2、案例cpu丨intel ultra 7 265k
简介:intel平台的读写会比amd平台强很多,相同内存在amd锐龙平台的读取和拷贝正常只有六七成速度,ai生产环境还是尽量选intel吧。

intel ultra200s被诟病不少,但单说跑ai工具会比酷睿更合适一些,毕竟自带独立的npu,支持的应用也不少,单机整体算力和实用性更强。

3、案例主板丨技嘉小雕z890m aorus elite wifi7
简介:在之前的文章分享过技嘉微星的内存调试教程,御三家主板的bios都有一键优化内存小参的功能,并且确实好用,可以大幅减少手动调试的时间。

调试流程
内存是比较容易忽视的硬件,不然大家也不会点进来看这篇文章,所以说的细一些。
1、物理安装
一般家用主板有四根内存插槽,不算太冷门的知识点如下:
- 如果暂时只插两根,插二四槽位(从左往右),不然可能会不稳定(过不了压力测试)。
- 如果是已有两根内存在用,后期加装尽量买同款,主要是颗粒、频率和时序要相同,新老款的jedec预设可能不一样。
另外初次装机时候,如果出现能过自检但过不了压力测试的问题,建议先检查下cpu是否正确安装,接触不良可能会导致稳不住。

2、bios调试
只要是近几年出的平台,首次装机都是进bios进行以下两步调试:
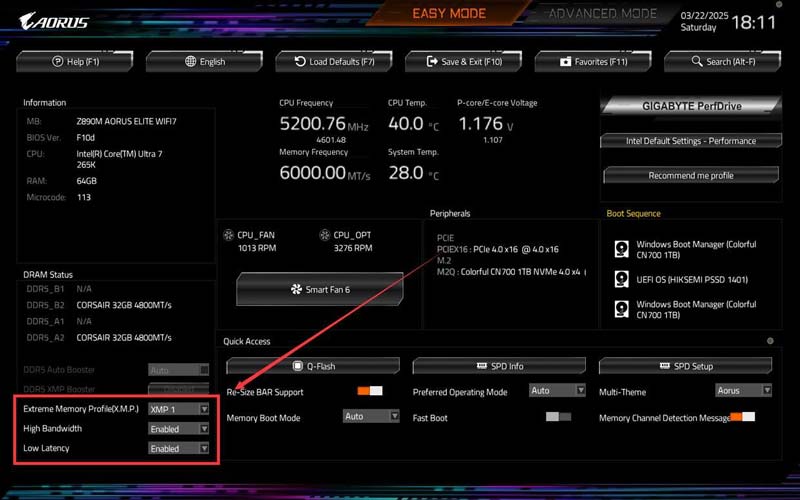
- 第一步,在bios首页找到内存预设,intel开启xmp功能,amd则是开启expo功能,这一步是将预设从jedec切换至内存厂商预设,不开启效能会低很多。
- 第二步,如果是御三家主板,手动开启自动调小参功能,技嘉是high bandwidth+low latency,微星是benchmark mode,华硕是ai tweaker。
第二步特指御三家主板,其他二三线主板暂无类似功能。
手动超频得看cpu的imc体质,说一下近三代平台ddr5内存比较容易达成的数据:
- z890平台一般双内存(指16g和24g单条)轻松上8000mhz+c36,四内存(含双条32g和双条64g)能到6000mhz+c30。
- z790平台则是双内存(指16g和24g单条)轻松上7200mhz+c34,四内存(含双条32g和双条64g)能到6000mhz+c30。
- 四条32g和48g一般只能稳定5600mhz。
当然这里给的数据不是绝对的,得看cpu体质+主板支持,一般也不建议生产力环境做手动超频就是了。

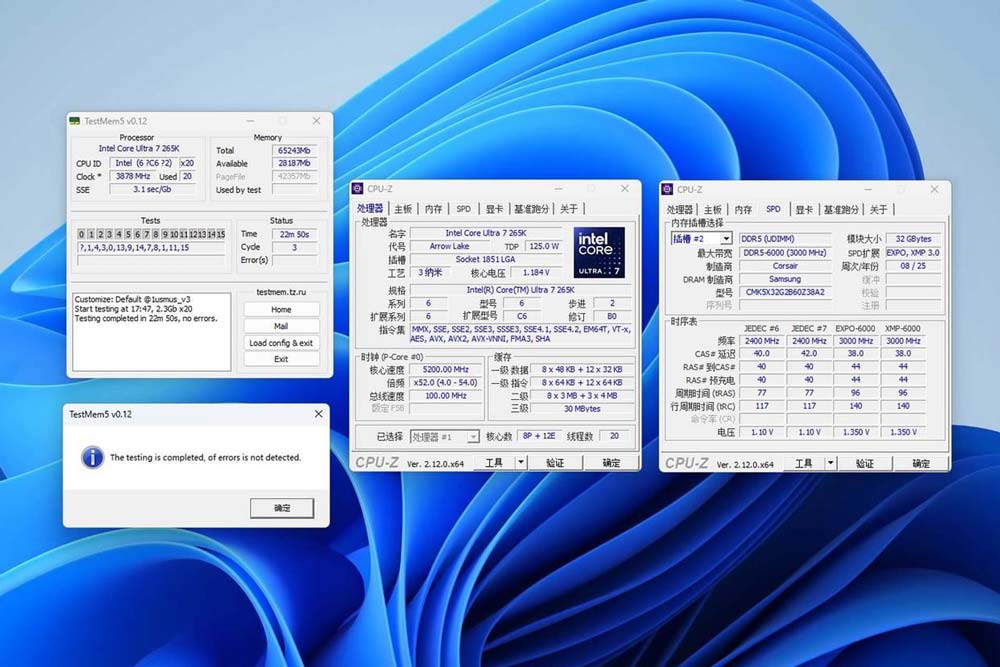
3、验证稳定性
只要是商用,投入正式使用前都一定要做压力测试,主要测试内存满载状态是否会报错,一般用tm5或者memtest这类工具加载专用脚本,跑完无报错不死机就行,当然海盗船复仇者这种在qvl上的型号一般不需要压力测试,内存厂和主板厂已经联调过了。
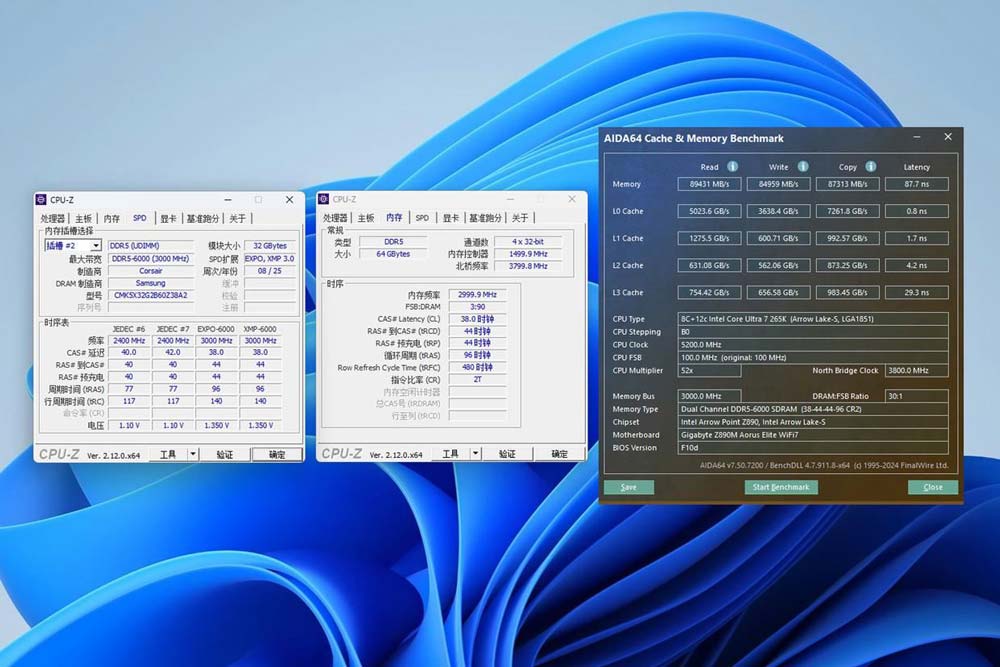
验证完稳定性建议跑一次aida64的内存测试,看看延迟和读写数据是否正常,给大家说一下正常数据水平:
- 13代和14代intel酷睿平台+使用御三家主板,6000mhz+c38的读写正常在90gb/s左右,延迟正常应该在70ns以内。
- 13代和14代intel酷睿平台+使用御三家主板,7200mhz+c40的读写正常在110gb/s左右,延迟正常应该在70ns以内。
- intel ultra200s平台+使用御三家主板,6000mhz+c38的读写正常在90gb/s左右,延迟正常应该在90ns以内。
- intel ultra200s平台+使用御三家主板,7200mhz+c40的读写正常在110gb/s左右,延迟正常应该在90ns以内。
非御三家主板没有自动优化小参功能,数据会比这里的参考数据低约10-20%左右。
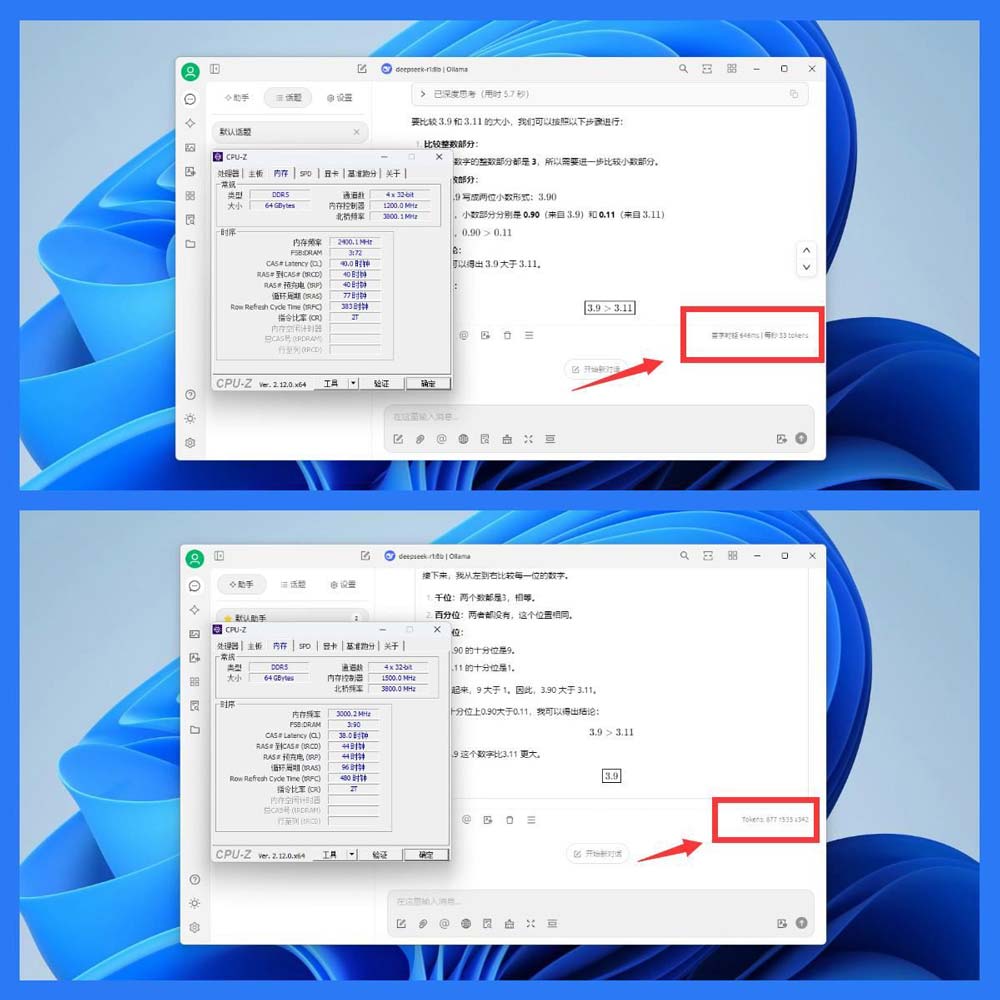
4、评估ai推理效率
比对不同内存对deepseek推理效率的影响比较简单,使用cherry studio等图形化工具直接跑相同问题就行,比如我这里的数据如下:
- 4800mhz频率下,首字延时为646ms,每秒33token。
- 6000mhz频率下,首字延时为617ms,每秒34token。
所以可以得出结论,使用更高效能的内存确实可以一定程度提升推理效率,单次虽然不多,但累计起来真能省下不少时间。
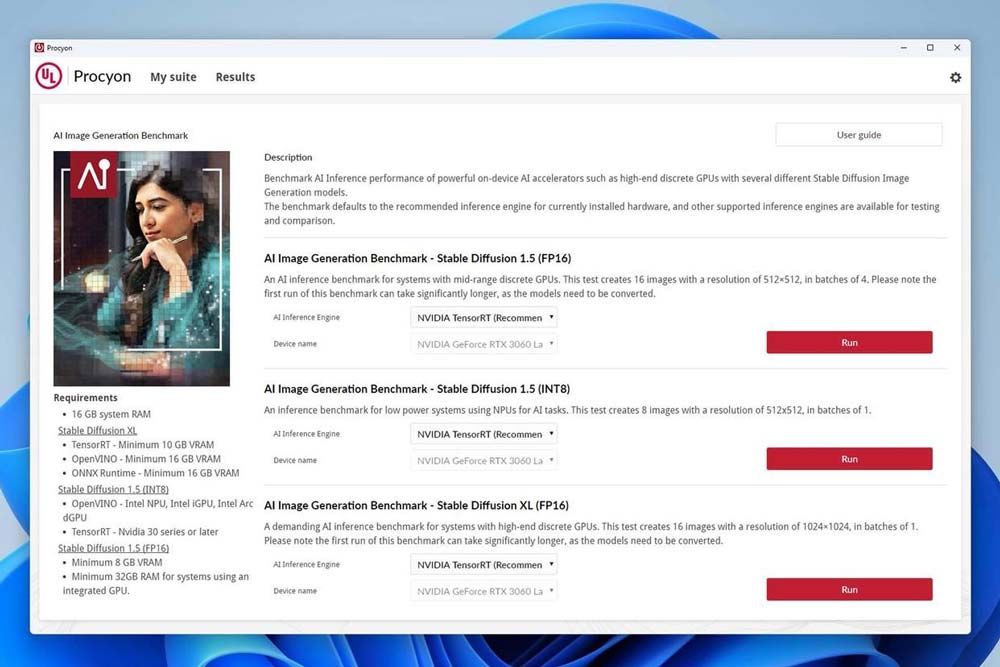
如果打算一机多用跑其他ai工具,建议是使用3dmark母公司旗下的ulprocyon做量化测试,这款工具我现在评测也在用,方便量化硬件升级在不同场景下能带来多少提升。
汇总总结
最后给大家收个尾,圈一下购买使用中需要注意的点:
- 采购内存尽量单根大点,懒得折腾就在主板厂商官方给的qvl清单中选,非qvl认证的内存+四根插满,一定要做压力测试再正式当生产力工具使用。
- 物理安装内存优先2/4槽位,别乱插,四根插满随意,首次装机记得开xmp(amd是expo),御三家把自动优化功能启用。
- 不知道换内存能有多少提升,deepseek用户直接随便跑个复杂点的问题,看推理数据统计进行比对,大批量采购建议用ulprocyon做量化测试。

发表评论