数据清洗是对一些没有用的数据进行处理的过程。很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理。数据清洗与预处理的常见步骤:
- 缺失值处理:识别并填补缺失值,或删除含缺失值的行/列。
- 重复数据处理:检查并删除重复数据,确保每条数据唯一。
- 异常值处理:识别并处理异常值,如极端值、错误值。
- 数据格式转换:转换数据类型或进行单位转换,如日期格式转换。
- 标准化与归一化:对数值型数据进行标准化(如 z-score)或归一化(如 min-max)。
- 类别数据编码:将类别变量转换为数值形式,常见方法包括 one-hot 编码和标签编码。
- 文本处理:对文本数据进行清洗,如去除停用词、词干化、分词等。
- 数据抽样:从数据集中抽取样本,或通过过采样/欠采样处理类别不平衡。
- 特征工程:创建新特征、删除不相关特征、选择重要特征等。
本文使用到的测试数据 property-data.csv 如下:
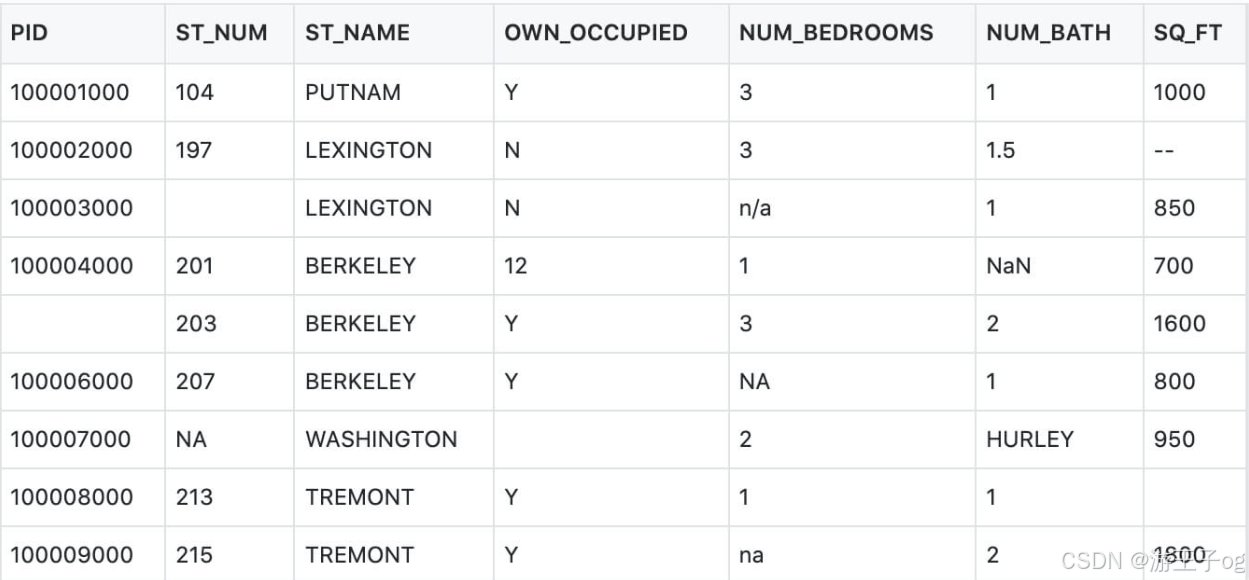
上表包含了四种空数据:
- n/a
- na
- —
- na
1 pandas 清洗空值
如果我们要删除包含空字段的行,可以使用 dropna() 方法,语法格式如下:
dataframe.dropna(axis=0, how='any', thresh=none, subset=none, inplace=false)
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 'any' 如果一行(或一列)里任何一个数据有出现 na 就去掉整行,如果设置 how='all' 一行(或列)都是 na 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 true,将计算得到的值直接覆盖之前的值并返回 none,修改的是源数据。
1.1 isnull() 判断各个单元格是否为空
我们可以通过 isnull() 判断各个单元格是否为空。
import pandas as pd
df = pd.read_csv('property-data.csv')
print(df['num_bedrooms'])
print(df['num_bedrooms'].isnull())
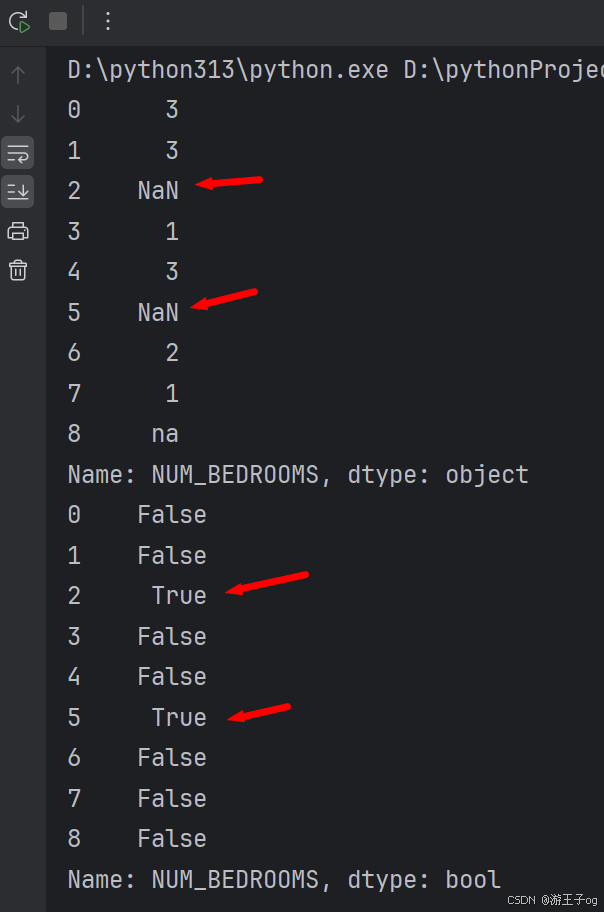
以上例子中我们看到 pandas 没有把 n/a 和 na 当作空数据,不符合我们要求,我们可以指定空数据类型:
import pandas as pd
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values=missing_values)
print(df['num_bedrooms'])
print(df['num_bedrooms'].isnull())

1.2 dropna() 删除包含空数据的行
接下来的实例演示了删除包含空数据的行。
import pandas as pd
df = pd.read_csv('property-data.csv')
new_df = df.dropna()
print(new_df.to_string())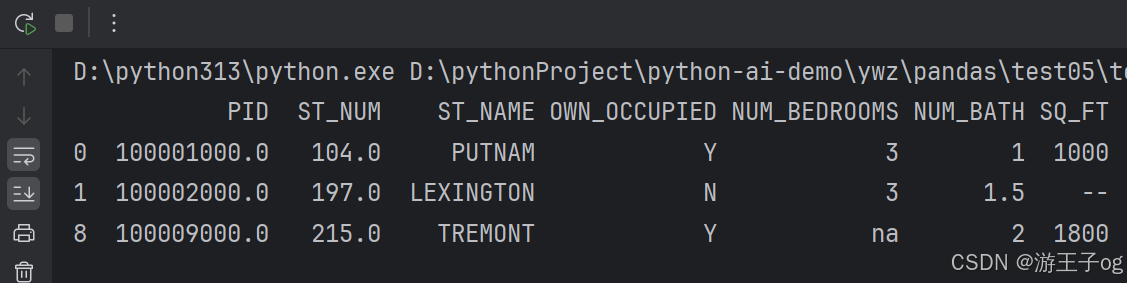
默认情况下,dropna() 方法返回一个新的 dataframe,不会修改源数据。如果你要修改源数据 dataframe, 可以使用 inplace = true 参数:
df.dropna(inplace = true)
我们也可以移除指定列有空值的行:
import pandas as pd
df = pd.read_csv('property-data.csv')
df.dropna(subset=['st_num'], inplace=true)
print(df.to_string())

1.3 fillna() 替换空字段
我们也可以 fillna() 方法来替换一些空字段:
import pandas as pd
df = pd.read_csv('property-data.csv')
df.fillna(12345, inplace=true)
print(df.to_string())

我们也可以指定某一个列来替换数据,例如使用 12345 替换 pid 为空数据:
df.fillna({ 'pid' : 12345 }, inplace = true)
替换空单元格的常用方法是计算列的均值、中位数值或众数。pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)。
1.3.1 mean() 均值替换
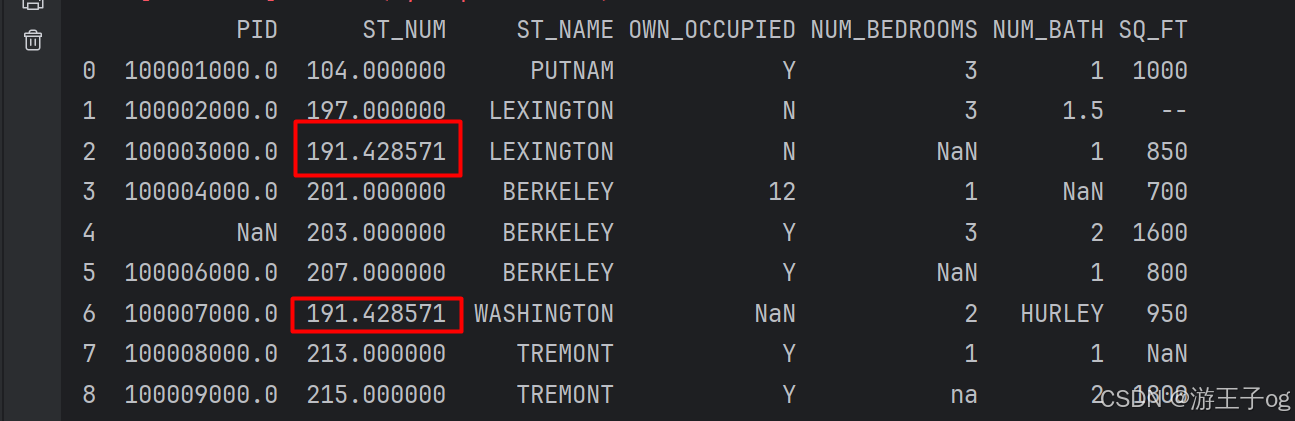
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["st_num"].mean()
df.fillna({ 'st_num': x }, inplace=true)
print(df.to_string())
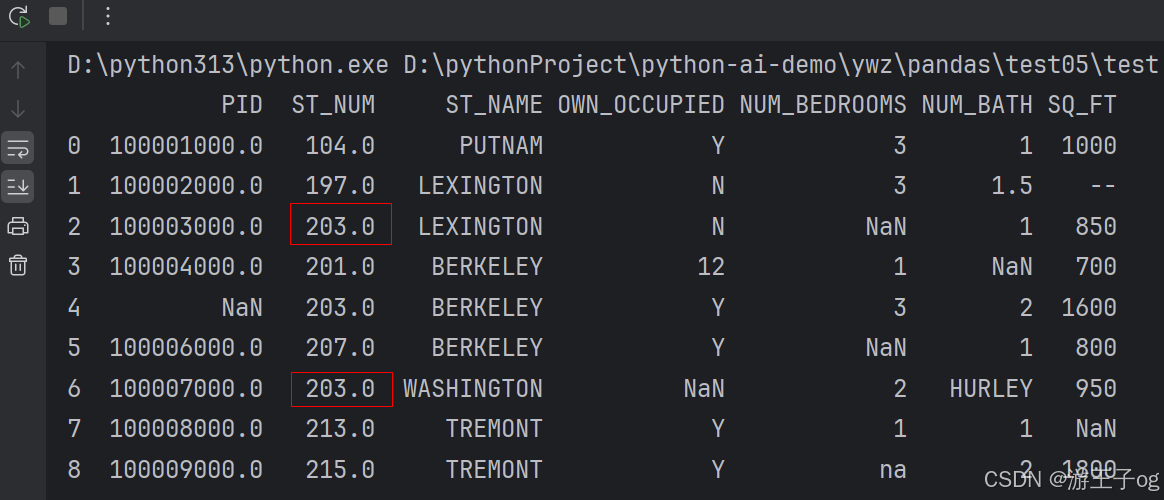
以上实例输出结果如下,红框为计算的中位数替换来空单元格:
1.3.2 median() 中位数替换
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["st_num"].median()
df.fillna({'st_num': x}, inplace=true)
print(df.to_string())
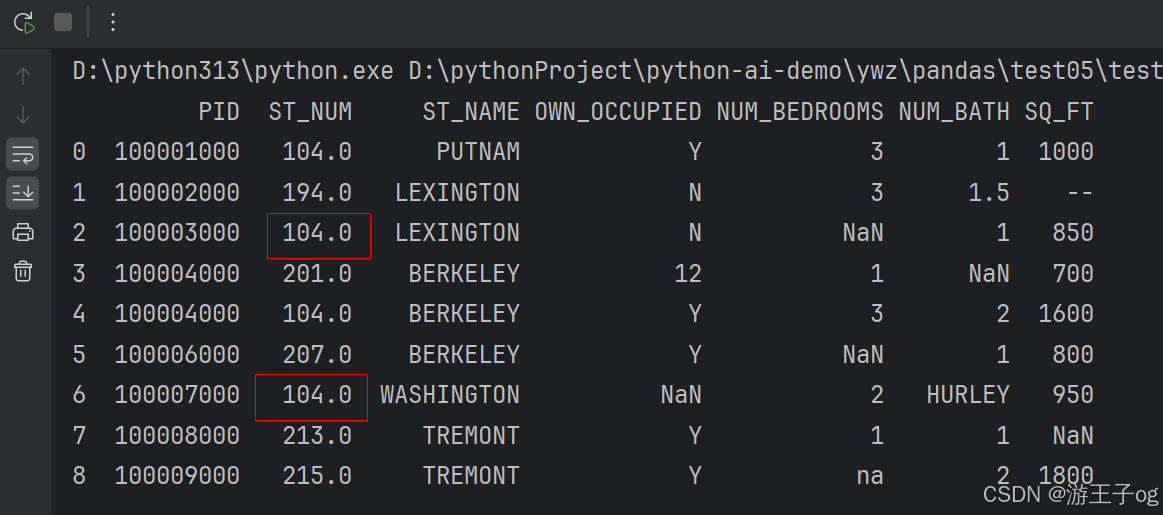
1.3.3 mode() 众数替换
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["st_num"].mode()
df.fillna({'st_num': x.values[0]}, inplace=true)
print(df.to_string())
mode()可能会出现多个值,所以需要用values[index]指定。
2 pandas 清洗格式错误数据
数据格式错误的单元格会使数据分析变得困难,甚至不可能。我们可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据。以下实例会格式化日期:
import pandas as pd
# 第三个日期格式错误
data = {
"date": ['2020/12/01', '2020/12/02', '20201226'],
"duration": [50, 40, 45]
}
df = pd.dataframe(data, index=["day1", "day2", "day3"])
df['date'] = pd.to_datetime(df['date'], format='mixed')
print(df.to_string())

3 pandas 清洗错误数据
数据错误也是很常见的情况,我们可以对错误的数据进行替换或移除。以下实例会替换错误年龄的数据:
import pandas as pd
person = {
"name": ['google', 'bing', 'taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.dataframe(person)
df.loc[2, 'age'] = 30 # 修改数据
print(df.to_string())

也可以设置条件语句,例如将 age 大于 120 的设置为 120:
import pandas as pd
person = {
"name": ['google', 'bing', 'taobao'],
"age": [50, 200, 12345]
}
df = pd.dataframe(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.loc[x, "age"] = 120
print(df.to_string())

也可以将错误数据的行删除,例如将 age 大于 120 的删除:
import pandas as pd
person = {
"name": ['google', 'runoob', 'taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.dataframe(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.drop(x, inplace=true)
print(df.to_string())

4 pandas 清洗重复数据
如果我们要清洗重复数据,可以使用 duplicated() 和 drop_duplicates() 方法。如果对应的数据是重复的,duplicated() 会返回 true,否则返回 false。
import pandas as pd
person = {
"name": ['google', 'bing', 'bing', 'taobao'],
"age": [50, 40, 40, 23]
}
df = pd.dataframe(person)
print(df.duplicated())
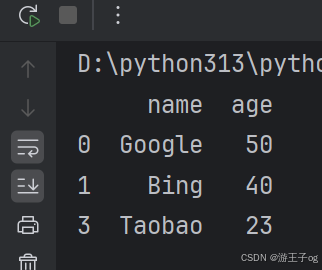
删除重复数据,可以直接使用drop_duplicates() 方法。
import pandas as pd
person = {
"name": ['google', 'bing', 'bing', 'taobao'],
"age": [50, 40, 40, 23]
}
df = pd.dataframe(person)
df.drop_duplicates(inplace=true)
print(df)
5 常用方法及说明
| 操作 | 方法/步骤 | 说明 | 常用函数/方法 |
|---|---|---|---|
| 缺失值处理 | 填充缺失值 | 使用指定的值(如均值、中位数、众数等)填充缺失值。 | df.fillna(value) |
| 删除缺失值 | 删除包含缺失值的行或列。 | df.dropna() | |
| 重复数据处理 | 删除重复数据 | 删除 dataframe 中的重复行。 | df.drop_duplicates() |
| 异常值处理 | 异常值检测(基于统计方法) | 通过 z-score 或 iqr 方法识别并处理异常值。 | 自定义函数(如基于 z-score 或 iqr) |
| 替换异常值 | 使用合适的值(如均值或中位数)替换异常值。 | 自定义函数(如替换异常值) | |
| 数据格式转换 | 转换数据类型 | 将数据类型从一个类型转换为另一个类型,如将字符串转换为日期。 | df.astype() |
| 日期时间格式转换 | 转换字符串或数字为日期时间类型。 | pd.to_datetime() | |
| 标准化与归一化 | 标准化 | 将数据转换为均值为0,标准差为1的分布。 | standardscaler() |
| 归一化 | 将数据缩放到指定的范围(如 [0, 1])。 | minmaxscaler() | |
| 类别数据编码 | 标签编码 | 将类别变量转换为整数形式。 | labelencoder() |
| 独热编码(one-hot encoding) | 将每个类别转换为一个新的二进制特征。 | pd.get_dummies() | |
| 文本数据处理 | 去除停用词 | 从文本中去除无关紧要的词,如 "the" 、 "is" 等。 | 自定义函数(基于 nltk 或 spacy) |
| 词干化与词形还原 | 提取词干或恢复单词的基本形式。 | nltk.stem.porterstemmer() | |
| 分词 | 将文本分割成单词或子词。 | nltk.word_tokenize() | |
| 数据抽样 | 随机抽样 | 从数据中随机抽取一定比例的样本。 | df.sample() |
| 上采样与下采样 | 通过过采样(复制少数类样本)或欠采样(减少多数类样本)来平衡数据集中的类别分布。 | smote()(上采样); randomundersampler()(下采样) | |
| 特征工程 | 特征选择 | 选择对目标变量有影响的特征,去除冗余或无关特征。 | selectkbest() |
| 特征提取 | 从原始数据中创建新的特征,提升模型的预测能力。 | polynomialfeatures() | |
| 特征缩放 | 对数值特征进行缩放,使其具有相同的量级。 | minmaxscaler() 、 standardscaler() | |
| 类别特征映射 | 特征映射 | 将类别变量映射为对应的数字编码。 | 自定义映射函数 |
| 数据合并与连接 | 合并数据 | 将多个 dataframe 按照某些列合并在一起,支持内连接、外连接、左连接、右连接等。 | pd.merge() |
| 连接数据 | 将多个 dataframe 进行行或列拼接。 | pd.concat() | |
| 数据重塑 | 数据透视表 | 将数据根据某些维度进行分组并计算聚合结果。 | pd.pivot_table() |
| 数据变形 | 改变数据的形状,如从长格式转为宽格式或从宽格式转为长格式。 | df.melt() 、 df.pivot() | |
| 数据类型转换与处理 | 字符串处理 | 对字符串数据进行处理,如去除空格、转换大小写等。 | str.replace() 、 str.upper() 等 |
| 分组计算 | 按照某个特征分组后进行聚合计算。 | df.groupby() | |
| 缺失值预测填充 | 使用模型预测填充缺失值 | 使用机器学习模型(如回归模型)预测缺失值,并填充缺失数据。 | 自定义模型(如 sklearn.linear_model.linearregression) |
| 时间序列处理 | 时间序列缺失值填充 | 使用时间序列的方法(如前向填充、后向填充)填充缺失值。 | df.fillna(method='ffill') |
| 滚动窗口计算 | 使用滑动窗口进行时间序列数据的统计计算(如均值、标准差等)。 | df.rolling(window=5).mean() | |
| 数据转换与映射 | 数据映射与替换 | 将数据中的某些值替换为其他值。 | df.replace() |
到此这篇关于pandas 数据清洗的具体使用的文章就介绍到这了,更多相关pandas 数据清洗内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论