pandas 多层索引操作
多重索引的创建方式有很多,这里我们来看几个常见的方式:
(1)pd.multiindex.from_arrays
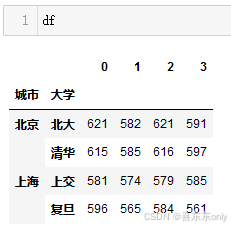
df = pd.dataframe(
[[621,582,621,591],
[615,585,616,597],
[581,574,579,585],
[596,565,584,561]])
# 数组
# 每个数组对应着一个层级的索引值
arrays = [['北京','北京','上海','上海'],['北大','清华','上交','复旦']]
mindex = pd.multiindex.from_arrays(arrays, names=['城市','大学'])
# 给df行索引赋值
df.index = mindex

(2)pd.multiindex.from_frame
# dataframe
# 创建一个dataframe,方式与元组类似,每个元组对应一对多级索引值
frame = pd.dataframe([('北京','北大'),('北京','清华'),('上海','上交'),('上海','复旦')])
mindex = pd.multiindex.from_frame(frame, names=['城市','大学'])
# 给df行索引赋值
df.index = mindex

(3)pd.multiindex.from_tuples
df = pd.dataframe(
[[621,582,621,591],
[615,585,616,597],
[581,574,579,585],
[596,565,584,561]])
# 元组
# 每个元组是对应着一对多级索引
tuples = [('北京','北大'),('北京','清华'),('上海','上交'),('上海','复旦')]
mindex = pd.multiindex.from_tuples(tuples, names=['城市','大学'])
# 给df行索引赋值
df.index = mindex
(4)pd.multiindex.from_product
当我们考虑迭代两个对象的元素对时,可以优先考虑使用pd.multiindex.from_product()来建立多重索引。
# product笛卡尔积
city = ['北京', '上海']
college = ['北大','清华','上交','复旦']
mindex1 = pd.multiindex.from_product([city,college], names=['城市','大学'])
mindex1
multiindex(levels=[['上海', '北京'], ['上交', '北大', '复旦', '清华']],
codes=[[1, 1, 1, 1, 0, 0, 0, 0], [1, 3, 0, 2, 1, 3, 0, 2]],
names=['城市', '大学'])
对两个序列生成笛卡尔积,即两两组合,结果如上。这种方式生成的索引和我们上面想要的形式不同,因此对行索引不适用
# product生成column列索引 year = ['2022','2023'] pro = ['计算机','土木'] mcol = pd.multiindex.from_product([year,pro], names=['年份','专业']) # 对df的行索引、列索引赋值 df.index = mindex df.columns = mcol display(df)

np.r_[]用法:
np.r_[]函数是用于连接数组的函数,类似于concatenate函数,但可以在一维数组和多维数组之间进行拼接。具体用法如下:
使用np.r_[a, b]将两个数组a和b按行连接(在行方向上进行拼接)。
使用np.r_[a, b]对多个数组进行按行连接,可以同时连接多个数组。
使用np.r_[(a, b), (c, d)]将两个二维数组a和b按行连接,并将结果与二维数组c和d按行连接,最终得到一个拼接后的二维数组。
np.r_还支持切片操作,如np.r_[:5, 7:10]表示将索引为0到4的元素和索引为7到9的元素按行连接。
总而言之,np.r_[]函数可以在行方向上将多个数组或切片进行连接,生成一个新的数组。
读取excel方式
def index_info():
address =os.path.join('.','index_def.xlsx')
criterion = pd.read_excel(address)
multi_idx1=criterion['分类'].unique()
multi_idx2=criterion['二级分类'].unique()
idx1 = [multi_idx1[0]]*3+[multi_idx1[2]]*3+[multi_idx1[3]]*16
idx2 = [multi_idx2[0]]*3+['-']*3+[multi_idx2[2]]*6+[multi_idx2[3]]*6+[multi_idx2[4]]*4
criterion.index=pd.multiindex.from_arrays([idx1,idx2,criterion.index+1],names=['一级分类','二级分类','编号'])
ctr_df = criterion.iloc[:,np.r_[3,5]].fillna('-')
return ctr_df
ctr_df = index_info()
ctr_df到此这篇关于pandas 多层索引操作的实现的文章就介绍到这了,更多相关pandas 多层索引内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论