当计算机学会“看”数字
在人工智能的世界里,计算机视觉是最具魅力的领域之一。通过pytorch这一强大的深度学习框架,我们将在经典的mnist数据集上,见证一个神经网络从零开始学会识别数字的全过程。本文将以通俗易懂的方式,带你走进这个看似神秘实则充满逻辑的美妙世界。
搭建开发环境
在开始训练之前,我们需要准备好三个基础要素:腾讯云hai,腾讯云hai,腾讯云hai。导入必要的工具库:
import torch # 深度学习框架核心 import torch.nn as nn # 神经网络模块 from torchvision import datasets, transforms # 数据处理利器
mnist数据集解析
1. 认识手写数字数据库
mnist数据集包含6万张训练图片和1万张测试图片,每张都是28x28像素的灰度图。这些数字由美国高中生和人口普查局员工书写,构成了计算机视觉领域的"hello world"。
2. 数据预处理的艺术
原始图片需要经过精心处理才能被模型理解:
transform = transforms.compose([
transforms.totensor(), # 将图像转换为数值矩阵
transforms.normalize((0.1307,), (0.3081,)) # 标准化处理
])
3. 可视化的重要性
通过matplotlib展示样本图片,我们能直观感受数据的特征:
plt.imshow(images[0].squeeze(), cmap='gray')
plt.title(f'label: {labels[0]}')
神经网络设计
1. 网络结构蓝图
我们设计一个全连接网络(fcn),其结构如同人类神经系统的简化版:
class net(nn.module):
def __init__(self):
super().__init__()
self.flatten = nn.flatten() # 将图片展开为向量
self.fc1 = nn.linear(28*28, 128) # 第一隐藏层
self.fc2 = nn.linear(128, 64) # 第二隐藏层
self.fc3 = nn.linear(64, 10) # 输出层
self.dropout = nn.dropout(0.5) # 正则化装置
- 神经元数量的选择需要平衡学习能力与过拟合风险
- dropout层像随机关闭部分神经元,防止模型"死记硬背"
2. 信息传递机制
前向传播模拟人脑的信息处理过程:relu激活函数如同神经元的开关,决定是否传递信号。
def forward(self, x):
x = self.flatten(x) # 展平操作:将图片变为784维向量
x = torch.relu(self.fc1(x)) # 通过第一个全连接层
x = self.dropout(x) # 随机屏蔽部分神经元
x = torch.relu(self.fc2(x)) # 第二个全连接层
return self.fc3(x) # 最终输出10个数字的概率
让模型学会思考
1. 配置学习参数
- 损失函数:交叉熵损失(crossentropyloss),衡量预测与真实的差距
- 优化器:adam优化器,智能调节学习步伐的导航员
criterion = nn.crossentropyloss() optimizer = optim.adam(model.parameters(), lr=0.001)
2. 训练循环解析
每个epoch都是一次完整的学习轮回:
def train(epoch):
model.train() # 切换至训练模式
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad() # 清空之前的梯度
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失值
loss.backward() # 反向传播求梯度
optimizer.step() # 更新网络参数
- 梯度清零避免不同批次数据的干扰
- 反向传播就像纠错老师,沿着计算链修正参数
完整代码示例
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import transforms
import matplotlib.pyplot as plt
# 2. 数据准备
# 定义数据预处理:转换为tensor并标准化(mnist的均值和标准差)
transform = transforms.compose([
transforms.totensor(),
transforms.normalize((0.1307,), (0.3081,))
])
# 加载训练集和测试集
train_dataset = torchvision.datasets.mnist(
root='./data',
train=true,
download=true,
transform=transform
)
test_dataset = torchvision.datasets.mnist(
root='./data',
train=false,
transform=transform
)
# 创建数据加载器
train_loader = torch.utils.data.dataloader(
train_dataset,
batch_size=64,
shuffle=true
)
test_loader = torch.utils.data.dataloader(
test_dataset,
batch_size=1000,
shuffle=false
)
# 查看数据集信息
print(f'train samples: {len(train_dataset)}')
print(f'test samples: {len(test_dataset)}')
# 可视化样本
images, labels = next(iter(train_loader))
plt.imshow(images[0].squeeze(), cmap='gray')
plt.title(f'label: {labels[0]}')
plt.show()
# 3. 定义神经网络模型
class net(nn.module):
def __init__(self):
super(net, self).__init__()
self.flatten = nn.flatten()
self.fc1 = nn.linear(28*28, 128)
self.fc2 = nn.linear(128, 64)
self.fc3 = nn.linear(64, 10)
self.dropout = nn.dropout(0.5)
def forward(self, x):
x = self.flatten(x)
x = torch.relu(self.fc1(x))
x = self.dropout(x)
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
model = net()
print(model)
# 4. 定义损失函数和优化器
criterion = nn.crossentropyloss()
optimizer = optim.adam(model.parameters(), lr=0.001)
# 5. 训练模型
def train(epoch):
model.train()
running_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 100 == 99:
print(f'epoch: {epoch+1}, batch: {batch_idx+1}, loss: {running_loss/100:.3f}')
running_loss = 0.0
# 6. 测试模型
def test():
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = 100 * correct / total
print(f'test accuracy: {accuracy:.2f}%')
return accuracy
# 7. 执行训练和测试
epochs = 5
for epoch in range(epochs):
train(epoch)
test()
# 8. 保存模型
torch.save(model.state_dict(), 'mnist_model.pth')
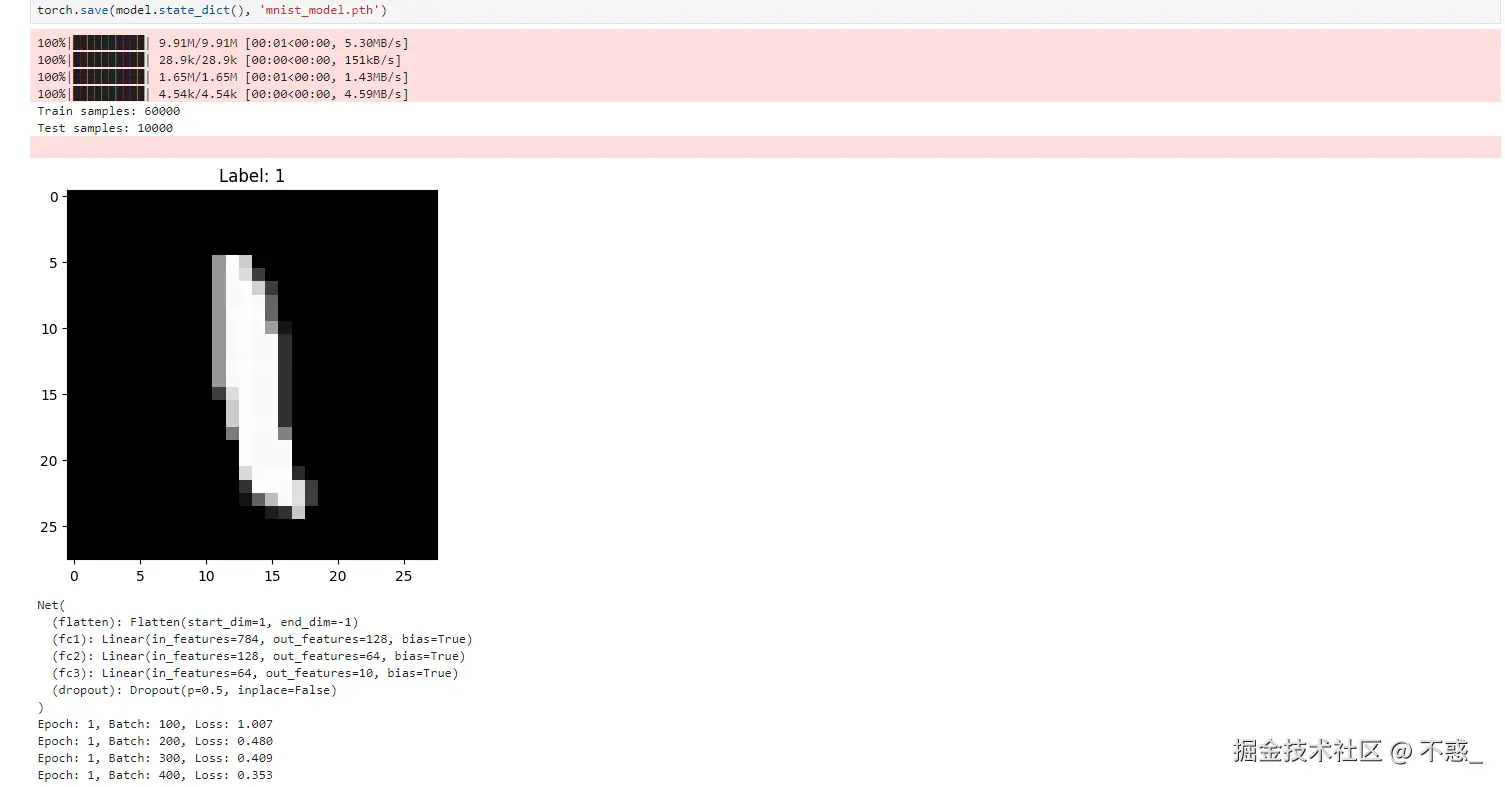
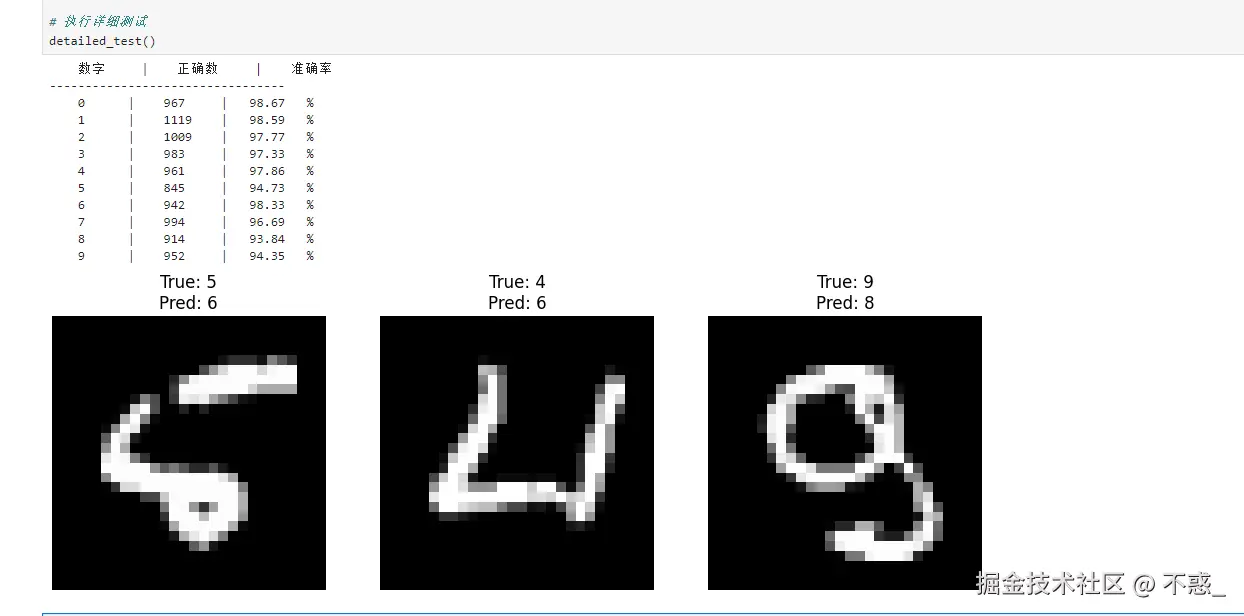
针对1-9数字的测试
# 扩展测试函数,增加按数字统计的功能
def detailed_test():
model.eval()
class_correct = [0] * 10 # 存储每个数字的正确计数
class_total = [0] * 10 # 存储每个数字的总样本数
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs, 1)
# 遍历每个预测结果
for label, prediction in zip(labels, predicted):
class_total[label] += 1
if label == prediction:
class_correct[label] += 1
# 打印每个数字的准确率
print("{:^10} | {:^10} | {:^10}".format("数字", "正确数", "准确率"))
print("-"*33)
for i in range(10):
acc = 100 * class_correct[i] / class_total[i]
print("{:^10} | {:^10} | {:^10.2f}%".format(i, class_correct[i], acc))
# 可视化错误案例
wrong_examples = []
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs, 1)
mask = predicted != labels
wrong_examples.extend(zip(images[mask], labels[mask], predicted[mask]))
# 随机展示3个错误样本
fig, axes = plt.subplots(1, 3, figsize=(12,4))
for ax, (img, true, pred) in zip(axes, wrong_examples[:3]):
ax.imshow(img.squeeze(), cmap='gray')
ax.set_title(f'true: {true}\npred: {pred}')
ax.axis('off')
plt.show()
# 执行详细测试
detailed_test()
pytorch vs tensorflow 深度对比
1. 核心架构差异
| 特性 | pytorch | tensorflow |
|---|---|---|
| 计算图 | 动态图(即时执行) | 静态图(需预先定义) |
| 调试便利性 | 支持标准python调试工具 | 需要特殊工具(tfdbg) |
| api设计 | 更接近python原生语法 | 自成体系的api风格 |
| 移动端部署 | 支持但生态较弱 | 通过tf lite有成熟解决方案 |
2. 相同功能的代码对比
以定义全连接层为例:
# pytorch版 import torch.nn as nn layer = nn.linear(in_features=784, out_features=128) # tensorflow版 from tensorflow.keras.layers import dense layer = dense(units=128, input_dim=784)
3. 训练流程对比
pytorch训练循环:
for epoch in range(epochs):
for data, labels in train_loader:
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
tensorflow训练流程:
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy') model.fit(train_dataset, epochs=epochs) # 自动完成训练循环
4. 性能对比(mnist示例)
| 指标 | pytorch(cpu) | tensorflow(cpu) |
|---|---|---|
| 训练时间/epoch | ~45秒 | ~50秒 |
| 内存占用 | ~800mb | ~1gb |
| 测试准确率 | 97.8-98.2% | 97.5-98.0% |
工具的本质
pytorch与tensorflow的差异,本质上是灵活性与规范性的不同追求。就像画家选择画笔,pytorch提供的是自由挥洒的水彩,tensorflow则是精准可控的钢笔。理解它们的特性差异,根据项目需求选择合适的工具,才是提升开发效率的关键。无论是哪个框架,最终目标都是将数学公式转化为智能的力量。
以上就是使用pytorch实现手写数字识别功能的详细内容,更多关于pytorch手写数字识别的资料请关注代码网其它相关文章!





发表评论