本文介绍如何使用aws lambda函数将s3存储桶中的json数据加载到dynamodb表中。
先决条件:
- 拥有向s3上传对象的权限。
- 拥有s3和dynamodb权限的lambda执行角色。
架构和组件:
本方案使用三个aws服务:
- s3存储桶: 作为可扩展、安全、高性能的对象存储服务,用于存储数据。
- lambda函数: 无服务器计算服务,用于运行代码并处理数据,无需管理基础设施。支持多种编程语言,易于设置。
- dynamodb: 无服务器nosql数据库,用于存储lambda函数处理后的数据。
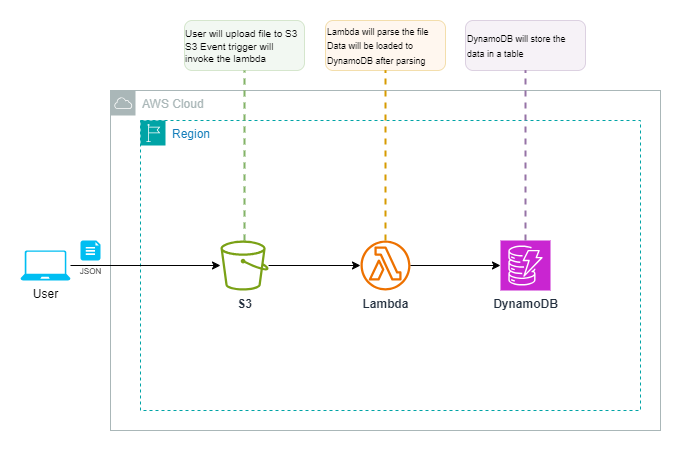
工作流程:
- 用户通过控制台或cli使用putobject api将json文件上传到s3存储桶。
- 文件上传成功后,触发s3事件,调用lambda函数进行数据加载和处理。
- lambda函数处理数据并将其加载到dynamodb表中。
实施步骤:
以下步骤详细说明如何部署和配置上述架构:
1. 创建lambda函数:
- 函数名称:parserdemo
- 运行时:python 3.1x (或其他支持的运行时)
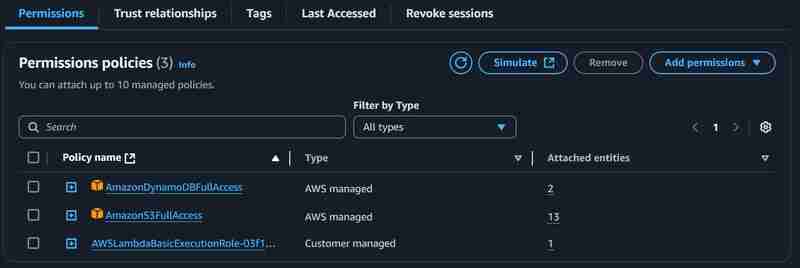
其他设置保持默认值。创建函数后,修改超时配置和执行角色,如下所示:

以下python代码实现数据处理逻辑:
import json
import boto3
s3_client = boto3.client('s3')
dynamodb = boto3.resource('dynamodb')
def lambda_handler(event, context):
bucket_name = event['records'][0]['s3']['bucket']['name']
object_key = event['records'][0]['s3']['object']['key']
print(f"bucket: {bucket_name}, key: {object_key}")
response = s3_client.get_object(bucket=bucket_name, key=object_key)
json_data = response['body'].read()
string_formatted = json_data.decode('utf-8')
dict_format_data = json.loads(string_formatted)
table = dynamodb.table('demotable')
if isinstance(dict_format_data, list):
for record in dict_format_data:
table.put_item(item=record)
elif isinstance(dict_format_data, dict):
table.put_item(item=dict_format_data)
else:
raise valueerror("unsupported format")
登录后复制
2. 创建s3存储桶:
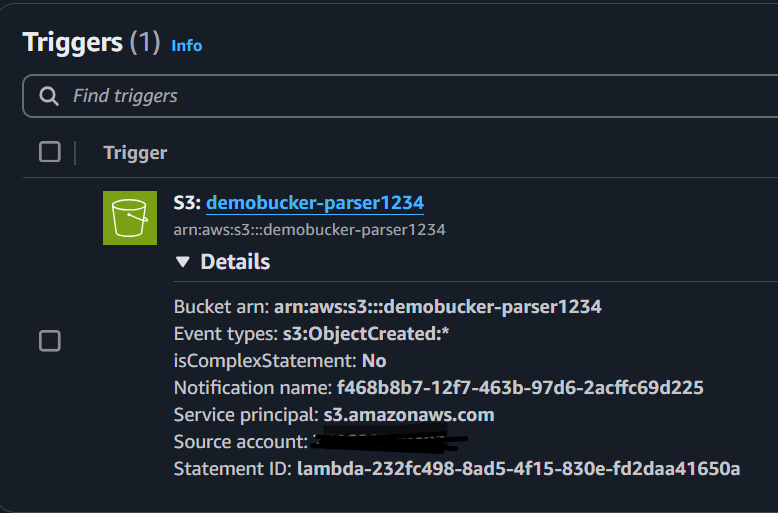
桶名称:使用唯一名称。其他设置保持默认值。将创建的s3存储桶作为触发器添加到lambda函数:
3. 创建dynamodb表:
- 表名称:demotable
- 分区键:userid
- 表设置:自定义
- 容量模式:预配置
为了降低成本,将预配置容量单位设置为较低的读/写单位(例如1或2个单位)。
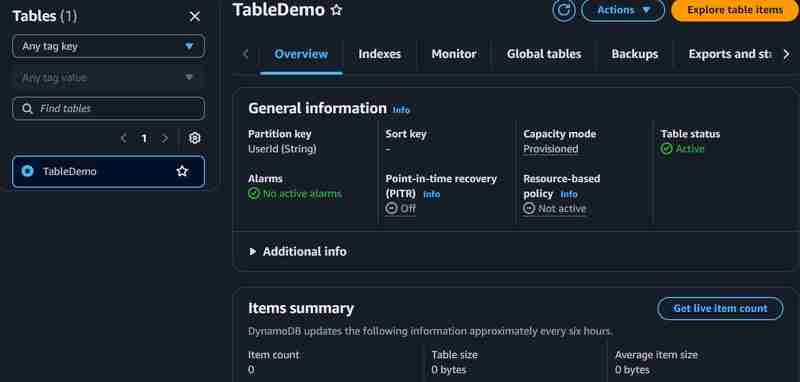
完成设置后,上传文件到s3进行测试。您可以在dynamodb表中查看已创建的项目和上传的记录。 lambda函数的cloudwatch日志和dynamodb项目如下所示:
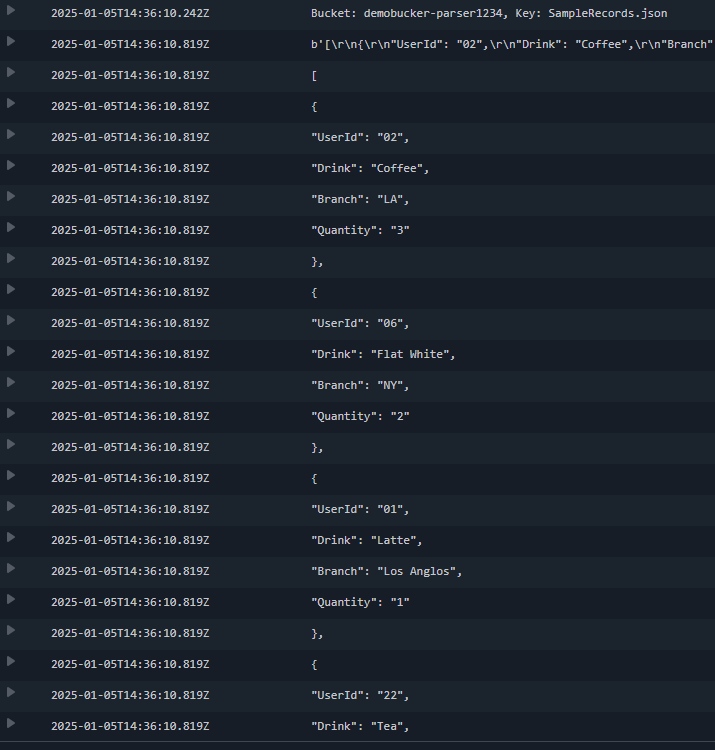
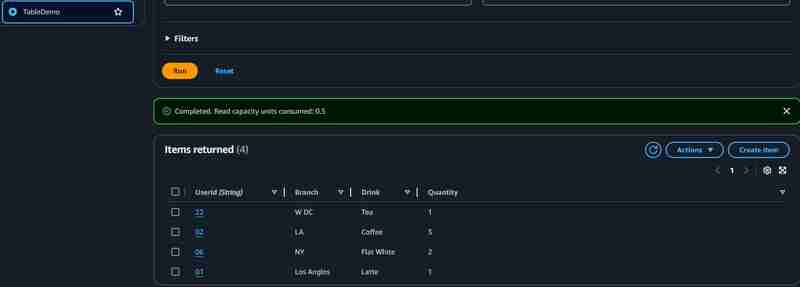
参考:
- s3 api
- dynamodb api
- boto3 for aws services
希望此指南对您有所帮助。如有任何疑问,请提出。
以上就是使用 lambda 函数从 so dynamodb 解析和加载数据的详细内容,更多请关注代码网其它相关文章!




发表评论