前言
本篇文章开始介绍spark基础知识,包括spark诞生的背景,应用环境以及入门案例等,还是spark学习之旅前,得先安装spark环境才行,具体安装步骤可以看spark环境搭建,让我们接着往下聊。
一、spark概述
(一)spark是什么
spark是apache顶级的开源项目,主要用于处理大规模数据的分析引擎,该引擎的核心数据结构是rdd弹性分布式数据集,这是一种分布式内存抽象,程序员可以使用rdd在大规模集群中做内存运算,并具有一定的容错方式;
spark保留了mapreduce的分布式并行计算的优点,还改进了其较为明显的缺陷,中间数据存储在内存中,大大提高了运行速度,同时还提供了丰富的api,提高了开发速度。
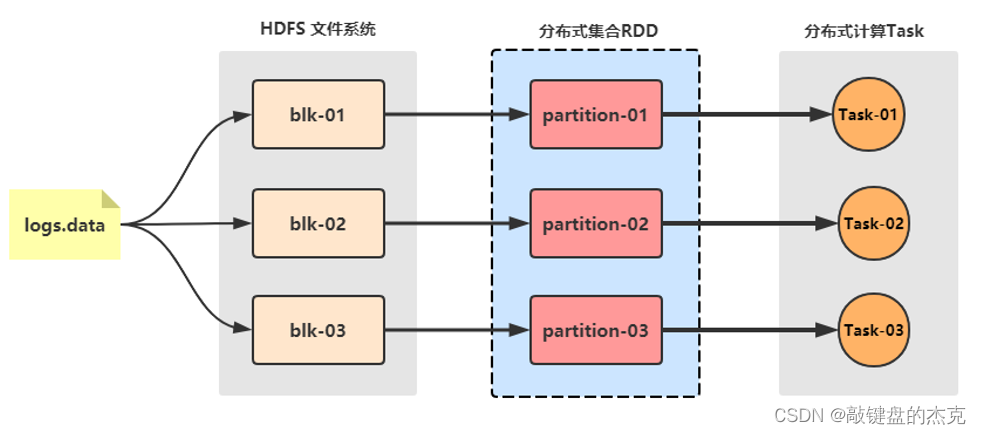
(二)spark的四大特点
spark底层使用scala语言,是一种面向对象、函数式编程语言,能够像操作本地集合一样轻松的操作分布式数据集,spark具有运行速度快、易用性好、通用性强和随处运行等特点;
(1)速度快,spark支持内存计算,并且通过dag有向无环图执行引擎支持无环数据流,相对mapreduce来说,spark处理数据时,可以将中间处理结果数据存储到内存中,spark每个任务以线程方式执行,并不是像mapreduce以进程方式执行,线程的启动和销毁相对于进程来说比较快;
(2)易于使用,spark 支持java、scala、python 、r和sql语言等多种语言;
(3)通用型强,spark 还提供包括spark sql、spark streaming、mlib 及graphx在内的多个工具库,可以在同一个应用中无缝地使用这些工具库;
(4)运行方式多,spark 支持多种运行方式,包括在 hadoop 和 mesos 上,也支持 standalone的独立运行模式,同时也可以运行在云kubernetes上,获取数据的方式也很多,支持从hdfs、hbase、cassandra 及 kafka 等多种途径获取数据。
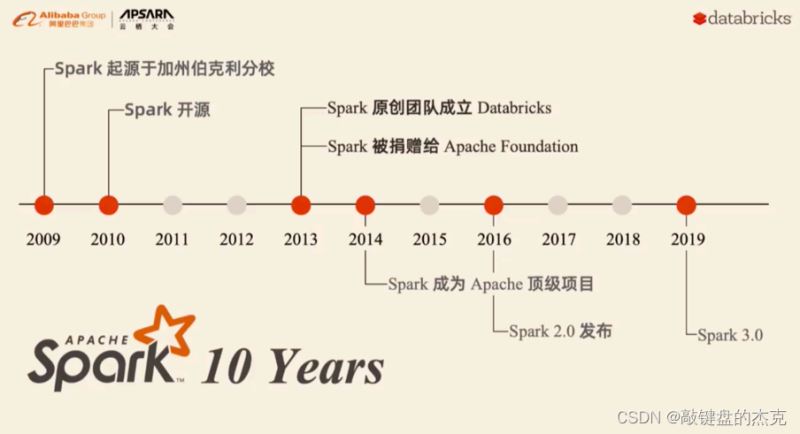
(三)spark的风雨十年
spark的发展主要经历过几大阶段:
(1)2009年spark起源于加州伯克利分校;
(2)2013年被捐赠给apache;
(3)2014年称为apache顶级项目;
(4)2016年spark2.0发布
(5)2019年spark3.0发布
(四)spark框架模块
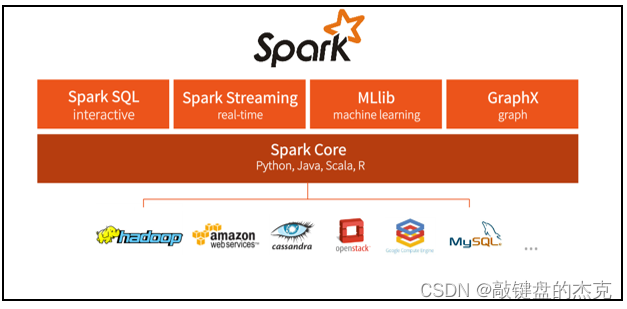
整个spark 框架模块包含:spark core、 spark sql、 spark streaming、 spark graphx和 spark mllib,大部分模块的能力都在建立在其核心引擎之上;
(1)spark core,该模块的数据结构是rdd,实现了spark的基本功能,包括rdd、任务调度、内存管理、错误恢复以及与存储系统交互等;
(2)spark sql,该模块的数据结构主要是dataframe,是spark用来操作结构化数据的程序包,通过该模块,可以直接使用sql操作数据;
(3)spark streaming,其主要的数据结构是dstream离散化流,是spark对实时数据进行流式计算的组件;
(4)spark graphx,该模块的数据结构为rdd或者dataframe,是spark中用于图计算的组件,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法;
(5)spark mllib,该模块的数据结构也是rdd或者dataframe,主要用于机器学习,提供了常见的机器学习功能的程序库,包括分类、回归、聚类等,同时也支持模型评估和数据导入等功能。
(五)spark通信框架
整个spark 框架通信模块为netty,spark 1.6版本引入了netty,在spark 2.0之后,完全使用netty,并移除了akka。
总结
spark保留了mapreduce的分布式计算,基于内存计算,提高的数据的计算能力;
其主要模块有spark core、 spark sql、 spark streaming、 spark graphx和 spark mllib,不仅可以通过sql的方式操作数据,还可以对实时数据进行流式计算,同时也支持机器学习;
spark的特点主要是计算速度快,支持多种编程语言,并且提供了众多友好的api,使得spark的学习成本大大降低了。
以上就是大数据之spark基础环境的详细内容,更多关于spark基础环境的资料请关注代码网其它相关文章!


发表评论