数据离散化是将连续变量转换为离散类别(区间)的过程,常用于数据预处理和特征工程阶段。它可以帮助提升模型性能,特别是在分类问题中,因为许多算法对离散特征的处理比连续特征更有效。以下是 pandas 中数据离散化的概述:
1. 离散化的目的
离散化的目的一般包括:
- 简化模型:通过将连续变量转换为类别,模型变得更简单,解释更明确。
- 提升性能:某些算法(如决策树)在处理离散特征时表现更好。
- 降低噪声:分组可以去除一些细微的波动,将关注点集中在更重要的趋势上。
2. 离散化方法
以下是几种常用的离散化方法:
2.1 等宽离散化(equal width binning)
将数据范围均匀分成若干个区间,每个区间的宽度相同。
import pandas as pd
data = {'values': [1, 7, 5, 9, 3, 6, 4, 8]}
df = pd.dataframe(data)
# 使用 pd.cut 进行等宽离散化
df['binned'] = pd.cut(df['values'], bins=3)
print(df)2.2 等频离散化(equal frequency binning)
将数据按数量分成若干组,让每个组中的数据数量相等。
# 使用 pd.qcut 进行等频离散化 df['quantile_binned'] = pd.qcut(df['values'], q=3) print(df)
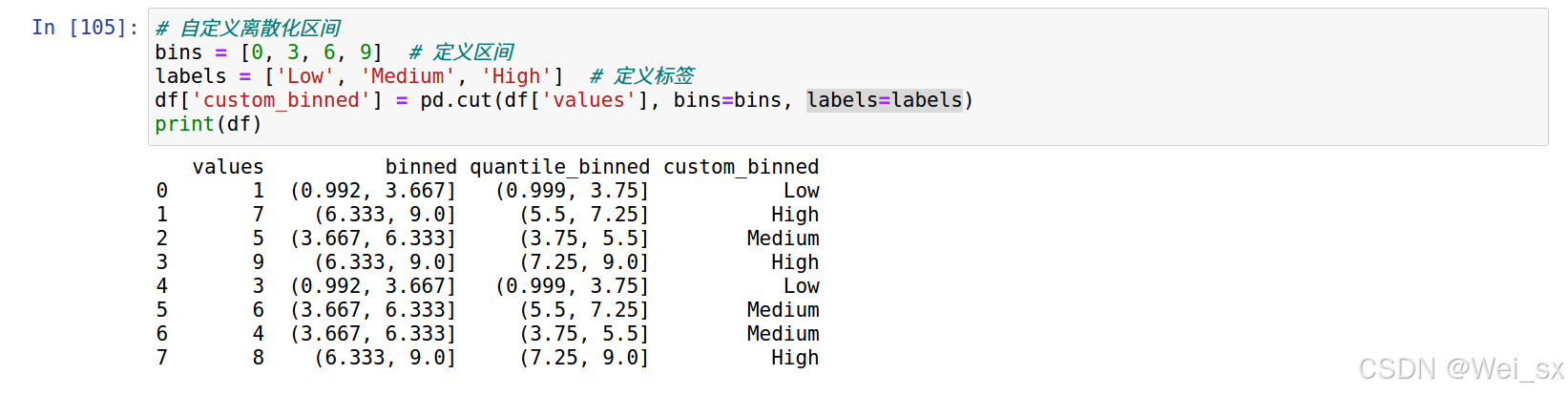
2.3 自定义间隔离散化
可以根据具体需求自定义分箱区间。
# 自定义离散化区间 bins = [0, 3, 6, 9] # 定义区间 labels = ['low', 'medium', 'high'] # 定义标签 df['custom_binned'] = pd.cut(df['values'], bins=bins, labels=labels) print(df)
3. 离散化与其他函数的结合
离散化可以与其他 pandas 功能结合使用,如 `groupby`,以基于离散化的结果进行统计分析。
# 使用离散化后的结果进行分组统计
grouped = df.groupby('custom_binned').count()
print(grouped)
4. 注意事项
- 选择合适的离散化方法: 根据数据的特性和分析的目的选择合适的离散化方法。
- 避免信息损失: 离散化可能会导致信息损失,因此应谨慎选择离散区间数量和边界。
- 验证与调整: 在模型评估时,应验证离散化对性能的影响,必要时调整离散化策略。
5. 总结
在数据预处理中,离散化是一项重要技术,通过将连续变量转换为离散类别,可以简化数据分析和建模过程。pandas 提供了方便的方法(如 `cut` 和 `qcut`)来进行数据离散化,灵活适应不同的需求。
到此这篇关于pandas中数据离散化的实现的文章就介绍到这了,更多相关pandas 数据离散化内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论