一、logistic回归简介
logistic回归是一种线性模型,用于二分类问题。它通过sigmoid函数将线性回归的输出映射到(0, 1)区间内,从而得到样本属于某一类的概率。对于多分类问题,可以使用softmax函数将输出映射到多个类别上,使得每个类别的输出概率之和为1。
logistic回归模型的一般形式为:
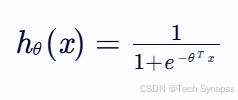
其中,θ 是模型参数,x 是输入特征。
对于多分类问题,假设有 k 个类别,则softmax函数的形式为:
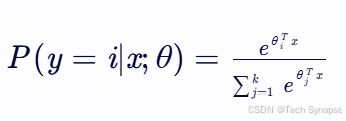
其中,θi 是第 i 个类别的参数向量。
二、数据准备
在实现多分类logistic回归之前,我们需要准备一些数据。这里我们使用经典的iris数据集,该数据集包含三个类别的鸢尾花,每个类别有50个样本,每个样本有4个特征。
以下是数据准备的代码:
import pandas as pd from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import standardscaler # 加载iris数据集 iris = load_iris() data = pd.dataframe(data=iris.data, columns=iris.feature_names) data['target'] = iris.target # 显示数据的前5行 print(data.head()) # 划分训练集和测试集 x = data[iris.feature_names] # 特征 y = data['target'] # 目标变量 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42) # 特征缩放 scaler = standardscaler() x_train = scaler.fit_transform(x_train) x_test = scaler.transform(x_test)
三、模型训练
在训练多分类logistic回归模型时,我们需要使用logisticregression类,并指定multi_class='multinomial'参数以使用多项逻辑回归。此外,我们还需要指定优化算法,这里使用solver='lbfgs'。
以下是模型训练的代码:
from sklearn.linear_model import logisticregression
# 创建logistic回归模型
model = logisticregression(multi_class='multinomial', solver='lbfgs')
# 训练模型
model.fit(x_train, y_train)
# 输出模型的训练分数
print(f'training score: {model.score(x_train, y_train)}')
四、模型评估
训练完模型后,我们需要对模型进行评估,以了解其在测试集上的表现。常用的评估指标包括准确率、混淆矩阵和分类报告。
以下是模型评估的代码:
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 对测试集进行预测
y_pred = model.predict(x_test)
# 计算和显示准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'accuracy: {accuracy}')
# 计算和显示混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print('confusion matrix:\n', conf_matrix)
# 计算和显示分类报告
print(classification_report(y_test, y_pred))
五、代码整合与运行
以下是完整的代码示例,可以直接运行:
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import standardscaler
from sklearn.linear_model import logisticregression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 加载iris数据集
iris = load_iris()
data = pd.dataframe(data=iris.data, columns=iris.feature_names)
data['target'] = iris.target
# 显示数据的前5行
print(data.head())
# 划分训练集和测试集
x = data[iris.feature_names] # 特征
y = data['target'] # 目标变量
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)
# 特征缩放
scaler = standardscaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# 创建logistic回归模型
model = logisticregression(multi_class='multinomial', solver='lbfgs')
# 训练模型
model.fit(x_train, y_train)
# 输出模型的训练分数
print(f'training score: {model.score(x_train, y_train)}')
# 对测试集进行预测
y_pred = model.predict(x_test)
# 计算和显示准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'accuracy: {accuracy}')
# 计算和显示混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print('confusion matrix:\n', conf_matrix)
# 计算和显示分类报告
print(classification_report(y_test, y_pred))
六、结果分析
运行上述代码后,你将得到模型的训练分数、准确率、混淆矩阵和分类报告。以下是对这些结果的分析:
- 训练分数:这是模型在训练集上的准确率,通常会比测试集上的准确率要高。如果训练分数过高而测试分数过低,可能表明模型出现了过拟合。
- 准确率:这是模型在测试集上的准确率,是衡量模型性能的重要指标。准确率越高,说明模型的性能越好。
- 混淆矩阵:混淆矩阵是一个表格,用于显示模型在各个类别上的预测结果。通过混淆矩阵,我们可以了解模型在各个类别上的表现,以及是否存在类别混淆的情况。
- 分类报告:分类报告提供了每个类别的精确率、召回率和f1分数等指标。精确率表示预测为正样本的实例中真正为正样本的比例;召回率表示所有真正的正样本中被正确预测的比例;f1分数是精确率和召回率的调和平均数,用于综合衡量模型的性能。
七、模型优化
虽然上述代码已经实现了一个基本的多分类logistic回归模型,但在实际应用中,我们可能还需要对模型进行优化,以提高其性能。以下是一些常用的优化方法:
- 特征选择:选择对模型性能有重要影响的特征进行训练,可以提高模型的准确性和泛化能力。
- 正则化:通过添加正则化项来防止模型过拟合。logistic回归中常用的正则化方法包括l1正则化和l2正则化。
- 调整超参数:通过调整模型的超参数(如学习率、迭代次数等)来优化模型的性能。
- 集成学习:将多个模型的预测结果进行组合,以提高模型的准确性和稳定性。常用的集成学习方法包括袋装法(bagging)和提升法(boosting)。
八、结论
本文详细介绍了如何使用python实现一个多分类的logistic回归模型,并给出了详细的代码示例。通过数据准备、模型训练、模型评估和结果分析等步骤,我们了解了多分类logistic回归的基本实现流程。此外,本文还介绍了模型优化的一些常用方法,以帮助读者在实际应用中提高模型的性能。希望本文能为初学者提供有价值的参考,并在实践中不断提升自己的技能。
以上就是基于python实现一个多分类的logistic回归模型的代码示例的详细内容,更多关于python logistic回归模型的资料请关注代码网其它相关文章!





发表评论