一、问题重现
我们先通过如下这个简单的例子来重现上述这个问题。如代码片段所示,我们定义了一个名为point(代表二维坐标点)的只读结构体作为待序列化字典的key。point可以通过结构化的表达式来表示,我们同时还定义了parse方法将表达式转换成point对象。
using system.diagnostics;
using system.text.json;
var dictionary = new dictionary<point, int>
{
{ new point(1.0, 1.0), 1 },
{ new point(2.0, 2.0), 2 },
{ new point(3.0, 3.0), 3 }
};
try
{
var json = jsonserializer.serialize(dictionary);
console.writeline(json);
var dictionary2 = jsonserializer.deserialize<dictionary<point, int>>(json)!;
debug.assert(dictionary2[new point(1.0, 1.0)] == 1);
debug.assert(dictionary2[new point(2.0, 2.0)] == 2);
debug.assert(dictionary2[new point(3.0, 3.0)] == 3);
}
catch (exception ex)
{
console.writeline(ex.message);
}
public readonly record struct point(double x, double y)
{
public override string tostring()=> $"({x}, {y})";
public static point parse(string s)
{
var tokens = s.trim('(',')').split(',', stringsplitoptions.trimentries);
if (tokens.length != 2)
{
throw new formatexception("invalid format");
}
return new point(double.parse(tokens[0]), double.parse(tokens[1]));
}
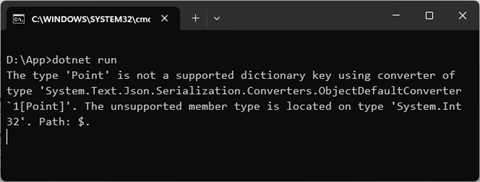
}当我们使用jsonserializer序列化多一个dictionary<point, int>类型的对象时,会抛出一个notsupportedexception异常,如下所示的信息解释了错误的根源:point类型不能作为被序列化字典对象的key。顺便说一下,如果使用newtonsoft.json,这样的字典可以序列化成功,但是反序列化会失败。
二、自定义jsonconverter<point>能解决吗
遇到这样的问题我们首先想到的是:既然不执行针对point的序列化/反序列化,那么我们可以对应相应的jsonconverter自行完成序列化/反序列化工作。为此我们定义了如下这个pointconverter,将point的表达式作为序列化输出结果,同时调用parse方法生成反序列化的结果。
public class pointconverter : jsonconverter<point>
{
public override point read(ref utf8jsonreader reader, type typetoconvert, jsonserializeroptions options)=> point.parse(reader.getstring()!);
public override void write(utf8jsonwriter writer, point value, jsonserializeroptions options) => writer.writestringvalue(value.tostring());
}我们将这个pointconverter对象添加到创建的jsonserializeroptions配置选项中,并将后者传入序列化和反序列化方法中。
var options = new jsonserializeroptions
{
writeindented = true,
converters = { new pointconverter() }
};
var json = jsonserializer.serialize(dictionary, options);
console.writeline(json);
var dictionary2 = jsonserializer.deserialize<dictionary<point, int>>(json, options)!;
debug.assert(dictionary2[new point(1.0, 1.0)] == 1);
debug.assert(dictionary2[new point(2.0, 2.0)] == 2);
debug.assert(dictionary2[new point(3.0, 3.0)] == 3);不幸的是,这样的解决方案无效,序列化时依然会抛出相同的异常。

三、自定义typeconverter能解决问题吗
jsonconverter的目的本质上就是希望将point对象视为字符串进行处理,既然自定义jsonconverter无法解决这个问题,我们是否可以注册相应的类型转换其来解决它呢?为此我们定义了如下这个pointtypeconverter 类型,使它来完成针对point和字符串之间的类型转换。
public class pointtypeconverter : typeconverter
{
public override bool canconvertfrom(itypedescriptorcontext? context, type sourcetype) => sourcetype == typeof(string);
public override bool canconvertto(itypedescriptorcontext? context, type? destinationtype) => destinationtype == typeof(string);
public override object convertfrom(itypedescriptorcontext? context, cultureinfo? culture, object value) => point.parse((string)value);
public override object convertto(itypedescriptorcontext? context, cultureinfo? culture, object? value, type destinationtype) => value?.tostring()!;
}我们利用标注的typeconverterattribute特性将pointtypeconverter注册到point类型上。
[typeconverter(typeof(pointtypeconverter))]
public readonly record struct point(double x, double y)
{
public override string tostring() => $"({x}, {y})";
public static point parse(string s)
{
var tokens = s.trim('(',')').split(',', stringsplitoptions.trimentries);
if (tokens.length != 2)
{
throw new formatexception("invalid format");
}
return new point(double.parse(tokens[0]), double.parse(tokens[1]));
}
}实验证明,这种解决方案依然无效,序列化时还是会抛出相同的异常。顺便说一下,这种解决方案对于newtonsoft.json是适用的。
四、以键值对集合的形式序列化
为point定义jsonconverter之所以不能解决我们的问题,是因为异常并不是在试图序列化point对象时抛出来的,而是在在默认的规则序列化字典对象时,不合法的key类型没有通过验证。如果希望通过自定义jsonconverter的方式来解决,目标类型不应该时point类型,而应该时字典类型,为此我们定义了如下这个pointkeyeddictionaryconverter<tvalue>类型。
我们知道字典本质上就是键值对的集合,而集合针对元素类型并没有特殊的约束,所以我们完全可以按照键值对集合的方式来进行序列化和反序列化。如代码把片段所示,用于序列化的write方法中,我们利用作为参数的jsonserializeroptions 得到针对ienumerable<keyvaluepair<point, tvalue>>类型的jsonconverter,并利用它以键值对的形式对字典进行序列化。
public class pointkeyeddictionaryconverter<tvalue> : jsonconverter<dictionary<point, tvalue>>
{
public override dictionary<point, tvalue>? read(ref utf8jsonreader reader, type typetoconvert, jsonserializeroptions options)
{
var enumerableconverter = (jsonconverter<ienumerable<keyvaluepair<point, tvalue>>>)options.getconverter(typeof(ienumerable<keyvaluepair<point, tvalue>>));
return enumerableconverter.read(ref reader, typeof(ienumerable<keyvaluepair<point, tvalue>>), options)?.todictionary(kvp => kvp.key, kvp => kvp.value);
}
public override void write(utf8jsonwriter writer, dictionary<point, tvalue> value, jsonserializeroptions options)
{
var enumerableconverter = (jsonconverter<ienumerable<keyvaluepair<point, tvalue>>>)options.getconverter(typeof(ienumerable<keyvaluepair<point, tvalue>>));
enumerableconverter.write(writer, value, options);
}
}用于反序列化的read方法中,我们采用相同的方式得到这个针对ienumerable<keyvaluepair<point, tvalue>>类型的jsonconverter,并将其反序列化成键值对集合,在转换成返回的字典。
var options = new jsonserializeroptions
{
writeindented = true,
converters = { new pointconverter(), new pointkeyeddictionaryconverter<int>()}
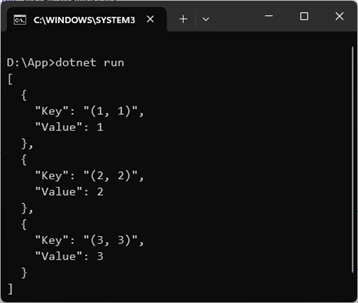
};我们将pointkeyeddictionaryconverter<int>添加到创建的jsonserializeroptions配置选项的jsonconverter列表中。从如下所示的输出结果可以看出,我们创建的字典确实是以键值对集合的形式进行序列化的。
五、转换成合法的字典
既然作为字典key的point可以转换成字符串,那么可以还有另一种解法,那就是将以point为key的字典转换成以字符串为key的字典,为此我们按照如下的方式重写的pointkeyeddictionaryconverter<tvalue>。如代码片段所示,重写的writer方法利用传入的jsonserializeroptions配置选项得到针对dictionary<string, tvalue>的jsonconverter,然后将待序列化的dictionary<point, tvalue> 对象转换成dictionary<string, tvalue> 交给它进行序列化。
public class pointkeyeddictionaryconverter<tvalue> : jsonconverter<dictionary<point, tvalue>>
{
public override dictionary<point, tvalue>? read(ref utf8jsonreader reader, type typetoconvert, jsonserializeroptions options)
{
var converter = (jsonconverter<dictionary<string, tvalue>>)options.getconverter(typeof(dictionary<string, tvalue>))!;
return converter.read(ref reader, typeof(dictionary<string, tvalue>), options)
?.todictionary(kv => point.parse(kv.key), kv=> kv.value);
}
public override void write(utf8jsonwriter writer, dictionary<point, tvalue> value, jsonserializeroptions options)
{
var converter = (jsonconverter<dictionary<string, tvalue>>)options.getconverter(typeof(dictionary<string, tvalue>))!;
converter.write(writer, value.todictionary(kv => kv.key.tostring(), kv => kv.value), options);
}
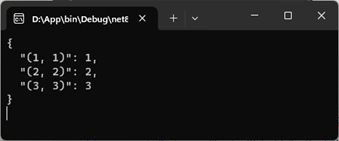
}重写的read方法采用相同的方式得到jsonconverter<dictionary<string, tvalue>>对象,并利用它执行反序列化生成dictionary<string, tvalue> 对象。我们最终将它转换成需要的dictionary<point, tvalue> 对象。从如下所示的输出可以看出,这次的序列化生成的json会更加精炼,因为这次是以字典类型输出json字符串的。
六、自定义读写
虽然以上两种方式都能解决我们的问题,而且从最终json字符串输出的长度来看,第二种具有更好的性能,但是它们都有一个问题,那么就是需要创建中间对象。第一种方案需要创建一个键值对集合,第二种方案则需要创建一个dictionary<string, tvalue> 对象,如果对性能有更高的追求,它们都不是一种好的解决方案。既让我们都已经在自定义jsonconverter,完全可以自行可控制json内容的读写,为此我们再次重写了pointkeyeddictionaryconverter<tvalue>。
public class pointkeyeddictionaryconverter<tvalue> : jsonconverter<dictionary<point, tvalue>>
{
public override dictionary<point, tvalue>? read(ref utf8jsonreader reader, type typetoconvert, jsonserializeroptions options)
{
jsonconverter<tvalue>? valueconverter = null;
dictionary<point, tvalue>? dictionary = null;
while (reader.read())
{
if (reader.tokentype == jsontokentype.endobject)
{
return dictionary;
}
valueconverter ??= (jsonconverter<tvalue>)options.getconverter(typeof(tvalue))!;
dictionary ??= [];
var key = point.parse(reader.getstring()!);
reader.read();
var value = valueconverter.read(ref reader, typeof(tvalue), options)!;
dictionary.add(key, value);
}
return dictionary;
}
public override void write(utf8jsonwriter writer, dictionary<point, tvalue> value, jsonserializeroptions options)
{
writer.writestartobject();
jsonconverter<tvalue>? valueconverter = null;
foreach (var (k, v) in value)
{
valueconverter ??= (jsonconverter<tvalue>)options.getconverter(typeof(tvalue))!;
writer.writepropertyname(k.tostring());
valueconverter.write(writer, v, options);
}
writer.writeendobject();
}
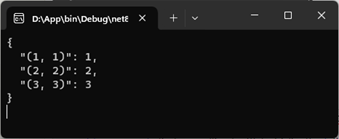
}如上面的代码片段所示,在重写的write方法中,我们调用utf8jsonwriter 的writestartobject和 writeendobject方法以对象的形式输出字典。在这中间,我们便利字典的每个键值对,并以“属性”的形式对它们进行输出(key和value分别是属性名和值)。在read方法中,我们创建一个空的dictionary<point, tvalue> 对象,在一个循环中利用utf8jsonreader先后读取作为key的字符串和value值,最终将key转换成point类型,并添加到创建的字典中。从如下所示的输出结果可以看出,这次生成的json具有与上面相同的结构。
以上就是c#自定义key类型的字典无法序列化的解决方案详解的详细内容,更多关于c#字典无法序列化的资料请关注代码网其它相关文章!




发表评论