1. hive介绍
hive 是一个基于 hadoop 的数据仓库工具,用于处理大规模的结构化和半结构化数据。hive 的主要目的是提供一种类 sql 的语言,称为 hiveql(或 hql),以便用户可以方便地处理数据,无需编写复杂的 mapreduce 任务。
hive 的基本原理是将 sql 查询转换为 mapreduce 任务,然后在 hadoop 上执行这些任务以处理数据。hive 基于 hadoop 的 hdfs 存储数据,可以处理多种数据格式,例如 csv、tsv、json 等,并支持用户自定义函数(udf)以进行更高级的数据处理。
hive 通常用于大数据场景,例如数据分析、etl(抽取、转换和加载)以及商业智能等。hive 还提供了丰富的工具和可视化界面,方便用户管理和监控数据仓库。
2. hive的基本架构
2.1 用户接口:client
cli(command-line interface)、jdbc/odbc。
说明:jdbc 和 odbc 的区别:
(1)jdbc 的移植性比 odbc 好;(通常情况下,安装完 odbc 驱动程序之后,还 需要经过确定的配置才能够应用。而不相同的配置在不相同数据库服务器之间不能够通用。 所以,安装一次就需要再配置一次。jdbc 只需要选取适当的 jdbc 数据库驱动程序,就 不需要额外的配置。在安装过程中,jdbc 数据库驱动程序会自己完成有关的配置。)
(2)两者使用的语言不同,jdbc 在 java 编程时使用,odbc 一般在 c/c++编程 时使用
2.2 元数据:metastore
元数据包括:数据库(默认是 default)、表名、表的拥有者、列/分区字段、表的类型 (是否是外部表)、表的数据所在目录等。 默认存储在自带的 derby 数据库中,由于 derby 数据库只支持单客户端访问,生产 环境中为了多人开发,推荐使用 mysql 存储 metastore。
2.3 驱动器:driver
- 解析器(sqlparser):将 sql 字符串转换成抽象语法树(ast)
- 语义分析(semantic analyzer):将 ast 进一步划分为 qeuryblock
- 逻辑计划生成器(logical plan gen):将语法树生成逻辑计划
- 逻辑优化器(logical optimizer):对逻辑计划进行优化
- 物理计划生成器(physical plan gen):根据优化后的逻辑计划生成物理计划
- 物理优化器(physical optimizer):对物理计划进行优化
- 执行器(execution):执行该计划,得到查询结果并返回给客户端
3. hive中sql关键字的执行顺序
在 hive 中,查询语句的执行顺序如下:
- from 子句:指定要从哪个表中检索数据;
- where 子句:对数据进行筛选,只有满足条件的数据才会被选中;
- group by 子句:按照指定的列对数据进行分组;
- having 子句:对分组后的数据进行筛选,只有满足条件的分组才会被选中;
- select 子句:选择要查询的列;
- order by 子句:按照指定的列对结果进行排序;
- limit 子句:限制返回结果的数量。
所以,查询语句的执行顺序为:from -> where -> group by -> having -> select -> order by -> limit。
4. 部分关键字的执行原理
4.1 聚合函数
- count(*),表示统计所有行数,包含 null 值,与count(1)含义完全相同;
- count(某列),表示该列一共有多少行,不包含 null 值;
- max(),求最大值,不包含 null,除非所有值都是 null;
- min(),求最小值,不包含 null,除非所有值都是 null;
- sum(),求和,不包含 null;
- avg(),求平均值,不包含 null。
以count为例,每个map任务会对自己读取的数据进行count操作,最后将所有map的count结果发送至reduce中进行总的count计算,完成表中count的计算(max、min、sum的原理和count一致)

avg的计算是每个map任务计算数据的sum与count,之后在reduce中进行汇总,计算sum/count的结果获取平均值。

4.2 分组(group by )
group by 语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。
每个map任务会对读取的文件进行group by分组操作,然后进行组内排序、求和、求最大最小值操作,最后到reduce进行汇总。

4.3 连接( join )
hive 支持通常的 sql join 语句,但是只支持等值连接,不支持非等值连接
join会对输入的数据字段进行分区,key值为字段1,然后进入reduce进行汇总,输出结果。

4.4 笛卡尔积
笛卡尔积一般出现在以下情况:
- 省略连接条件
- 连接条件无效
- 所有表中的所有行互相连接
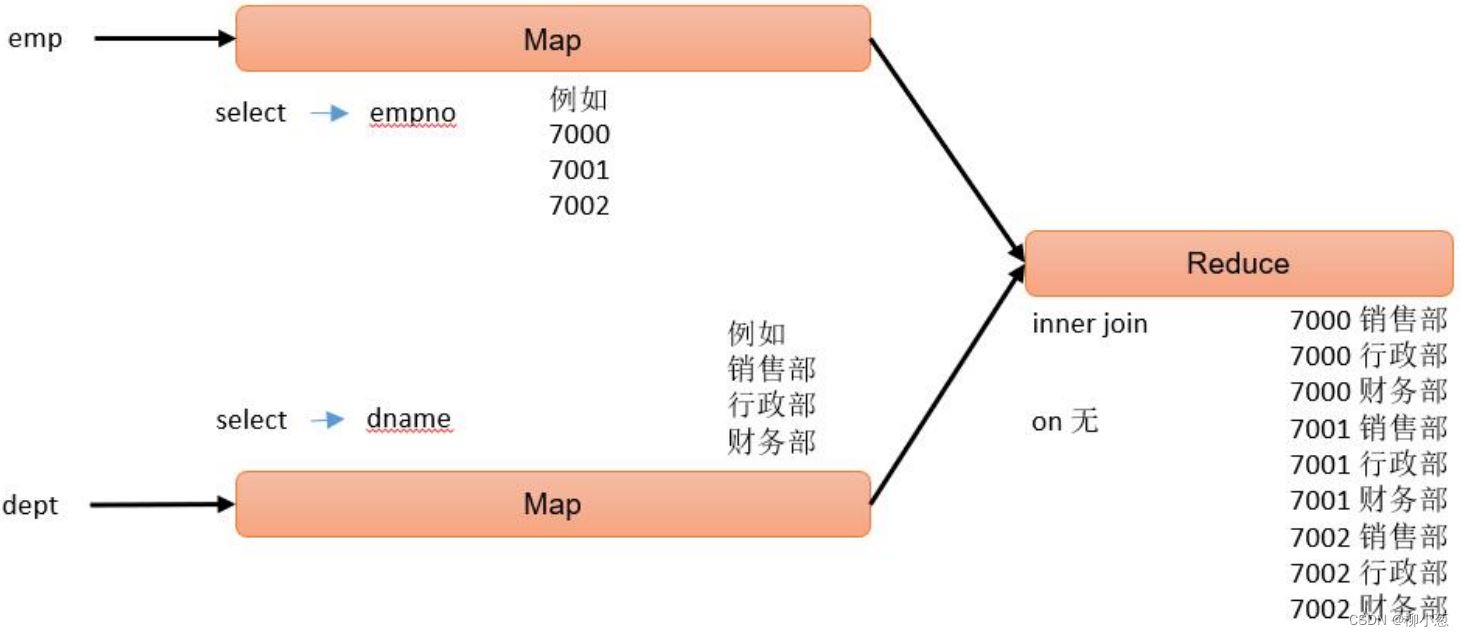
例如:
--笛卡尔积的案例 select empno, dname from emp, dept;
hive sql的执行过程如下:
4.5 联合(union & union all)
union 和 union all 都是上下拼接 sql 的结果,这点是和 join 有区别的,join 是左右关 联,union 和 union all 是上下拼接。union 去重,union all 不去重。 union 和 union all 在上下拼接 sql 结果时有两个要求:
(1)两个 sql 的结果,列的个数必须相同
(2)两个 sql 的结果,上下所对应列的类型必须一致
select* from emp where deptno=10 union select* from emp where deptno=20;
4.6 排序
4.6.1 全局排序(order by)
order by:全局排序,只有一个 reduce。
asc(ascend):升序(默认)
desc(descend):降序
每个map任务中的数据先进行排序,后再汇总到reduce进行排序。

4.6.2 全局排序每个 reduce
内部排序(sort by)
sort by:对于大规模的数据集 order by 的效率非常低。在很多情况下,并不需要全局排序,此时可以使用 sort by。
sort by 为每个 reduce 产生一个排序文件。每个 reduce 内部进行排序,对全局结果集来说不是排序。
--根据部门编号降序查看员工信息 select* from emp sort by deptno desc;

4.7 分区(distribute by)
distribute by:在有些情况下,我们需要控制某个特定行应该到哪个 reducer,通常是为了进行后续的聚集操作。
distribute by 子句可以做这件事。distribute by 类似 mapreduce 中 partition(自定义分区),进行分区,结合 sort by 使用。 对于distribute by进行测试,一定要分配多 reduce 进行处理,否则无法看到 distribute by 的效果。
需要注意的地方:
- distribute by 的分区规则是根据分区字段的 hash 码与 reduce 的个数进行相除后, 余数相同的分到一个区。
- hive 要求 distribute by 语句要写在 sort by 语句之前。
--先按照部门编号分区,再按照员工编号薪资排序 select * from emp distribute by deptno sort by sal desc;

4.8 分区排序(cluster by)
当 distribute by 和 sort by 字段相同时,可以使用 cluster by 方式。 cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是升序排序,不能指定排序规则为 asc 或者 desc。
--按照部门编号分组并排序 select* from emp cluster by deptno; --等价于 select* from emp distribute by deptno sort by deptno;

到此这篇关于关于hive中sql的执行原理解析的文章就介绍到这了,更多相关hive中的sql原理内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论