在数据分析中,经常会遇到数据集中始终具有常量值的列(即,该列中的所有行包含相同的值)。这样的常量列不提供有意义的信息,可以安全地删除而不影响分析。
如:
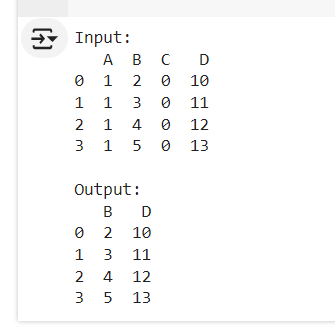
在本文中,我们将探索如何使用python识别和删除pandas dataframe中的常量列。
为什么要删除常量列?
常数列不提供可变性,这意味着它们无助于区分不同的数据点。在许多机器学习模型中,这些列会引入冗余或不相关的数据,从而对性能产生负面影响。因此,通常必须删除常量列,以便:
- 减少数据集的维数。
- 提高计算效率。
- 增强模型的可解释性。
步骤1:在pandas中识别常量列
pandas提供了几种识别和删除常量列的方法。我们可以检查唯一值的数量正好为1的列。
.nunique()函数在这方面特别有用,因为它返回每列中不同元素的数量。
import pandas as pd
# sample dataframe with constant and non-constant columns
data = {
'a': [1, 1, 1, 1],
'b': [2, 3, 4, 5],
'c': ['x', 'x', 'x', 'x'],
'd': [10, 11, 12, 13]
}
df = pd.dataframe(data)
# identify constant columns
constant_columns = [col for col in df.columns if df[col].nunique() == 1]
# display constant columns
print("constant columns:", constant_columns)
输出
constant columns: ['a', 'c']
在这种情况下,列a和列c被标识为常量,因为它们只有一个唯一值。
步骤2:删除常量列
一旦我们确定了常量列,我们就可以使用pandas中的.drop()函数轻松删除它们。
# drop constant columns df_cleaned = df.drop(columns=constant_columns) # display the cleaned dataframe print(df_cleaned)
输出
b d 0 2 10 1 3 11 2 4 12 3 5 13
在这里,清理后的dataframe已删除常量列a和c。
步骤3:删除较大数据集中的常量列
让我们考虑一个更大的数据集,其中某些列可能具有常量值。
import numpy as np
# create a dataframe with random and constant columns
data = {
'x1': np.random.randint(0, 100, size=100),
'x2': [5] * 100, # constant column
'x3': np.random.randint(0, 100, size=100),
'x4': [3] * 100, # constant column
}
df_large = pd.dataframe(data)
# remove constant columns in the larger dataset
constant_columns = [col for col in df_large.columns if df_large[col].nunique() == 1]
df_large_cleaned = df_large.drop(columns=constant_columns)
print("original dataframe shape:", df_large.shape)
print(df_large.head())
print("cleaned dataframe shape:", df_large_cleaned.shape)
print(df_large_cleaned.head())
输出

在本例中,删除了常量列x2和x4,在清理后的dataframe中只留下x1和x3。
处理特殊情况
- 空dataframe:如果dataframe为空,则删除常量列无效,函数应返回原始dataframe。
- 包含缺失值的列:如果所有非缺失值都相同,则包含缺失值(na)的列仍可以被视为常数。您可以使用占位符(例如,fillna())之前确定常数列。
总结
从数据集中删除常量列是数据预处理的关键步骤,特别是在机器学习和数据分析中处理大型数据集时。在这篇文章中,我们有:
- 定义了常数列,并解释了它们在分析中缺乏意义。
- 展示了使用pandas识别和删除常量列的多种方法。
- 提供了示例,包括在较大的数据集中删除常量列和处理特殊情况(如丢失数据)。
通过有效地删除这些冗余列,我们可以提高模型的性能并简化分析。
到此这篇关于详解如何在pandas中删除常量列的文章就介绍到这了,更多相关pandas删除常量列内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论