人工智能(ai)是当今科技领域的热门话题之一。在过去的几年里,ai技术在各个领域都取得了重大的突破和应用,例如图像识别、语音识别、自然语言处理等。如果你对ai感兴趣,并且想要亲自动手训练自己的ai模型,那么本篇博客将为你提供一些详细的指导。
思维导图
以下是使用mermaid代码绘制的思维导图,展示了从零训练自己的ai模型的主要步骤和技术:
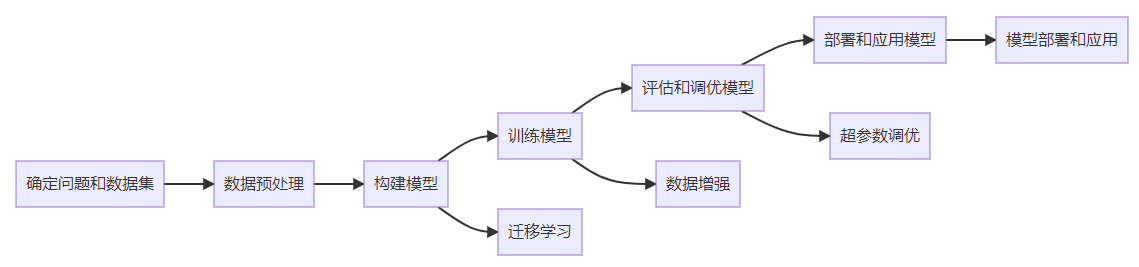
以上思维导图清晰地展示了从问题和数据集确定到模型部署和应用的整个过程。通过按照思维导图的指引,你可以一步步地使用python训练自己的ai模型,并将其用于实际问题的解决。
确定问题和数据集
首先,你需要明确你要解决的问题,并找到合适的数据集来训练你的模型。例如,你可以选择图像分类、情感分析、文本生成等不同的任务。在选择数据集时,要确保数据集的质量和适用性,以便训练出高质量的模型。
数据预处理
在开始训练模型之前,通常需要对数据进行预处理。这包括数据清洗、特征提取和数据转换等步骤。例如,对于图像分类任务,你可能需要将图像转换为数字矩阵,并对图像进行缩放和标准化处理。
以下是一个简单的python代码示例,展示了如何使用opencv库对图像预处理:
import2
def preprocess_image(image):
gray_image = cv2.cvtcolor(image, cv2.color_bgr2gray)
resized_image = cv2.resize(gray_image, (32, 32))
normalized_image = resized_image / 255.0
return normalized_image
构建模型
接下来,你需要选择适合你问题的模型架构,并使用python构建模型。python中有许多流行的机器学习库,例如tensorflow、pytorch和scikit-learn,可以帮助你构建和训练模型。
以下是一个简单的python代码示例,展示了如何使用tensorflow库构建一个简单的卷积神经网络(cnn)模型:
import tensorflow as tf
def build_model():
model = tf.keras.sequential([
tf.keras.layers.conv2d(32, (3, 3), activation='relu', input_shape=(32, 32, 1)),
tf.keras.layers.maxpooling2d((2, 2)),
tf.keras.layers.flatten(),
tf.keras.layers.dense(64, activation='relu'),
tf.keras.layers.dense(10, activation='softmax')
])
return model
训练模型
一旦模型构建完成,你就可以使用数据集来训练模型了。在训练过程中,你需要定义损失函数和优化算法,并选择适当的训练参数。通常,你需要将数据集分为训练集和验证集,用于评估模型的性能。
以下是一个简单的python代码示例,展示了如何使用tensorflow库训练模型:
def train_model(model, train_data, train_labels, val_data, val_labels):
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_data, train_labels, epochs=10, validation_data=(val_data, val_labels))
评估和调优模型
训练完成后,你需要评估模型的性能,并进行模型的调优。通过分析模型在验证集上的表现,你可以调整模型的参数、增加数据量或者尝试其他算法,以获得更好的性能。
以下是一个简单的python代码示例,展示了如何评估模型的准确率:
def evaluate_model(model, test_data, test_labels):
test_loss, test_accuracy = model.evaluate(test_data, test_labels)
print('test loss:', test_loss)
print('test accuracy:', test_accuracy)
部署和应用模型
最后,一旦你对模型的性能满意,你可以将其部署到实际应用中并使用它来解决实际问题。例如,你可以将训练好的图像分类模型部署到一个web应用程序中,用于自动识别上传的图像。
总结起来,使用python从零训练自己的ai模型需要经过确定问题和数据集、数据预处理、构建模型、训练模型、评估和调优模型以及部署和应用模型等步骤。希望本篇博客能够帮助你入门ai模型训练的过程,并激发你对人工智能的兴趣。祝你在ai领域取得成功!
(注:以上代码仅为示例,并不完整或可执行,实际应用中可能需要根据具体问题进行适当修改。)
数据增强
在训练模型之前,你可以虑使用数据增强来提升模型的泛化能力。数据增强是一种通过对原始数据进行随机变换和扩充来更多训练样本的技术。这可以帮助型更好地适不同的场景和变。
以下是一个简单的python代码示例,展示了如何使用keras进行数据增强:
def augment_data(x_train, y_train):
dat = imagedatagenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=02,
shear_range=02,
zoom_range=0.2,
horizontal_flip=true,
fill_mode='nearest
datagen.fit(x_train)
augmented_data = []
augmented_labels = []
for x_batch, y_batch in datagen.flow(x_train, y_train, batch_size=len(x_train)):
augmented_data.append(x_batch)
augmented_labels.append(y_batch)
break
return augmented_data, augmented_labels
迁移学习
迁移学习是一种利用已经在大型数据集上预训练好的模型来解决新问题的技术。通过复用已训练模型的一部分或全部权重,加快模型训练的速度并提高模型的性能。
以下是一个简单的python代码示例,展示了如何使用keras库进行迁移学习:
from keras.applications import vgg16
from keras.models import model
from keras.layers import dense, globalaveragepooling2d
def build_transfer_model_classes):
base_model = vgg16(weights='imagenet', include_top=false)
x = base_model.output
x = globalaveragepooling2d()(x)
x = dense(1024, activation='relu')(x)
predictions = dense(num_classes, activation='softmax')(x)
model model(inputs=base_model.input, outputs=predictions)
for layer in base_model.layers:
layer.trainable = false
return model
超参数调优
在训练模型的过程中,你可能需要调整模型的超参数以得更好的性能。超参数是指在训练过程中会被模型学习的参数,例如学习率、批大小、代次数等。通过尝试不同的超参数组合,可以找到最佳的模型配置。
以下是一个简单的python代码示例,展示了如何使用gridsearchcv进行超参数调优:
from sklearn.model_selection import gridcv
from sklearn.svm import svc
def tune_hyperparameters(x_train, y_train):
param_grid = {'c': [1, 10, 100], 'gamma': [0.1, 0.01 0.001]}
grid_search = gridsearchcv(svc(), param_grid, cv=5)
grid_search.fit(x_train, y_train)
best_params = grid_search.best_params_
best_model = grid_search.best_estimator_
return best_params, best_model
模型部署和应用
一旦你对模型的性能和效果满意,你可以将部署到实际应用中并应用于实际问题。根据你的求,你可以选择将模型封装为api、嵌入到移动应用程序中或者部署到云服务器上。
以下是一个简单的python代码示例,展示了如何使用fl库将模型封装为:
from flask import flask, request, jsonify
app = flask(__name__)
@app.route('/predict', methods=['post'])
def predict():
data = request.get_json()
image =_image(data['image'])
prediction = model.predict(image)
return jsonify({'prediction': prediction})
if __name__ == '__main__':
app.run()
总结
本篇博客介绍了如何使用python从零训练自己的ai模型。以下是本篇博客的主要内容总结:
确定问题和数据集:明确要解决的问题,并选择合适的数据集。
数据预处理:对数据进行清洗、特征提取和数据转换等预处理步骤。
构建模型:选择适合问题的模型架构,并使用python构建模型。
训练模型:定义损失函数和优化算法,并使用训练数据集对模型进行训练。
评估和调优模型:评估模型的性能,并根据需要进行模型的调优。
部署和应用模型:将训练好的模型部署到实际应用中,并使用它解决实际问题。
此外,还介绍了一些进阶技术,包括数据增强、迁移学习和超参数调优,以提升模型的性能和泛化能力。最后,展示了如何将模型封装为api并部署到实际应用中。
希望本篇博客对你在ai模型训练的学习和实践中有所帮助!祝你成功!
到此这篇关于python从零开始训练ai模型的实用教程的文章就介绍到这了,更多相关python训练ai模型的教程内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论