moshivis:一款开源多模态语音模型,赋能语音与视觉交互
kyutai推出的开源多模态语音模型moshivis,在实时对话语音模型moshi的基础上,集成了视觉输入功能,实现了图像的自然、实时语音交互。它巧妙地融合了语音和视觉信息,让用户仅通过语音就能与模型轻松交流图像内容。
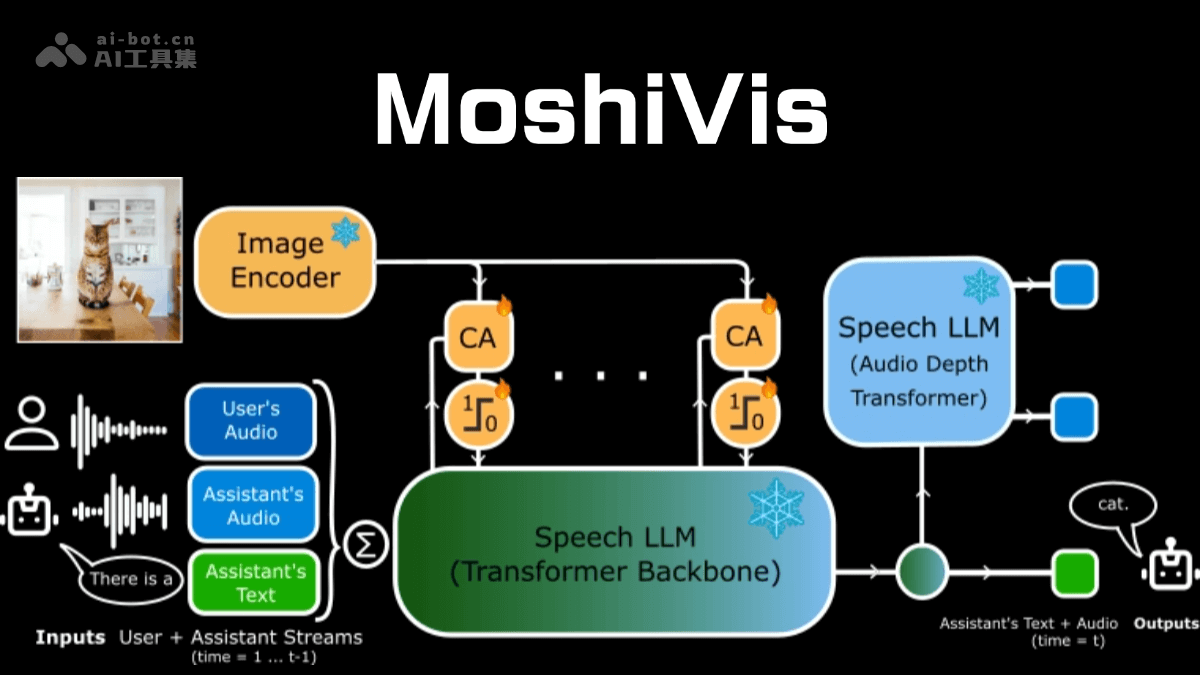
核心功能:
- 图像理解与语音交互: moshivis能够接收图像输入并结合语音指令,理解图像中的场景、物体和人物等信息。
- 实时响应,流畅对话: 支持实时语音交互,用户可自然流畅地与模型对话,无需等待。
- 多模态信息融合: 采用跨注意力机制,将视觉和语音信息无缝融合,实现真正意义上的多模态理解。
- 低延迟,自然表达: 在处理图像和语音时保持低延迟,并继承了moshi的自然对话风格,确保交互体验流畅自然。
- 多后端支持: 兼容pytorch、rust和mlx三种后端,并推荐使用web ui前端进行交互。
- 无障碍应用潜力: moshivis在无障碍ai领域具有巨大潜力,可辅助视障人士理解视觉场景。
技术原理:
moshivis的核心技术在于其高效的多模态融合和动态门控机制:
- 轻量级交叉注意力模块: 该模块将视觉编码器的图像特征信息注入到moshi的语音标记流中,实现语音与图像内容的实时交互。
- 动态门控机制: 通过动态调整视觉信息的影响力,moshivis能够根据对话上下文灵活切换视觉信息的使用,从而提高对话的自然性和流畅性,避免视觉信息干扰非视觉主题的讨论。
- 参数高效微调: 采用单阶段、参数高效的微调流程,利用图像-文本和图像-语音样本的混合数据进行训练,降低训练成本并提高模型的适应性。
项目信息:
- 项目官网: kyutai.org/moshivis
- github仓库: https://www.php.cn/link/c314d02582ee0c4cc460ea3e470bb4d4
- arxiv技术论文: https://www.php.cn/link/c314d02582ee0c4cc460ea3e470bb4d4
应用前景:
moshivis的应用场景广泛,涵盖:
- 老年人辅助: 帮助老年人识别物品、阅读文字和获取环境信息。
- 智能家居控制: 通过语音指令控制智能家居设备。
- 辅助学习: 辅助学生通过语音交互学习图像内容。
- 社交媒体互动: 为图片生成语音描述或评论。
- 工业质检: 辅助工人通过语音交互进行设备检查和故障识别。
moshivis凭借其强大的多模态融合能力和高效的运行效率,有望在众多领域发挥重要作用,为用户带来更便捷、更智能的交互体验。
以上就是moshivis— kyutai 开源的多模态实时语音模型的详细内容,更多请关注代码网其它相关文章!




发表评论