python解析mysql binlog日志分析情况
1. 分析目的
binlog 中记录了 mysql 数据变动,经常用于时间点恢复、数据闪回、分析一些 “奇怪” 的问题。
例如是否有大事务,哪张表涉及的更新最多?是否有一些事务没有及时提交,都可以通过分析 binlog 来得到答案。
2. 代码逻辑
收集数据的第一步就是要解析 binlog 文件,binlog 是由事件组成的,例如:gtid 事件、xid 事件、table map 事件、dml 事件,只要获得所有的事件,就可以分析到很多东西。
每个事件都由两部分组成,事件头 - 事件体,事件头的存储格式是这样的。
| 类型 | 占用 |
|---|---|
| timestamp | 4 bytes |
| type_code | 1 bytes |
| server_id | 4 bytes |
| event_length | 4 bytes |
| next_position | 4 bytes |
| flags | 2 bytes |
一共占 19 bytes 我们通过 header 可以知道事件类型,发生时间、事件长度、下一个事件开始位置。
读取头信息后,我们就可以通过 next_position 跳到下一个事件开始的位置,读取事件头,如果遇到 table_map 事件则表示要开启一个 dml 事务,那么 table map 事件中存储的是什么呢?

从 table map 中可以获得 dml 要操作的数据库与表信息,这样我们就可以定位到 dml 操作的是哪张表,开启一个事务时,binlog 会先记录 table_map 事件,涉及到多张表就会有多个 table_map 事件,然后就是 dml 事件,最后是一个 xid 事件,表示事务提交。
脚本通过解析 query_event 获得事务的起点,解析 table map 事件获得涉及的表,通过 xid 事件获得事务结束。
3. 实战分析
直接上代码吧~
需要安装 pandas 模块,这个模块处理数据非常方便,如果没有使用过的朋友,建议去把玩下,用好了提升工作效率。
# -*- coding: utf-8 -*-
import sys
import math
import time
import struct
import argparse
import pandas as pd
from datetime import datetime
binlog_quer_event_stern = 4
binlog_event_fix_part = 13
table_map_event_fix_length = 8
binlog_file_header = b'\xfe\x62\x69\x6e'
binlog_event_header_len = 19
class binlogevent:
unknown_event = 0
start_event_v3 = 1
query_event = 2
stop_event = 3
rotate_event = 4
intvar_event = 5
load_event = 6
slave_event = 7
create_file_event = 8
append_block_event = 9
exec_load_event = 10
delete_file_event = 11
new_load_event = 12
rand_event = 13
user_var_event = 14
format_description_event = 15
xid_event = 16
begin_load_query_event = 17
execute_load_query_event = 18
table_map_event = 19
pre_ga_write_rows_event = 20
pre_ga_update_rows_event = 21
pre_ga_delete_rows_event = 22
write_rows_event = 23
update_rows_event = 24
delete_rows_event = 25
incident_event = 26
heartbeat_log_event = 27
ignorable_log_event = 28
rows_query_log_event = 29
write_rows_event_v2 = 30
update_rows_event_v2 = 31
delete_rows_event_v2 = 32
gtid_log_event = 33
anonymous_gtid_log_event = 34
previous_gtids_log_event = 35
class binlogeventget(object):
def __init__(self, binlog_path, outfile_path):
self.file_handle = open(binlog_path, 'rb')
# 分析文件导出的位置
self.outfile_path = outfile_path
def __del__(self):
self.file_handle.close()
def read_table_map_event(self, event_length, next_position):
"""
fix_part = 8
table_id : 6bytes
reserved : 2bytes
variable_part:
database_name_length : 1bytes
database_name : database_name_length bytes + 1
table_name_length : 1bytes
table_name : table_name_length bytes + 1
cloums_count : 1bytes
colums_type_array : one byte per column
mmetadata_lenth : 1bytes
metadata : .....(only available in the variable length field,varchar:2bytes,text、blob:1bytes,time、timestamp、datetime: 1bytes
blob、float、decimal : 1bytes, char、enum、binary、set: 2bytes(column type id :1bytes metadatea: 1bytes))
bit_filed : 1bytes
crc : 4bytes
.........
:return:
"""
self.read_bytes(table_map_event_fix_length)
database_name_length, = struct.unpack('b', self.read_bytes(1))
database_name, _a, = struct.unpack('{}ss'.format(database_name_length),
self.read_bytes(database_name_length + 1))
table_name_length, = struct.unpack('b', self.read_bytes(1))
table_name, _a, = struct.unpack('{}ss'.format(table_name_length), self.read_bytes(table_name_length + 1))
self.file_handle.seek(next_position, 0)
return database_name, table_name
def read_bytes(self, count):
"""
读取固定 bytes 的数据
:param count:
:return:
"""
return self.file_handle.read(count)
def main(self):
if not self.read_bytes(4) == binlog_file_header:
print("error: is not a standard binlog file format.")
sys.exit(0)
# 事务记录字典
temp_transaction_dict = {
'id': none,
'db_name': none,
'ld_table_name': none,
'table_set': set(),
'start_time': none,
'end_time': none,
'diff_second': none,
'event_type': set(),
'start_position': none,
'end_position': none
}
tem_id = 0
df = list()
start_position, end_position = none, none
print('loading.....')
while true:
type_code, event_length, timestamp, next_position = self.read_header()
# 终止循环判断
if type_code is none:
break
# 事务信息收集逻辑判断
if type_code == binlogevent.query_event:
thread_id, db_name, info = self.read_query_event(event_length)
if info == 'begin':
temp_transaction_dict['start_position'] = next_position - event_length
temp_transaction_dict['start_time'] = timestamp
temp_transaction_dict['db_name'] = db_name
# print('time:', timestamp, 'db:', db_name, 'sql:', info)
self.file_handle.seek(next_position, 0)
elif type_code == binlogevent.table_map_event:
with_database, with_table = self.read_table_map_event(event_length, next_position)
# 只记录最开始的一张表
if temp_transaction_dict['ld_table_name'] is none:
temp_transaction_dict['ld_table_name'] = str(with_table.decode())
# 一个事务涉及的所有表集合
temp_transaction_dict['table_set'].add(str(with_table.decode()))
elif type_code in (binlogevent.write_rows_event, binlogevent.write_rows_event_v2):
# print('insert:', type_code, event_length, timestamp, next_position)
temp_transaction_dict['event_type'].add('insert')
self.file_handle.seek(event_length - binlog_event_header_len, 1)
elif type_code in (binlogevent.update_rows_event, binlogevent.update_rows_event_v2):
# print('update:', type_code, event_length, timestamp, next_position)
temp_transaction_dict['event_type'].add('update')
self.file_handle.seek(event_length - binlog_event_header_len, 1)
elif type_code in (binlogevent.delete_rows_event, binlogevent.delete_rows_event_v2):
# print('delete:', type_code, event_length, timestamp, next_position)
temp_transaction_dict['event_type'].add('delete')
self.file_handle.seek(event_length - binlog_event_header_len, 1)
elif type_code == binlogevent.xid_event:
# 补充事务结束信息
temp_transaction_dict['id'] = tem_id
temp_transaction_dict['end_time'] = timestamp
temp_transaction_dict['end_position'] = next_position
_start = datetime.strptime(temp_transaction_dict['start_time'], '%y-%m-%d %h:%m:%s')
_end = datetime.strptime(temp_transaction_dict['end_time'], '%y-%m-%d %h:%m:%s')
temp_transaction_dict['diff_second'] = (_end - _start).seconds
df.append(temp_transaction_dict)
# print(temp_transaction_dict)
# 收尾
temp_transaction_dict = {
'id': none,
'db_name': none,
'ld_table_name': none,
'table_set': set(),
'start_time': none,
'end_time': none,
'diff_second': none,
'event_type': set(),
'start_position': none,
'end_position': none
}
self.file_handle.seek(event_length - binlog_event_header_len, 1)
tem_id += 1
else:
# 如果读取的是一个 header 事件,直接跳过即可。
self.file_handle.seek(event_length - binlog_event_header_len, 1)
outfile = pd.dataframe(df)
outfile['transaction_size_bytes'] = (outfile['end_position'] - outfile['start_position'])
outfile["transaction_size"] = outfile["transaction_size_bytes"].map(lambda x: self.bit_conversion(x))
outfile.to_csv(self.outfile_path, encoding='utf_8_sig')
print('file export directory: {}'.format(self.outfile_path))
print('complete ok!')
def read_header(self):
"""
binlog_event_header_len = 19
timestamp : 4bytes
type_code : 1bytes
server_id : 4bytes
event_length : 4bytes
next_position : 4bytes
flags : 2bytes
"""
read_byte = self.read_bytes(binlog_event_header_len)
if read_byte:
result = struct.unpack('=ibiiih', read_byte)
type_code, event_length, timestamp, next_position = result[1], result[3], result[0], result[4]
return type_code, event_length, time.strftime('%y-%m-%d %h:%m:%s',
time.localtime(
timestamp)), next_position
else:
return none, none, none, none
def read_query_event(self, event_length=none):
"""
fix_part = 13:
thread_id : 4bytes
execute_seconds : 4bytes
database_length : 1bytes
error_code : 2bytes
variable_block_length : 2bytes
variable_part :
variable_block_length = fix_part.variable_block_length
database_name = fix_part.database_length
sql_statement = event_header.event_length - 19 - 13 - variable_block_length - database_length - 4
"""
read_byte = self.read_bytes(binlog_event_fix_part)
fix_result = struct.unpack('=iibhh', read_byte)
thread_id = fix_result[0]
self.read_bytes(fix_result[4])
read_byte = self.read_bytes(fix_result[2])
database_name, = struct.unpack('{}s'.format(fix_result[2]), read_byte)
statement_length = event_length - binlog_event_fix_part - binlog_event_header_len \
- fix_result[4] - fix_result[2] - binlog_quer_event_stern
read_byte = self.read_bytes(statement_length)
_a, sql_statement, = struct.unpack('1s{}s'.format(statement_length - 1), read_byte)
return thread_id, database_name.decode(), sql_statement.decode()
@staticmethod
def bit_conversion(size, dot=2):
size = float(size)
if 0 <= size < 1:
human_size = str(round(size / 0.125, dot)) + ' b'
elif 1 <= size < 1024:
human_size = str(round(size, dot)) + ' b'
elif math.pow(1024, 1) <= size < math.pow(1024, 2):
human_size = str(round(size / math.pow(1024, 1), dot)) + ' kb'
elif math.pow(1024, 2) <= size < math.pow(1024, 3):
human_size = str(round(size / math.pow(1024, 2), dot)) + ' mb'
elif math.pow(1024, 3) <= size < math.pow(1024, 4):
human_size = str(round(size / math.pow(1024, 3), dot)) + ' gb'
elif math.pow(1024, 4) <= size < math.pow(1024, 5):
human_size = str(round(size / math.pow(1024, 4), dot)) + ' tb'
elif math.pow(1024, 5) <= size < math.pow(1024, 6):
human_size = str(round(size / math.pow(1024, 5), dot)) + ' pb'
elif math.pow(1024, 6) <= size < math.pow(1024, 7):
human_size = str(round(size / math.pow(1024, 6), dot)) + ' eb'
elif math.pow(1024, 7) <= size < math.pow(1024, 8):
human_size = str(round(size / math.pow(1024, 7), dot)) + ' zb'
elif math.pow(1024, 8) <= size < math.pow(1024, 9):
human_size = str(round(size / math.pow(1024, 8), dot)) + ' yb'
elif math.pow(1024, 9) <= size < math.pow(1024, 10):
human_size = str(round(size / math.pow(1024, 9), dot)) + ' bb'
elif math.pow(1024, 10) <= size < math.pow(1024, 11):
human_size = str(round(size / math.pow(1024, 10), dot)) + ' nb'
elif math.pow(1024, 11) <= size < math.pow(1024, 12):
human_size = str(round(size / math.pow(1024, 11), dot)) + ' db'
elif math.pow(1024, 12) <= size:
human_size = str(round(size / math.pow(1024, 12), dot)) + ' cb'
else:
raise valueerror('bit_conversion error')
return human_size
if __name__ == '__main__':
parser = argparse.argumentparser(description='a piece of binlog analysis code.')
parser.add_argument('--binlog', type=str, help='binlog file path.', default=none)
parser.add_argument('--outfile', type=str, help='analyze the file export directory.', default=none)
args = parser.parse_args()
if not args.binlog or not args.outfile:
parser.print_help()
sys.exit(0)
binlog_show = binlogeventget(args.binlog, args.outfile)
binlog_show.main()➜ desktop python3 binlogshow.py --help usage: binlogshow.py [-h] [--binlog binlog] [--outfile outfile] a piece of binlog analysis code. optional arguments: -h, --help show this help message and exit --binlog binlog binlog file path. --outfile outfile analyze the file export directory. ➜ desktop
指定 binlog 文件目录和导出分析文件目录即可。
➜ desktop python3 binlogshow.py --binlog=/users/cooh/desktop/mysql-bin.009549 --outfile=/users/cooh/desktop/binlogshow.csv loading..... file export directory: /users/cooh/desktop/binlogshow.csv complete ok!
运行完成后就会得到程序解析后的信息,我们根据这份文件,写一些分析代码即可。
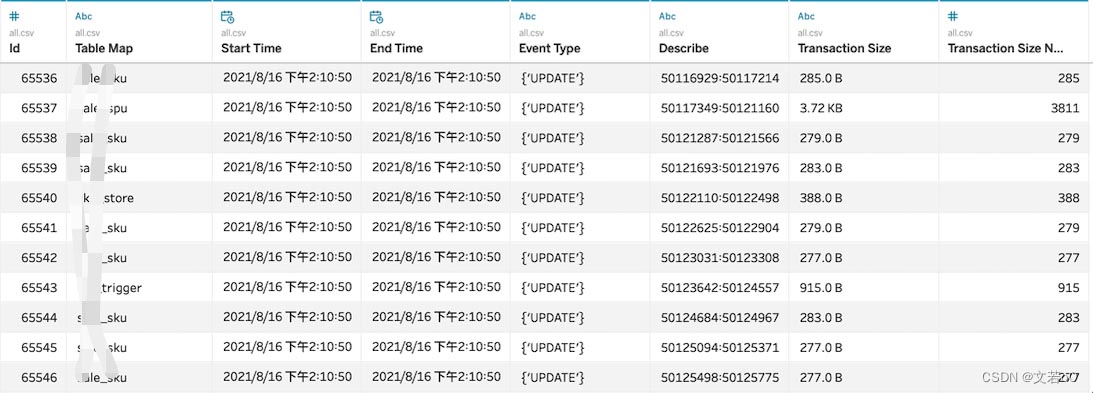
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。






发表评论