算法介绍
textrank算法是一种基于图的排序算法,主要用于文本处理中的关键词提取和文本摘要。它由pagerank算法改进而来,pagerank算法是谷歌用于网页重要性排序的算法。textrank算法通过构建文本的图模型,利用句子之间的相似度作为边的权重,通过迭代计算句子的textrank值,最后抽取排名高的句子组合成文本摘要。
实现思路
我们基于python代码,使用pyqt5创建图形用户界面(gui),同时支持中英文两种语言的文本论文文献关键信息提取。
pyqt5:用于创建gui应用程序。
jieba:中文分词库,用于中文文本的处理。
re:正则表达式模块,用于文本清理和句子分割。
numpy:提供数值计算能力,如数组操作、矩阵运算等,主要用于textrank算法的实现。
完整代码
import sys
import re
import jieba
import numpy as np
from pyqt5.qtwidgets import (qapplication, qmainwindow, qwidget, qvboxlayout,
qhboxlayout, qtextedit, qpushbutton, qlabel,
qmessagebox, qspinbox, qfiledialog, qcombobox)
from pyqt5.qtcore import qt
class textranksummarizer:
def __init__(self, language='chinese'):
self.language = language
self.stopwords = self.load_stopwords()
# 初始化jieba中文分词器
if language == 'chinese':
jieba.initialize()
def load_stopwords(self):
"""内置停用词表"""
if self.language == 'chinese':
return {'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '也', '要'}
else: # 英文停用词
return {'a', 'an', 'the', 'and', 'or', 'but', 'if', 'is', 'are', 'of', 'to', 'in', 'on'}
def preprocess_text(self, text):
"""文本预处理"""
# 清洗特殊字符
text = re.sub(r'[^\w\s。,.?!]', '', text)
# 分句处理
if self.language == 'chinese':
sentences = re.split(r'[。!?]', text)
else:
sentences = re.split(r'[.!?]', text)
return [s.strip() for s in sentences if len(s) > 2]
def calculate_similarity(self, sentence, other_sentence):
"""计算句子相似度"""
words1 = [w for w in (jieba.cut(sentence) if self.language == 'chinese' else sentence.lower().split())
if w not in self.stopwords]
words2 = [w for w in
(jieba.cut(other_sentence) if self.language == 'chinese' else other_sentence.lower().split())
if w not in self.stopwords]
# 使用jaccard相似度
intersection = len(set(words1) & set(words2))
union = len(set(words1) | set(words2))
return intersection / union if union != 0 else 0
def textrank(self, sentences, top_n=5, damping_factor=0.85, max_iter=100):
"""textrank算法实现"""
similarity_matrix = np.zeros((len(sentences), len(sentences)))
# 构建相似度矩阵
for i in range(len(sentences)):
for j in range(len(sentences)):
if i != j:
similarity_matrix[i][j] = self.calculate_similarity(sentences[i], sentences[j])
# 归一化矩阵
row_sum = similarity_matrix.sum(axis=1)
normalized_matrix = similarity_matrix / row_sum[:, np.newaxis]
# 初始化得分
scores = np.ones(len(sentences))
# 迭代计算
for _ in range(max_iter):
prev_scores = np.copy(scores)
for i in range(len(sentences)):
scores[i] = (1 - damping_factor) + damping_factor * np.sum(normalized_matrix[i, :] * prev_scores)
if np.linalg.norm(scores - prev_scores) < 1e-5:
break
# 获取重要句子索引
ranked_indices = np.argsort(scores)[::-1][:top_n]
return sorted(ranked_indices)
def summarize(self, text, ratio=0.2):
"""生成摘要"""
sentences = self.preprocess_text(text)
if len(sentences) < 3:
return "文本过短,无法生成有效摘要"
top_n = max(1, int(len(sentences) * ratio))
important_indices = self.textrank(sentences, top_n=top_n)
# 按原文顺序排列
selected_sentences = [sentences[i] for i in sorted(important_indices)]
# 中文使用句号连接,英文使用.连接
separator = '。' if self.language == 'chinese' else '. '
return separator.join(selected_sentences) + ('。' if self.language == 'chinese' else '.')
class mainwindow(qmainwindow):
def __init__(self):
super().__init__()
# 初始化摘要器
self.summarizer = textranksummarizer()
# 界面设置
self.setup_ui()
def setup_ui(self):
self.setwindowtitle("textrank文本摘要工具")
self.setgeometry(100, 100, 1000, 800)
main_widget = qwidget()
layout = qvboxlayout()
# 输入区
self.input_text = qtextedit()
self.input_text.setplaceholdertext("在此粘贴需要摘要的文本(建议500字以上)...")
# 控制区
control_layout = qhboxlayout()
self.ratio_spin = qspinbox()
self.ratio_spin.setrange(5, 50)
self.ratio_spin.setvalue(20)
self.ratio_spin.setsuffix("%")
self.lang_combo = qcombobox()
self.lang_combo.additems(["中文", "英文"])
self.summarize_btn = qpushbutton("生成摘要")
self.import_btn = qpushbutton("导入文件")
self.clear_btn = qpushbutton("清空")
control_layout.addwidget(qlabel("摘要比例:"))
control_layout.addwidget(self.ratio_spin)
control_layout.addwidget(qlabel("语言:"))
control_layout.addwidget(self.lang_combo)
control_layout.addwidget(self.import_btn)
control_layout.addwidget(self.summarize_btn)
control_layout.addwidget(self.clear_btn)
# 输出区
self.output_text = qtextedit()
self.output_text.setreadonly(true)
# 布局组合
layout.addwidget(qlabel("输入文本:"))
layout.addwidget(self.input_text)
layout.addlayout(control_layout)
layout.addwidget(qlabel("摘要结果:"))
layout.addwidget(self.output_text)
main_widget.setlayout(layout)
self.setcentralwidget(main_widget)
# 信号连接
self.summarize_btn.clicked.connect(self.generate_summary)
self.import_btn.clicked.connect(self.import_file)
self.clear_btn.clicked.connect(self.clear_content)
self.lang_combo.currenttextchanged.connect(self.change_language)
def change_language(self, lang):
self.summarizer = textranksummarizer('chinese' if lang == "中文" else 'english')
def generate_summary(self):
text = self.input_text.toplaintext().strip()
if not text:
qmessagebox.warning(self, "输入错误", "请输入需要摘要的文本")
return
ratio = self.ratio_spin.value() / 100
summary = self.summarizer.summarize(text, ratio)
self.output_text.setplaintext(summary)
def import_file(self):
path, _ = qfiledialog.getopenfilename(
self, "打开文本文件", "",
"文本文件 (*.txt);;所有文件 (*.*)"
)
if path:
try:
with open(path, 'r', encoding='utf-8') as f:
self.input_text.setplaintext(f.read())
except exception as e:
qmessagebox.critical(self, "错误", f"文件读取失败:\n{str(e)}")
def clear_content(self):
self.input_text.clear()
self.output_text.clear()
if __name__ == "__main__":
app = qapplication(sys.argv)
window = mainwindow()
window.show()
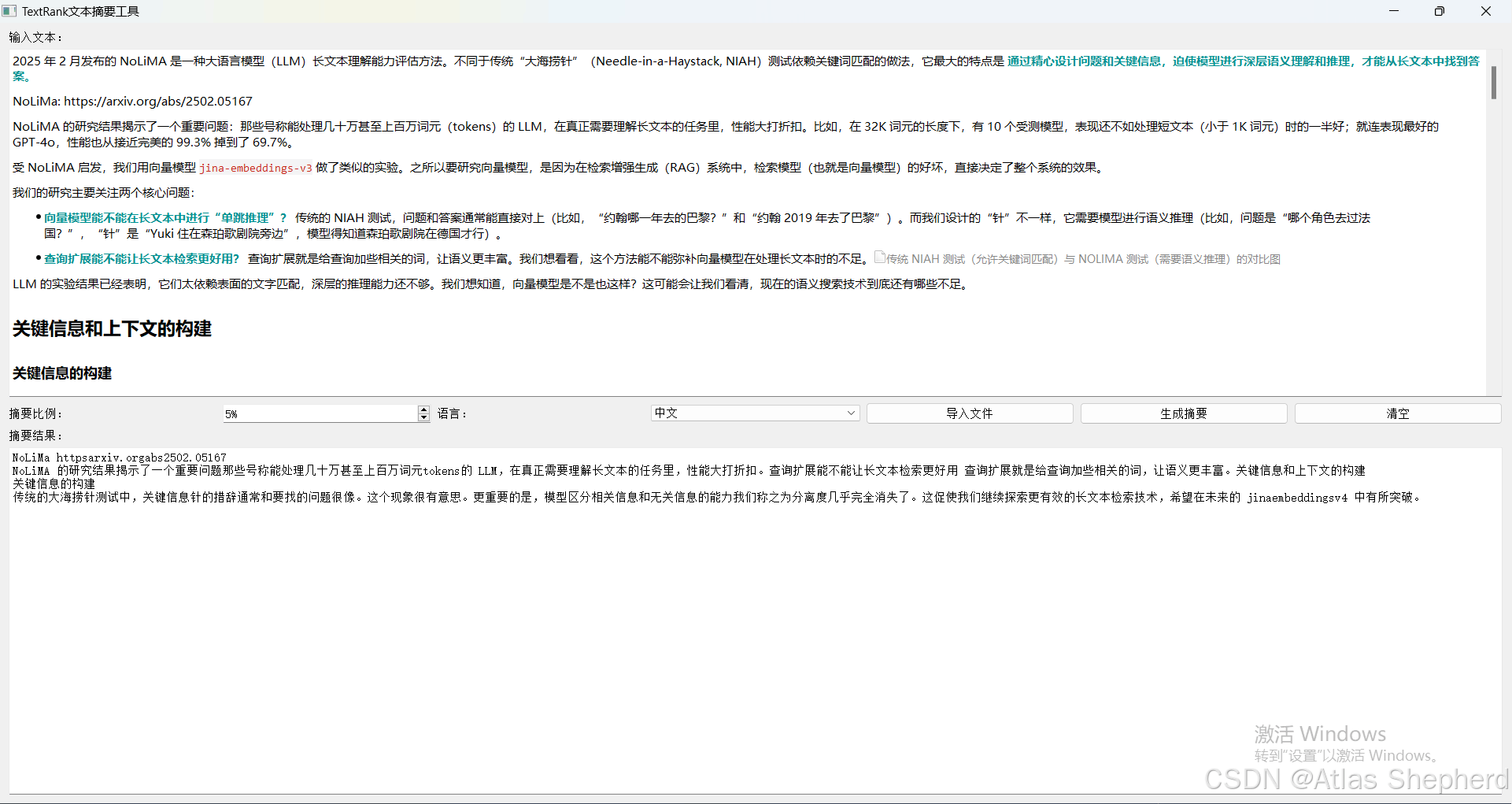
sys.exit(app.exec_())效果图
最后效果如下
到此这篇关于python使用textrank算法实现文献关键信息提取的文章就介绍到这了,更多相关python textrank关键信息提取内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论