一、python-docx简介
python自动化操作word最常用的模块就是python-docx。
python-docx模块处理word文档,处理方式是面向对象的。也就是说python-docx模块会把word文档,文档中的段落、文本、字体等都看做对象,对对象进行处理就是对word文档的内容处理。
如果需要读取word文档中的文字(一般来说,程序也只需要认识word文档中的文字信息),需要先了解python-docx模块的几个概念。
word文档一般可以结构化成三个部分:
- document,表示一个word文档
- paragraph,表示word文档中的一个段落
- run,表示段落中的文字块
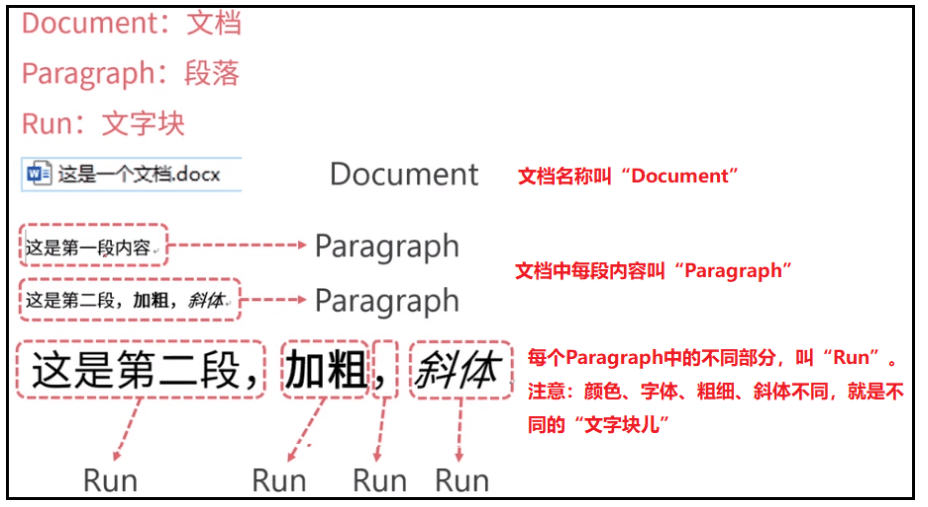
document - paragraph - run三级结构,这是最普遍的情况。但是如果word中存在表格,这时会有新的文档结构,如下:

这时的结构非常类似excel, 可以看成document-table-row/column-cells四级结构。
# 安装 pip install python-docx
二、基本使用
1、新建与保存word
from docx import document document = document() #创建一个空文档 document.save(r'd:\自动化\word\道德经.docx') # 保存文件
2、写入word
from docx import document # 导入docx库
from docx.shared import inches, cm # 导入英寸单位 厘米cm (可用于指定图片大小、表格宽高等)
# 打开一个document
file_path = r'd:\自动化\word\道德经.docx'
document = document(file_path)
# 设置标题段落
document.add_heading('道德经', 0)
# 添加段落
p = document.add_paragraph('道可道,非常道;名可名,非常名。')
p.add_run('无名,天地之始,').bold = true # 在指定段落后添加粗体文字
p.add_run('有名,') # 在指定段落后添加默认格式文字
p.add_run('万物之母。').italic = true # 在指定段落后添加斜体文字
# 添加1级标题=标题1
document.add_heading('故常无欲,', level=1)
# 添加指定格式段落 style后面则是样式
document.add_paragraph('以观其妙,', style='intense quote')
# 添加段落,样式为list bullet类型
document.add_paragraph('常有欲,以观其徼。', style='list bullet')
# 添加段落,样式为list number类型
document.add_paragraph('此两者,同出而异名,同谓之玄,玄之又玄,众妙之门。', style='listnumber')
document.add_paragraph('所以说,霸夫老师教python,教得妙。', style='list number')
# 添加图片
img_path = r'd:\自动化\word\girl.png'
document.add_picture(img_path)
document.add_picture(img_path, width=inches(1.25))
document.add_picture(img_path, width=cm(5), height=cm(5))
# 待添加到表格的内容
records = (
(1, '李白', '诗仙'),
(2, '杜甫', '诗圣'),
(3, '白居易', '香山居士, 与元稹并称元白, 与刘禹锡合称刘白')
)
# 添加一个1行3列的表格, 表格样式为table grid
# 表格样式参数可选,缺省时为normal table
# normal table
# table grid
# light shading、 light shading accent 1 至 light shading accent 6
# light list、light list accent 1 至 light list accent 6
# light grid、light grid accent 1 至 light grid accent 6
# 太多了其它省略...
table = document.add_table(rows=1, cols=3, style='table grid')
# 填充标题行
hdr_cells = table.rows[0].cells
hdr_cells[0].text = '序号'
hdr_cells[1].text = '姓名'
hdr_cells[2].text = '描述'
# 动态添加数据行
for id, name, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(id)
row_cells[1].text = name
row_cells[2].text = desc
document.add_paragraph('再添加一个表格')
# 待添加到表格的内容
records2 = [
["姓名", "性别", "家庭地址"],
["貂蝉", "女", "河北省"],
["杨贵妃", "女", "贵州省"],
["西施", "女", "山东省"]
]
# 添加一个4行3列的表格
table2 = document.add_table(rows=4, cols=3, style='light list accent 5')
# 填充表格
for 行索引 in range(4):
cells = table2.rows[行索引].cells
for 列索引 in range(3):
cells[列索引].text = str(records2[行索引][列索引])
# 添加分页符
document.add_page_break()
# 保存文档
document.save(file_path)
(1)打开文档
document()传入参数是打开相应的文档,不传参数则是创建一个空文档。
# 创建一个空文档
document = document()
# 加载旧文档(用于修改或添加内容)
document = document('exist.docx')
(2)添加标题
level等级1-9 也就是标题1-标题9,我们可以在旧文档中将标题格式设置好,使用python-docx打开旧文档,再添加相应等级标题即可。
document.add_heading('一级标题', level=1)
(3)添加段落
段落在 word 中是基本内容。它们用于正文文本,也用于标题和项目列表(如项目符号)。
添加段落的时候,赋值给一个变量,方便我们后面进行格式调整。
p = document.add_paragraph('道可道,非常道;名可名,非常名。')
# 添加指定格式段落 style后面则是样式
document.add_paragraph('以观其妙,', style='intense quote')
(4)添加文字块
在指定段落上添加文字块。
p.add_run('无名,天地之始,').bold = true # 在指定段落后添加粗体文字
p.add_run('有名,') # 在指定段落后添加默认格式文字
p.add_run('万物之母。').italic = true # 在指定段落后添加斜体文字
(5)添加图片
width, height可用于设置图片尺寸,缺省时为图片默认大小。
document.add_picture('girl.png')
document.add_picture('girl.png', width=inches(1.25))
document.add_picture('girl.png', width=cm(5), height=cm(5))
(6)添加表格
表格样式style参数可选,缺省时默认为normal table。
常用样式有:
normal table
table grid
light shading、 light shading accent 1 至 light shading accent 6
light list、light list accent 1 至 light list accent 6
light grid、light grid accent 1 至 light grid accent 6
# 添加一个4行3列的表格 table = document.add_table(rows=4, cols=3) table = document.add_table(rows=4, cols=3, style='light shading accent 2')
(7)添加分页符
# 添加分页符 document.add_page_break()
3、读取word
''' 文档.paragraphs可以获取文档中所有段落数据,不包含表格,这里注意一点图片跟分页符也会计算在段落数据内 段落.runs 可以获取段落的所有文字块 文档.tables可以获取文档中所有表格数据 文档.save (path) 可以用于保存修改后的文档本身,同样也可在将打开的文档另存为新文档 ''' from docx import document doc = document(r'd:\自动化\word\道德经.docx') # 读取 word 中所有内容 for p in doc.paragraphs: print(p, p.text) # 读取指定段落中的所有run for run in doc.paragraphs[1].runs: print(run, run.text) # 读取 word中所有表格内容 for 表格 in doc.tables: print(表格) for 行 in 表格.rows: for 单元格 in 行.cells: print(单元格.text) doc.save(r'd:\自动化\word\另存为新文档.docx')
到此这篇关于python使用python-docx处理word的方法示例的文章就介绍到这了,更多相关python-docx处理word内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论