ttk.button(button_frame, text="取消", command=self.window.destroy).pack(side=left)
def on_confirm(self):
self.selected_columns = [self.listbox.get(i) for i in self.listbox.curselection()]
self.callback(self.selected_columns)
self.window.destroy()
class parameterdialog:
def __init__(self, parent, params, title, callback):
self.callback = callback
self.params = params
self.values = {}
self.window = toplevel(parent)
self.window.title(title)
for param_name, param_info in params.items():
ttk.label(self.window, text=param_info['label']).pack(pady=5)
if param_info['type'] == 'choice':
var = stringvar()
var.set(param_info['default'])
ttk.combobox(self.window, textvariable=var, values=param_info['choices']).pack(fill=x, padx=10)
self.values[param_name] = var
elif param_info['type'] == 'int':
var = intvar()
var.set(param_info['default'])
ttk.spinbox(self.window, from_=param_info['min'], to=param_info['max'], textvariable=var).pack(fill=x, padx=10)
self.values[param_name] = var
elif param_info['type'] == 'str':
var = stringvar()
var.set(param_info['default'])
ttk.entry(self.window, textvariable=var).pack(fill=x, padx=10)
self.values[param_name] = var
button_frame = ttk.frame(self.window)
button_frame.pack(fill=x, padx=10, pady=10)
ttk.button(button_frame, text="确定", command=self.on_confirm).pack(side=left, padx=10)
ttk.button(button_frame, text="取消", command=self.window.destroy).pack(side=left)
def on_confirm(self):
result = {param_name: var.get() for param_name, var in self.values.items()}
self.callback(result)
self.window.destroy()
class excelcleaner:
def __init__(self):
self.window = tk()
self.window.title("excel数据格式化批处理工具")
self.window.geometry("1000x800")
self.window.configure(bg='#f0f0f0')
# 初始化数据处理器
self.data_handler = datahandler()
self.processing_queue = queue()
# 设置样式
self.setup_styles()
# 创建菜单栏
self.create_menu()
# 创建主框架
main_frame = ttk.frame(self.window)
main_frame.pack(fill=both, expand=true, padx=10, pady=5)
# 左侧工具面板
left_panel = ttk.labelframe(main_frame, text="工具面板", padding=10)
left_panel.pack(side=left, fill=y, padx=5, pady=5)
# 文件操作区域
self.create_file_frame(left_panel)
# 清洗操作区域
self.create_clean_frame(left_panel)
# 右侧主要内容区域
right_panel = ttk.frame(main_frame)
right_panel.pack(side=left, fill=both, expand=true, padx=5)
# 预览区域
self.create_preview_frame(right_panel)
# 状态栏
self.create_status_bar()
# 进度条
self.create_progress_bar()
# 绑定快捷键
self.bind_shortcuts()
def setup_styles(self):
style = ttk.style()
style.theme_use('clam')
# 配置按钮样式
style.configure(
"tool.tbutton",
padding=5,
font=('微软雅黑', 10),
background='#e1e1e1',
foreground='#333333'
)
# 配置标签样式
style.configure(
"title.tlabel",
font=('微软雅黑', 12, 'bold'),
background='#f0f0f0',
foreground='#333333'
)
# 配置框架样式
style.configure(
"card.tlabelframe",
background='#ffffff',
padding=10
)
# 配置树形视图样式
style.configure(
"preview.treeview",
font=('微软雅黑', 10),
rowheight=25
)
# 配置进度条样式
style.configure(
"progress.horizontal.tprogressbar",
troughcolor='#f0f0f0',
background='#4caf50',
thickness=10
)
def create_progress_bar(self):
self.progress_var = doublevar()
self.progress_bar = ttk.progressbar(
self.window,
style="progress.horizontal.tprogressbar",
variable=self.progress_var,
maximum=100
)
self.progress_bar.pack(fill=x, padx=5, pady=2)
def bind_shortcuts(self):
self.window.bind('<control-o>', lambda e: self.select_file())
self.window.bind('<control-s>', lambda e: self.save_file())
self.window.bind('<control-z>', lambda e: self.undo())
self.window.bind('<control-y>', lambda e: self.redo())
self.window.bind('<f1>', lambda e: self.show_help())
def process_in_background(self, func, *args, **kwargs):
"""在后台线程中处理耗时操作"""
def wrapper():
try:
self.progress_var.set(0)
self.status_var.set("正在处理...")
self.window.update()
# 执行操作
result = func(*args, **kwargs)
# 更新ui
self.window.after(0, self.update_ui_after_processing, result)
except exception as e:
logging.error(f"处理错误: {str(e)}")
self.window.after(0, self.show_error, str(e))
finally:
self.window.after(0, self.progress_var.set, 100)
self.window.after(0, self.status_var.set, "处理完成")
# 启动后台线程
thread = threading.thread(target=wrapper)
thread.daemon = true
thread.start()
def update_ui_after_processing(self, result):
"""处理完成后更新ui"""
if isinstance(result, tuple):
self.data_handler.df = result[0]
if len(result) > 1:
removed_rows = result[1]
self.status_var.set(f"已删除 {removed_rows} 行数据")
elif isinstance(result, pd.dataframe):
self.data_handler.df = result
if result is not none:
self.update_preview()
def show_error(self, error_msg):
"""显示错误消息"""
messagebox.showerror("错误", f"处理过程中出现错误:{error_msg}")
self.status_var.set("处理失败")
def select_file(self):
file_path = filedialog.askopenfilename(
filetypes=[("excel files", "*.xlsx *.xls")]
)
if file_path:
self.process_in_background(self.data_handler.load_excel, file_path)
def save_file(self):
if self.data_handler.df is not none:
file_path = filedialog.asksaveasfilename(
defaultextension=".xlsx",
filetypes=[("excel files", "*.xlsx")]
)
if file_path:
self.process_in_background(self.data_handler.save_excel, file_path)
def undo(self):
"""撤销上一步操作"""
if self.data_handler.operation_history:
last_operation = self.data_handler.operation_history.pop()
self.data_handler.df = last_operation['previous_state'].copy()
self.update_preview()
self.status_var.set("已撤销上一步操作")
def redo(self):
"""重做上一步操作"""
if hasattr(self.data_handler, 'redo_history') and self.data_handler.redo_history:
last_operation = self.data_handler.redo_history.pop()
self.data_handler.df = last_operation['next_state'].copy()
self.data_handler.operation_history.append(last_operation)
self.update_preview()
self.status_var.set("已重做上一步操作")
def add_operation_to_history(self, operation_name, previous_state, next_state):
"""添加操作到历史记录"""
self.data_handler.operation_history.append({
'name': operation_name,
'previous_state': previous_state.copy(),
'next_state': next_state.copy()
})
# 清空重做历史
if hasattr(self.data_handler, 'redo_history'):
self.data_handler.redo_history.clear()
def remove_duplicates(self):
if self.data_handler.df is not none:
previous_state = self.data_handler.df.copy()
self.data_handler.df = self.data_handler.df.drop_duplicates()
removed_rows = len(previous_state) - len(self.data_handler.df)
self.add_operation_to_history("删除重复行", previous_state, self.data_handler.df.copy())
self.update_preview()
self.status_var.set(f"已删除 {removed_rows} 行重复数据")
def remove_empty_rows(self):
if self.data_handler.df is not none:
previous_state = self.data_handler.df.copy()
self.data_handler.df = self.data_handler.df.dropna(how='all')
removed_rows = len(previous_state) - len(self.data_handler.df)
self.add_operation_to_history("删除空行", previous_state, self.data_handler.df.copy())
self.update_preview()
self.status_var.set(f"已删除 {removed_rows} 行空数据")
def remove_spaces(self):
if self.data_handler.df is not none:
def on_columns_selected(columns):
self.process_in_background(
self.data_handler.remove_spaces,
columns=columns
)
columnselector(
self.window,
list(self.data_handler.df.columns),
self.data_handler.get_column_types(),
title="选择要去除空格的列",
callback=on_columns_selected
)
def normalize_case(self):
if self.data_handler.df is not none:
def on_params_set(params):
def on_columns_selected(columns):
self.process_in_background(
self.data_handler.normalize_case,
case_type=params["case_type"],
columns=columns
)
columnselector(
self.window,
list(self.data_handler.df.columns),
self.data_handler.get_column_types(),
title="选择要统一大小写的列",
callback=on_columns_selected
)
params = {
"case_type": {
"type": "choice",
"label": "大小写格式",
"default": "lower",
"choices": ["lower", "upper", "title"]
}
}
parameterdialog(
self.window,
params,
title="选择大小写格式",
callback=on_params_set
)
def format_numbers(self):
if self.data_handler.df is not none:
def on_params_set(params):
def on_columns_selected(columns):
self.process_in_background(
self.data_handler.format_numbers,
decimal_places=params["decimal_places"],
columns=columns
)
columnselector(
self.window,
list(self.data_handler.df.columns),
self.data_handler.get_column_types(),
title="选择要格式化的数值列",
callback=on_columns_selected
)
params = {
"decimal_places": {
"type": "int",
"label": "小数位数",
"default": 2,
"min": 0,
"max": 10
}
}
parameterdialog(
self.window,
params,
title="设置数值格式",
callback=on_params_set
)
def format_dates(self):
if self.data_handler.df is not none:
def on_params_set(params):
def on_columns_selected(columns):
self.process_in_background(
self.data_handler.format_dates,
date_format=params["date_format"],
columns=columns
)
columnselector(
self.window,
list(self.data_handler.df.columns),
self.data_handler.get_column_types(),
title="选择要格式化的日期列",
callback=on_columns_selected
)
params = {
"date_format": {
"type": "choice",
"label": "日期格式",
"default": "%y-%m-%d",
"choices": [
"%y-%m-%d",
"%y/%m/%d",
"%d-%m-%y",
"%m/%d/%y"
]
}
}
parameterdialog(
self.window,
params,
title="选择日期格式",
callback=on_params_set
)
def remove_special_chars(self):
if self.data_handler.df is not none:
def on_params_set(params):
def on_columns_selected(columns):
self.process_in_background(
self.data_handler.remove_special_chars,
pattern=params["pattern"],
columns=columns
)
columnselector(
self.window,
list(self.data_handler.df.columns),
self.data_handler.get_column_types(),
title="选择要处理的列",
callback=on_columns_selected
)
params = {
"pattern": {
"type": "str",
"label": "正则表达式",
"default": r'[^\w\s]'
}
}
parameterdialog(
self.window,
params,
title="设置正则表达式",
callback=on_params_set
)
def fill_empty_values(self):
if self.data_handler.df is not none:
def on_params_set(params):
def on_columns_selected(columns):
value = params.get("value")
if params["method"] == "value" and value:
try:
# 尝试转换为数值
value = float(value) if '.' in value else int(value)
except valueerror:
pass
self.process_in_background(
self.data_handler.fill_empty_values,
method=params["method"],
value=value,
columns=columns
)
columnselector(
self.window,
list(self.data_handler.df.columns),
self.data_handler.get_column_types(),
title="选择要填充的列",
callback=on_columns_selected
)
params = {
"method": {
"type": "choice",
"label": "填充方式",
"default": "mean",
"choices": ["mean", "median", "mode", "ffill", "bfill", "value"]
},
"value": {
"type": "str",
"label": "填充值",
"default": ""
}
}
parameterdialog(
self.window,
params,
title="选择填充方式",
callback=on_params_set
)
def analyze_data(self):
if self.data_handler.df is not none:
analysis_window = toplevel(self.window)
analysis_window.title("数据分析")
analysis_window.geometry("600x400")
stats_text = scrolledtext(analysis_window, wrap=word, width=70, height=20)
stats_text.pack(padx=10, pady=10, fill=both, expand=true)
stats = []
stats.append("数据基本信息:")
stats.append("-" * 50)
stats.append(f"总行数:{len(self.data_handler.df)}")
stats.append(f"总列数:{len(self.data_handler.df.columns)}")
stats.append("\n数值列统计:")
stats.append("-" * 50)
numeric_stats = self.data_handler.df.describe()
stats.append(str(numeric_stats))
stats.append("\n空值统计:")
stats.append("-" * 50)
null_counts = self.data_handler.df.isnull().sum()
stats.append(str(null_counts))
stats_text.insert(end, "\n".join(stats))
stats_text.configure(state='disabled')
def visualize_data(self):
if self.data_handler.df is not none:
try:
import matplotlib.pyplot as plt
from matplotlib.backends.backend_tkagg import figurecanvastkagg
# 设置中文字体
plt.rcparams['font.sans-serif'] = ['simhei'] # 用来正常显示中文标签
plt.rcparams['axes.unicode_minus'] = false # 用来正常显示负号
viz_window = toplevel(self.window)
viz_window.title("数据可视化")
viz_window.geometry("800x600")
options_frame = ttk.frame(viz_window)
options_frame.pack(fill=x, padx=10, pady=5)
ttk.label(options_frame, text="图表类型:").pack(side=left)
chart_type = stringvar(value="bar")
ttk.radiobutton(options_frame, text="柱状图", variable=chart_type, value="bar").pack(side=left)
ttk.radiobutton(options_frame, text="折线图", variable=chart_type, value="line").pack(side=left)
ttk.radiobutton(options_frame, text="散点图", variable=chart_type, value="scatter").pack(side=left)
# 添加列选择
ttk.label(options_frame, text=" 选择列:").pack(side=left)
column_var = stringvar()
numeric_columns = list(self.data_handler.df.select_dtypes(include=[np.number]).columns)
if not numeric_columns:
messagebox.showwarning("警告", "没有可用的数值列进行可视化")
return
column_combo = ttk.combobox(options_frame, textvariable=column_var, values=numeric_columns)
column_combo.pack(side=left)
column_combo.set(numeric_columns[0])
fig, ax = plt.subplots(figsize=(10, 6))
canvas = figurecanvastkagg(fig, master=viz_window)
canvas.get_tk_widget().pack(fill=both, expand=true, padx=10, pady=5)
def update_chart():
try:
ax.clear()
chart_style = chart_type.get()
selected_column = column_var.get()
if not selected_column:
messagebox.showwarning("警告", "请选择要可视化的列")
return
if chart_style == "bar":
self.data_handler.df[selected_column].plot(kind='bar', ax=ax)
ax.set_title(f"{selected_column} 柱状图")
elif chart_style == "line":
self.data_handler.df[selected_column].plot(kind='line', ax=ax)
ax.set_title(f"{selected_column} 折线图")
else: # scatter
if len(numeric_columns) >= 2:
x_col = selected_column
y_col = next(col for col in numeric_columns if col != x_col)
self.data_handler.df.plot(kind='scatter', x=x_col, y=y_col, ax=ax)
ax.set_title(f"{x_col} vs {y_col} 散点图")
else:
messagebox.showwarning("警告", "需要至少两个数值列才能创建散点图")
return
plt.tight_layout()
canvas.draw()
except exception as e:
messagebox.showerror("错误", f"绘图时发生错误:{str(e)}")
ttk.button(options_frame, text="更新图表", command=update_chart).pack(side=left, padx=10)
update_chart()
except importerror:
messagebox.showwarning("警告", "请安装matplotlib库以使用可视化功能")
def run(self):
self.window.mainloop()
def create_menu(self):
menubar = menu(self.window)
self.window.config(menu=menubar)
# 文件菜单
file_menu = menu(menubar, tearoff=0)
menubar.add_cascade(label="文件", menu=file_menu)
file_menu.add_command(label="打开 (ctrl+o)", command=self.select_file)
file_menu.add_command(label="保存 (ctrl+s)", command=self.save_file)
file_menu.add_separator()
file_menu.add_command(label="退出", command=self.window.quit)
# 编辑菜单
edit_menu = menu(menubar, tearoff=0)
menubar.add_cascade(label="编辑", menu=edit_menu)
edit_menu.add_command(label="撤销 (ctrl+z)", command=self.undo)
edit_menu.add_command(label="重做 (ctrl+y)", command=self.redo)
# 视图菜单
view_menu = menu(menubar, tearoff=0)
menubar.add_cascade(label="视图", menu=view_menu)
view_menu.add_checkbutton(label="显示状态栏", command=self.toggle_status_bar)
# 帮助菜单
help_menu = menu(menubar, tearoff=0)
menubar.add_cascade(label="帮助", menu=help_menu)
help_menu.add_command(label="使用说明 (f1)", command=self.show_help)
help_menu.add_command(label="关于", command=self.show_about)
def create_file_frame(self, parent):
file_frame = ttk.labelframe(parent, text="文件操作", padding=10, style="card.tlabelframe")
file_frame.pack(fill=x, pady=(0, 10))
# 文件选择
self.file_path = stringvar()
ttk.label(file_frame, text="excel文件:", style="title.tlabel").pack(anchor=w)
ttk.entry(file_frame, textvariable=self.file_path, width=30).pack(fill=x, pady=5)
button_frame = ttk.frame(file_frame)
button_frame.pack(fill=x)
ttk.button(button_frame, text="浏览", command=self.select_file, style="tool.tbutton").pack(side=left, padx=2)
ttk.button(button_frame, text="保存", command=self.save_file, style="tool.tbutton").pack(side=left, padx=2)
def create_clean_frame(self, parent):
clean_frame = ttk.labelframe(parent, text="数据清洗", padding=10, style="card.tlabelframe")
clean_frame.pack(fill=both, expand=true)
operations = [
("删除重复行", self.remove_duplicates),
("删除空行", self.remove_empty_rows),
("去除空格", self.remove_spaces),
("统一大小写", self.normalize_case),
("数值格式化", self.format_numbers),
("日期格式化", self.format_dates),
("删除特殊字符", self.remove_special_chars),
("填充空值", self.fill_empty_values),
("数据分析", self.analyze_data),
("数据可视化", self.visualize_data)
]
for text, command in operations:
btn = ttk.button(clean_frame, text=text, command=command, style="tool.tbutton")
btn.pack(fill=x, pady=2)
def create_preview_frame(self, parent):
preview_frame = ttk.labelframe(parent, text="数据预览", padding=10, style="card.tlabelframe")
preview_frame.pack(fill=both, expand=true)
# 创建带滚动条的树形视图
tree_frame = ttk.frame(preview_frame)
tree_frame.pack(fill=both, expand=true)
# 创建水平滚动条
h_scrollbar = ttk.scrollbar(tree_frame, orient=horizontal)
h_scrollbar.pack(side=bottom, fill=x)
# 创建垂直滚动条
v_scrollbar = ttk.scrollbar(tree_frame)
v_scrollbar.pack(side=right, fill=y)
# 创建树形视图
self.tree = ttk.treeview(
tree_frame,
style="preview.treeview",
xscrollcommand=h_scrollbar.set,
yscrollcommand=v_scrollbar.set
)
self.tree.pack(fill=both, expand=true)
# 配置滚动条
h_scrollbar.config(command=self.tree.xview)
v_scrollbar.config(command=self.tree.yview)
# 创建统计信息面板
stats_frame = ttk.frame(preview_frame)
stats_frame.pack(fill=x, pady=(10, 0))
self.stats_label = ttk.label(stats_frame, text="", style="title.tlabel")
self.stats_label.pack(side=left)
def create_status_bar(self):
self.status_var = stringvar()
self.status_bar = ttk.label(
self.window,
textvariable=self.status_var,
relief=sunken,
padding=(5, 2)
)
self.status_bar.pack(fill=x, padx=5, pady=2)
def toggle_status_bar(self):
# 切换状态栏显示/隐藏
if self.status_bar.winfo_viewable():
self.status_bar.pack_forget()
else:
self.status_bar.pack(fill=x, padx=5, pady=2)
def update_preview(self):
# 清空现有数据
for item in self.tree.get_children():
self.tree.delete(item)
if self.data_handler.df is not none:
df = self.data_handler.df
# 设置列
self.tree["columns"] = list(df.columns)
self.tree["show"] = "headings"
for column in df.columns:
self.tree.heading(column, text=column)
self.tree.column(column, width=100, anchor='center')
# 添加数据(仅显示前100行)
for i, row in df.head(100).iterrows():
self.tree.insert("", end, values=list(row))
# 更新统计标签
stats = self.data_handler.get_statistics()
self.stats_label.config(
text=f"行数: {stats['row_count']} | 列数: {stats['column_count']}"
)
# 更新状态栏
self.status_var.set(
f"当前加载文件: {os.path.basename(self.file_path.get())} | "
f"行数: {stats['row_count']} | 列数: {stats['column_count']}"
)
else:
self.status_var.set("请先加载文件")
def show_help(self):
help_text = """
excel数据格式化批处理工具使用说明:
1. 文件操作:
- 点击"浏览"选择excel文件
- 点击"保存"保存处理后的文件
2. 数据清洗功能:
- 删除重复行:删除完全重复的数据行
- 删除空行:删除全为空值的行
- 去除空格:删除文本中的首尾空格
- 统一大小写:统一文本的大小写格式
- 数值格式化:统一数值的小数位数
- 日期格式化:统一日期的显示格式
- 删除特殊字符:清除文本中的特殊字符
- 填充空值:使用多种方式填充缺失值
3. 数据分析:
- 查看基本统计信息
- 空值分析
- 数据分布可视化
4. 快捷键:
- ctrl+o:打开文件
- ctrl+s:保存文件
- ctrl+z:撤销
- ctrl+y:重做
- f1:显示帮助
"""
help_window = toplevel(self.window)
help_window.title("使用说明")
help_window.geometry("600x400")
help_text_widget = scrolledtext(help_window, wrap=word, width=70, height=20)
help_text_widget.pack(padx=10, pady=10, fill=both, expand=true)
help_text_widget.insert(end, help_text)
help_text_widget.configure(state='disabled')
def show_about(self):
about_text = """
excel数据格式化批处理工具
功能特点:
- 支持多种数据清洗操作
- 实时预览数据变化
- 数据分析和可视化
- 后台处理,避免卡顿
- 撤销/重做功能
- 友好的图形界面
"""
messagebox.showinfo("关于", about_text)
if __name__ == "__main__":
try:
app = excelcleaner()
app.run()
except exception as e:
logging.error(f"程序运行错误: {str(e)}")
messagebox.showerror("错误", f"程序运行出错:{str(e)}")
# 优化的代码,运行即出现gui界面
9.总结
excel格式化批处理工具是数据分析和日常办公中不可或缺的步骤。本工具提供了一系列高效的功能,帮助用户快速整理数据,提升数据质量。无论是数据分析师还是日常办公人员,都可以借助该工具提高工作效率,减少数据整理的繁琐工作。希望本篇指南能帮助大家更好地利用工具,提高数据处理能力!
以上就是使用python实现exce格式化批处理工具的详细内容,更多关于python exce格式化的资料请关注代码网其它相关文章!






发表评论