一、引言
在数字文档处理领域,pdf到图像格式的转换是常见需求。本文介绍如何利用python的pymupdf库和tkinter框架,开发一个带图形界面的pdf转png工具。该工具支持页面选择、分辨率调整等功能,并具有友好的用户交互体验。
二、功能特性
1. 核心功能
- pdf文件可视化选择
- 智能页码范围解析(支持1,3-5格式)
- 输出目录自定义设置
- 72-600 dpi可调分辨率
- 实时转换进度显示
2. 增强特性
- 多线程非阻塞转换
- 异常安全机制
- 自动目录创建
- 文件完整性校验
- 权限错误处理
三、技术架构
1. 技术栈组成
| 组件 | 作用说明 |
|---|---|
| pymupdf | pdf解析与图像渲染 |
| tkinter | 图形界面开发框架 |
| threading | 异步任务处理 |
| os模块 | 文件系统操作 |
2. 系统架构设计
gui层
├── 文件选择模块
├── 页面控制模块
├── 输出配置模块
└── 状态监控模块
业务逻辑层
├── pdf解析引擎
├── 图像转换核心
└── 异常处理中心
系统服务层
├── 多线程管理
├── 文件io操作
└── 资源回收机制
3.效果图
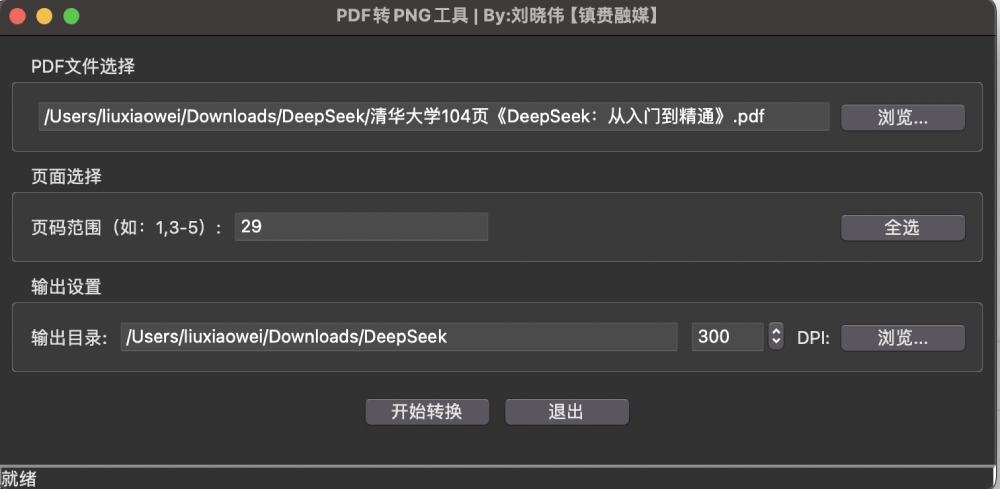
四、关键技术实现
1. 页面解析算法
def parse_page_range(self, page_str):
"""智能页码范围解析"""
pages = []
parts = page_str.split(',')
for part in parts:
part = part.strip()
if '-' in part:
start, end = part.split('-', 1)
# 转换为0-based索引
start_idx = int(start) - 1
end_idx = int(end) - 1
pages.extend(range(start_idx, end_idx+1))
else:
pages.append(int(part)-1)
# 去重排序并验证范围
return sorted(list(set(pages)))
算法特点:
- 支持逗号分隔和连字符范围
- 自动过滤重复页码
- 0-based索引转换
- 边界有效性校验
2. 图像转换核心
def convert_pages(self, pages):
doc = fitz.open(self.pdf_path)
zoom = int(self.dpi_spin.get()) / 72 # dpi转换系数
matrix = fitz.matrix(zoom, zoom)
for page_num in pages:
page = doc.load_page(page_num)
pix = page.get_pixmap(matrix=matrix)
pix.save(f"page_{page_num+1}.png")
关键技术点:
- 矩阵变换实现分辨率控制
- 基于矢量图形的无损渲染
- 自适应色彩空间管理
- 分页异步保存机制
3. 多线程处理
thread(target=self.convert_pages,
args=(pages,),
daemon=true).start()
设计优势:
- 主线程维护gui响应(60fps)
- 工作线程独立执行转换任务
- 守护模式防止僵尸进程
- 安全的状态同步机制
五、异常处理体系
1. 异常分类处理
| 异常类型 | 处理方式 |
|---|---|
| filenotfounderror | 弹窗提示文件不存在 |
| permissionerror | 显示权限错误并终止操作 |
| valueerror | 高亮错误输入框并提示 |
| runtimeerror | 记录日志并恢复初始状态 |
2. 健壮性增强措施
try:
with fitz.open(self.pdf_path) as doc:
# 正常流程
except fitz.filedataerror:
messagebox.showerror("文件已损坏")
except exception as e:
# 通用异常捕获
finally:
self.running = false # 状态复位
六、工具使用指南
1. 操作流程
- 点击"浏览"选择pdf文件
- 输入目标页码范围(示例:1,3-5)
- 设置输出目录和dpi值
- 点击"开始转换"启动任务
- 通过状态栏查看实时进度
2. 最佳实践建议
- 300 dpi适合文档存档
- 150 dpi满足屏幕查看需求
- 批量处理时使用"全选"功能
- 复杂页码使用逗号分隔输入
七、性能优化
1. 内存管理策略
- 分页加载机制(load_page)
- 及时释放pixmap资源
- 使用with语句自动关闭文档
2. 渲染优化方案
matrix = fitz.matrix(zoom, zoom).prescale(2, 2) # 抗锯齿优化
pix = page.get_pixmap(
matrix=matrix,
alpha=false, # 禁用透明通道
colorspace="rgb" # 标准色彩空间
)
八、扩展方向
1. 功能增强
- 添加批量转换支持
- 实现图像格式选择(jpg/png)
- 增加页面预览功能
- 支持pdf加密文件
2. 企业级改造
- 集成到docker微服务
- 添加日志审计功能
- 实现分布式转换
- 开发restful api接口
九、结语
本文开发的pdf转png工具将命令行操作转化为可视化流程,通过pymupdf的高性能渲染引擎和tkinter的跨平台特性,实现了专业级文档转换工具的开发。该方案可作为企业文档数字化解决方案的基础模块,具有较高的实用价值和扩展潜力。
以上就是基于python开发pdf转png的可视化工具的详细内容,更多关于python pdf转png的资料请关注代码网其它相关文章!



发表评论