引言
本文我们将深入分析一个使用 python 开发的应用程序,该程序可以将 markdown 文件转换为 powerpoint 演示文稿。这个工具结合了使用 wxpython 构建的图形用户界面 (gui)、使用 markdown 库解析 markdown、使用 beautifulsoup 处理 html,以及使用 python-pptx 生成 powerpoint 文件。我们将探讨代码结构、功能和关键组件,并解决一个特定的 bug。
应用概述
mdtopptconverter 是一个桌面工具,主要功能包括:
- 通过文件对话框让用户选择 markdown (
.md) 文件。 - 显示文档结构的预览(基于标题)。
- 将 markdown 内容转换为 powerpoint (
.pptx) 文件,按标题组织幻灯片。 - 将输出保存到用户指定的位置。
它依赖以下库:
wxpython:用于 gui 框架。markdown:将 markdown 转换为 html。beautifulsoup:解析 html 并提取内容。python-pptx:以编程方式创建 powerpoint 幻灯片。
该代码是事件驱动的,主窗口包含文件选择字段、预览面板和转换按钮。
代码结构与分析
让我们逐一拆解代码的关键部分。
1. 类定义与初始化
class mdtopptconverter(wx.frame):
def __init__(self, parent, title):
super(mdtopptconverter, self).__init__(parent, title=title, size=(800, 600))
self.md_content = none
self.output_path = none
- 该类继承自
wx.frame,是一个顶级窗口。 - 初始化时设置窗口大小为 800x600 像素,并定义两个实例变量:
md_content(存储 markdown 文本)和output_path(输出文件路径)。 __init__方法使用wx.boxsizer设置 gui 布局,实现控件垂直和水平排列。
gui 组件:
- 文件选择:文本框和“浏览 markdown 文件”按钮,用于输入。
- 输出选择:文本框和“选择输出”按钮,用于指定
.pptx文件。 - 预览面板:只读多行文本控件,用于显示文档结构。
- 转换按钮:触发转换过程。
- 状态栏:显示应用状态信息。
2. 事件处理
应用采用事件驱动编程,通过方法绑定用户操作。
on_browse_file
def on_browse_file(self, event):
wildcard = "markdown files (*.md)|*.md|all files (*.*)|*.*"
dialog = wx.filedialog(self, "choose a markdown file", wildcard=wildcard, style=wx.fd_open | wx.fd_file_must_exist)
if dialog.showmodal() == wx.id_ok:
file_path = dialog.getpath()
self.file_text.setvalue(file_path)
output_path = os.path.splitext(file_path)[0] + ".pptx"
self.output_text.setvalue(output_path)
self.load_md_file(file_path)
- 打开一个文件对话框,过滤显示
.md文件。 - 将选择的文件路径填入输入文本框。
- 通过替换
.md扩展名建议输出.pptx文件路径。 - 调用
load_md_file读取并预览 markdown 内容。
on_select_output
def on_select_output(self, event):
wildcard = "powerpoint files (*.pptx)|*.pptx"
dialog = wx.filedialog(self, "save powerpoint as", wildcard=wildcard, style=wx.fd_save | wx.fd_overwrite_prompt)
if dialog.showmodal() == wx.id_ok:
self.output_text.setvalue(dialog.getpath())
- 打开保存对话框,选择输出
.pptx文件路径。 - 更新输出文本框内容。
on_convert
def on_convert(self, event):
md_file = self.file_text.getvalue()
output_file = self.output_text.getvalue()
if not md_file or not self.md_content:
wx.messagebox("请先选择 markdown 文件", "错误", wx.ok | wx.icon_error)
return
if not output_file:
wx.messagebox("请指定输出文件", "错误", wx.ok | wx.icon_error)
return
try:
self.convert_md_to_ppt(self.md_content, output_file)
wx.messagebox(f"成功转换为 {output_file}", "成功", wx.ok | wx.icon_information)
except exception as e:
wx.messagebox(f"转换过程中出错: {str(e)}", "错误", wx.ok | wx.icon_error)
- 验证输入和输出路径是否已设置。
- 调用
convert_md_to_ppt并通过友好的错误消息处理异常。
3. markdown 处理
load_md_file
def load_md_file(self, file_path):
try:
with open(file_path, 'r', encoding='utf-8') as f:
self.md_content = f.read()
preview = self.generate_structure_preview(self.md_content)
self.preview_text.setvalue(preview)
except exception as e:
wx.messagebox(f"加载文件出错: {str(e)}", "错误", wx.ok | wx.icon_error)
- 读取 markdown 文件并存储到
self.md_content。 - 生成结构预览(例如,显示标题作为潜在幻灯片)并展示。
generate_structure_preview
def generate_structure_preview(self, md_content):
lines = md_content.split('\n')
structure_lines = []
for line in lines:
header_match = re.match(r'^(#{1,6})\s+(.+)$', line)
if header_match:
level = len(header_match.group(1))
title = header_match.group(2)
indent = ' ' * (level - 1)
structure_lines.append(f"{indent}幻灯片 [{level}]: {title}")
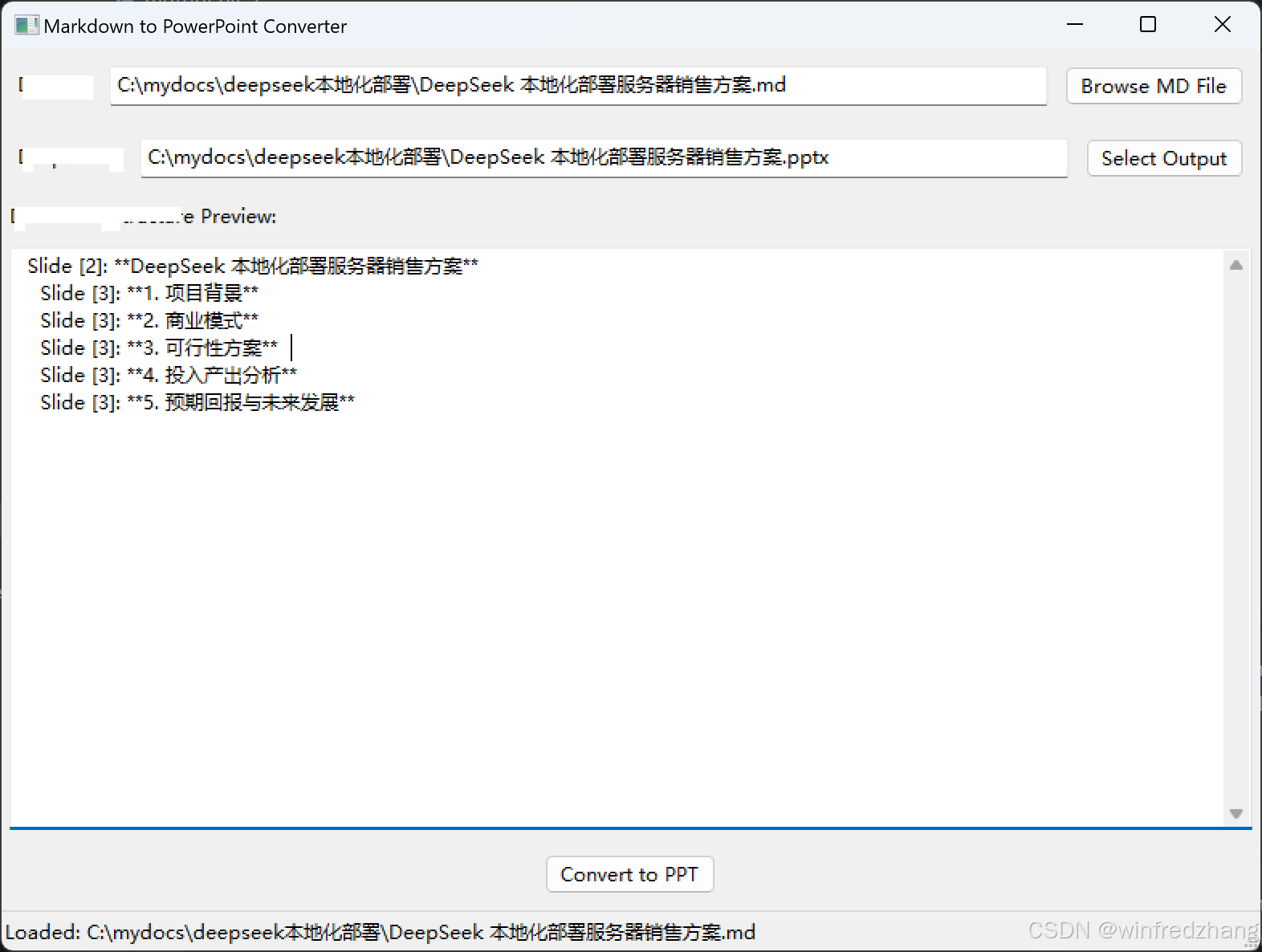
return '\n'.join(structure_lines)
- 使用正则表达式识别 markdown 标题(
#到######)。 - 根据标题级别生成带有缩进的层次结构预览(例如,
幻灯片 [1]: 标题)。
4. 转换逻辑
convert_md_to_ppt
def convert_md_to_ppt(self, md_content, output_path):
prs = presentation()
html_content = markdown.markdown(md_content, extensions=['tables', 'fenced_code'])
soup = bs4.beautifulsoup(html_content, 'html.parser')
headings = soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6'])
- 初始化新的 powerpoint 演示文稿 (
prs)。 - 将 markdown 转换为 html,支持表格和代码块。
- 解析 html,提取所有标题(
h1到h6),这些将成为幻灯片标题。
标题幻灯片:
- 如果第一个标题是
h1,则创建标题幻灯片,带副标题(h1后的第一个段落)。
内容幻灯片:
- 遍历剩余标题:
h1:标题幻灯片布局。h2:标题和内容布局。h3-h6:章节标题布局。
- 收集内容(段落、列表、代码块、引用)直到遇到同级或更高级别的下一个标题。
- 处理大内容时,若超过阈值(1000 个字符),则拆分为多页幻灯片。
_add_elements_to_slide
def _add_elements_to_slide(self, elements, text_frame):
for element in elements:
p = text_frame.add_paragraph()
if element.name == 'p':
p.text = element.text
elif element.name == 'ul' or element.name == 'ol':
list_items = element.find_all('li')
for i, item in enumerate(list_items):
if i > 0:
p = text_frame.add_paragraph()
p.text = "• " + item.text
p.level = 1
elif element.name == 'pre':
p.text = element.text
p.font.name = "courier new"
elif element.name == 'blockquote':
p.text = element.text
p.font.italic = true
- 将内容添加到幻灯片的文本框架中,格式化:
- 段落为纯文本。
- 列表带项目符号和缩进。
- 代码块使用
courier new字体。 - 引用使用斜体。
保存演示文稿:
- 在
convert_md_to_ppt末尾调用prs.save(output_path),确保所有幻灯片添加完成后保存。
bug 修复:“name ‘prs’ is not defined”
早期代码版本中,将 prs.save(output_path) 放在 _add_elements_to_slide 中会导致 nameerror,因为 prs 只在 convert_md_to_ppt 中定义。修复方法如下:
- 将
save调用移动到convert_md_to_ppt末尾,确保prs在作用域内。 - 让
_add_elements_to_slide专注于添加内容,不负责保存。
修复前:
def _add_elements_to_slide(self, elements, text_frame):
# ... 添加内容 ...
prs.save(output_path) # 错误:prs 未在此定义
修复后:
def convert_md_to_ppt(self, md_content, output_path):
# ... 创建幻灯片 ...
prs.save(output_path) # 移至此处
此修复确保演示文稿在所有处理完成后保存一次,避免作用域问题。
结果如下

以上就是使用python和python-pptx构建markdown到powerpoint转换器的详细内容,更多关于python markdown到powerpoint转换器的资料请关注代码网其它相关文章!






发表评论