什么是回表?为什么需要回表?
小伙伴们在面试的时候,有一个特别常见的问题,那就是数据库的回表。
索引结构
要搞明白这个问题,需要大家首先明白 mysql 中索引存储的数据结构。这个其实很多小伙伴可能也都听说过,b+tree 嘛!
b+tree 是什么?那你得先明白什么是 b-tree,来看如下一张图:
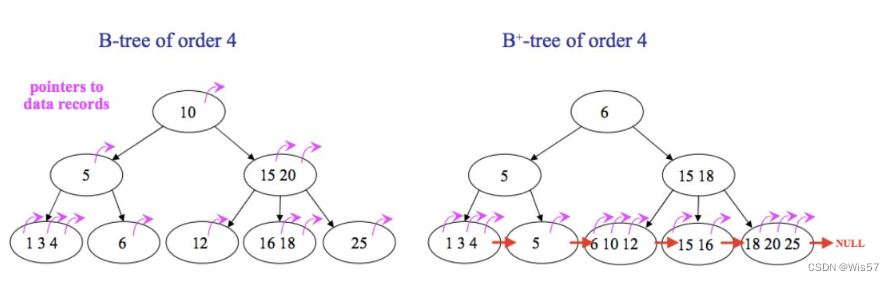
前面是 b-tree,后面是 b+tree,两者的区别在于:
- b-tree 中,所有节点都会带有指向具体记录的指针;
- b+tree 中只有叶子结点会带有指向具体记录的指针。
- b-tree 中不同的叶子之间没有连在一起;
- b+tree 中所有的叶子结点通过指针连接在一起。
- b-tree 中可能在非叶子结点就拿到了指向具体记录的指针,搜索效率不稳定;
- b+tree 中,一定要到叶子结点中才可以获取到具体记录的指针,搜索效率稳定。
基于上面两点分析,我们可以得出如下结论:
b+tree 中,由于非叶子结点不带有指向具体记录的指针,所以非叶子结点中可以存储更多的索引项,这样就可以有效降低树的高度,进而提高搜索的效率。
b+tree 中,叶子结点通过指针连接在一起,这样如果有范围扫描的需求,那么实现起来将非常容易,而对于 b-tree,范围扫描则需要不停的在叶子结点和非叶子结点之间移动。
对于第一点,一个 b+tree 可以存多少条数据呢?以主键索引的 b+tree 为例(二级索引存储数据量的计算原理类似,但是叶子节点和非叶子节点上存储的数据格式略有差异),我们可以简单算一下。
计算机在存储数据的时候,最小存储单元是扇区,一个扇区的大小是 512 字节,而文件系统(例如 xfs/ext4)最小单元是块,一个块的大小是 4kb。
innodb 引擎存储数据的时候,是以页为单位的,每个数据页的大小默认是 16kb,即四个块。
基于这样的知识储备,我们可以大致算一下一个 b+tree 能存多少数据。
假设数据库中一条记录是 1kb,那么一个页就可以存 16 条数据(叶子结点);对于非叶子结点存储的则是主键值+指针,在 innodb 中,一个指针的大小是 6 个字节,假设我们的主键是 bigint ,那么主键占 8 个字节,当然还有其他一些头信息也会占用字节我们这里就不考虑了,我们大概算一下,小伙伴们心里有数即可:
16*1024/(8+6)=1170
即一个非叶子结点可以指向 1170 个页,那么一个三层的 b+tree 可以存储的数据量为:
1170117016=21902400
可以存储 2100万 条数据。
在 innodb 存储引擎中,b+tree 的高度一般为 2-4 层,这就可以满足千万级的数据的存储,查找数据的时候,一次页的查找代表一次 io,那我们通过主键索引查询的时候,其实最多只需要 2-4 次 io 操作就可以了。
大家先搞明白这个 b+tree。
两类索引
大家知道,mysql 中的索引有很多中不同的分类方式,可以按照数据结构分,可以按照逻辑角度分,也可以按照物理存储分,其中,按照物理存储方式,可以分为聚簇索引和非聚簇索引。
我们日常所说的主键索引,其实就是聚簇索引(clustered index);主键索引之外,其他的都称之为非主键索引,非主键索引也被称为二级索引(secondary index),或者叫作辅助索引。
对于主键索引和非主键索引,使用的数据结构都是 b+tree,唯一的区别在于叶子结点中存储的内容不同:
主键索引的叶子结点存储的是一行完整的数据。
非主键索引的叶子结点存储的则是主键值。
这就是两者最大的区别。
所以,当我们需要查询的时候:
如果是通过主键索引来查询数据,例如 select * from user where id=100,那么此时只需要搜索主键索引的 b+tree 就可以找到数据。
如果是通过非主键索引来查询数据,例如 select * from user where username=‘javaboy’,那么此时需要先搜索 username 这一列索引的 b+tree,搜索完成后得到主键的值,然后再去搜索主键索引的 b+tree,就可以获取到一行完整的数据。
对于第二种查询方式而言,一共搜索了两棵 b+tree,第一次搜索 b+tree 拿到主键值后再去搜索主键索引的 b+tree,这个过程就是所谓的回表。
从上面的分析中我们也能看出,通过非主键索引查询要扫描两棵 b+tree,而通过主键索引查询只需要扫描一棵 b+tree,所以如果条件允许,还是建议在查询中优先选择通过主键索引进行搜索。
一定会回表吗?那么不用主键索引就一定需要回表吗?
不一定!
如果查询的列本身就存在于索引中,那么即使使用二级索引,一样也是不需要回表的。
举个例子,我有如下一张表:
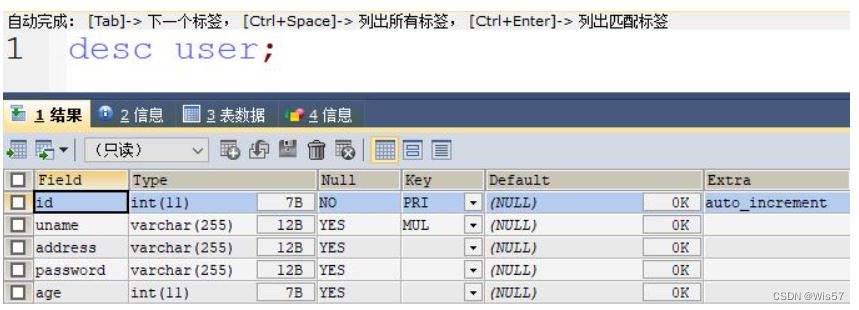
uname 和 address 字段组成了一个复合索引,那么此时,虽然这是一个二级索引,但是索引树的叶子节点中除了保存主键值,也保存了 address 的值。
我们来看如下分析:

可以看到,此时使用到了 uname 索引,但是最后的 extra 的值为 using index,这就表示用到了索引覆盖扫描(覆盖索引),此时直接从索引中过滤不需要的记录并返回命中的结果,这一步是在 mysql 服务器层完成的,并且不需要回表。
扩展
基于第一、二小节的分析,我们再来捋一捋为什么在数据库中建议使用自增主键。
自增主键往往占用空间比较小,int 占 4 个字节,bigint 占 8 个字节。由于二级索引的叶子节点存储的就是主键,所以如果主键占用空间小,意味着二级索引的叶子节点将来占用的空间小(间接降低 b+tree 的高度,提高搜索效率)。
自增主键插入的时候比较快,直接插入即可,不会涉及到叶子节点分裂等问题(不需要挪动其他记录);而其他非自增主键插入的时候,可能要插入到两个已有的数据中间,就有可能导致叶子节点分裂等问题,插入效率低(要挪动其他记录)。
当然,这个是基于技术层面的讨论,如果业务上无法使用自增主键或者有其他要求导致无法使用自增主键,那没办法,在满足新要求的情况下重新选择一个最佳实践吧。
到此这篇关于关于面试中常问的数据库回表问题的文章就介绍到这了,更多相关数据库回表内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论