使用 python 和 labelme 实现图片验证码的自动标注
在处理图片验证码时,手动标注是一项耗时且枯燥的工作。本文将介绍如何使用 python 和 labelme 实现图片验证码的自动标注。通过结合 paddleocr 实现自动识别,再生成 labelme 格式的标注文件,大幅提升工作效率。
环境准备
必备工具
- python 3.7+
- paddleocr(支持文字识别)
- opencv(图像处理)
- labelme(标注工具)
安装依赖
使用以下命令安装所需库:
pip install paddleocr labelme opencv-python
实现自动标注
自动标注分为以下几个步骤:
- 加载图片:读取图片文件,确保格式正确。
- 图像预处理:对验证码图片进行灰度化和二值化处理,优化识别效果。
- ocr 识别:使用 paddleocr 获取验证码中的文字和位置。
- 生成标注文件:根据 ocr 结果创建符合 labelme 格式的 json 文件。
核心代码实现
以下是完整的自动标注脚本:
import os
import cv2
from paddleocr import paddleocr
def auto_label_image(image_path, output_path):
# 检查文件是否存在
if not os.path.exists(image_path):
print(f"error: file not found: {image_path}")
return
# 加载图像
image = cv2.imread(image_path)
if image is none:
print(f"error: failed to load image. check the file path or format: {image_path}")
return
# 图像预处理
gray_image = cv2.cvtcolor(image, cv2.color_bgr2gray)
_, binary_image = cv2.threshold(gray_image, 128, 255, cv2.thresh_binary)
# 保存预处理后的图片(可选,用于调试)
preprocessed_path = os.path.join(output_path, "processed_image.jpg")
cv2.imwrite(preprocessed_path, binary_image)
# 初始化 ocr
ocr = paddleocr(use_angle_cls=true, lang='en')
# ocr 识别
results = ocr.ocr(preprocessed_path)
if not results or not results[0]:
print(f"no text detected in the image: {image_path}")
return
# 获取图像尺寸
image_height, image_width, _ = image.shape
# 构建标注 json
label_data = {
"version": "4.5.7",
"flags": {},
"shapes": [],
"imagepath": os.path.basename(image_path),
"imagedata": none,
"imageheight": image_height,
"imagewidth": image_width,
}
# 遍历 ocr 结果
for line in results[0]:
points = line[0] # 字符位置 [左上, 右上, 右下, 左下]
text = line[1][0] # 识别的文本
shape = {
"label": text,
"points": [points[0], points[2]], # 左上角和右下角
"group_id": none,
"shape_type": "rectangle",
"flags": {}
}
label_data["shapes"].append(shape)
# 保存标注 json
json_path = os.path.join(output_path, os.path.basename(image_path).replace('.jpg', '.json'))
with open(json_path, 'w') as f:
import json
json.dump(label_data, f, indent=4)
print(f"saved labelme annotation: {json_path}")
# 示例
image_path = r"c:\users\wangzq\desktop\images\captcha.jpg"
output_path = "./annotations"
os.makedirs(output_path, exist_ok=true)
auto_label_image(image_path, output_path)核心逻辑解析
图像预处理
为了提高 ocr 的识别精度,对验证码图片进行灰度化和二值化处理:
gray_image = cv2.cvtcolor(image, cv2.color_bgr2gray) _, binary_image = cv2.threshold(gray_image, 128, 255, cv2.thresh_binary)
二值化处理可以去除背景噪声,使字符更加清晰。
ocr 识别
使用 paddleocr 对图片进行文字检测和识别,返回检测框和文字内容:
ocr = paddleocr(use_angle_cls=true, lang='en') results = ocr.ocr(preprocessed_path)
如果 results 为空,说明 ocr 未检测到任何文本。
生成标注文件
根据 ocr 结果,生成 labelme 格式的标注文件,关键字段包括:
- shapes:标注框信息,包括位置和对应文字。
- imageheight 和 imagewidth:图像的尺寸。
运行结果
- 输出预处理图片:在指定路径下保存经过预处理的图片(
processed_image.jpg)。 - 生成标注文件:在
output_path目录下生成与图片同名的.json文件。 - 无文本检测提示:如果未检测到任何文本,提示
no text detected in the image。
扩展与优化
模型适配
如果验证码中的字符种类较复杂,可以考虑训练一个专用模型,替代通用的 paddleocr。
批量处理
针对多张图片验证码,可以将脚本扩展为批量处理模式:
for image_file in os.listdir(input_folder):
image_path = os.path.join(input_folder, image_file)
auto_label_image(image_path, output_path)标注类型扩展
目前代码仅支持矩形框标注。如果需要支持多边形标注,可以调整 shape_type 为 polygon 并提供相应点坐标。
总结
本文介绍了如何使用 python 和 labelme 自动标注图片验证码,从图像预处理到生成标注文件的完整流程。通过 paddleocr 的结合,可以快速实现验证码字符的自动标注,节省大量时间和精力。
测试
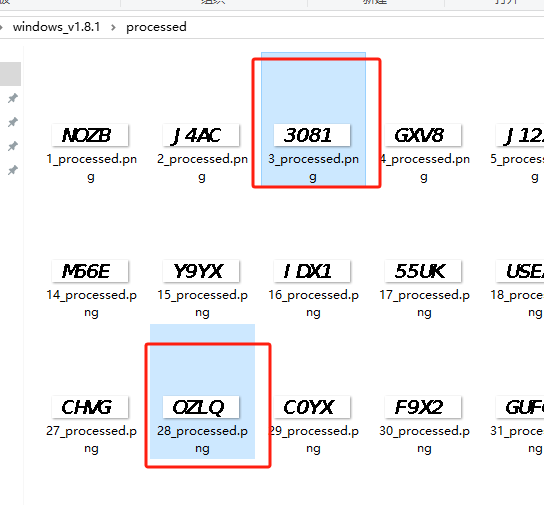
运行完脚本,出来json
{
"version": "4.5.7",
"flags": {},
"shapes": [
{
"label": "ozlq",
"points": [
[
6.0,
1.0
],
[
68.0,
21.0
]
],
"group_id": null,
"shape_type": "rectangle",
"flags": {}
}
],
"imagepath": "captcha.png",
"imagedata": null,
"imageheight": 22,
"imagewidth": 76
}{
"version": "4.5.7",
"flags": {},
"shapes": [
{
"label": "3081",
"points": [
[
6.0,
1.0
],
[
63.0,
21.0
]
],
"group_id": null,
"shape_type": "rectangle",
"flags": {}
}
],
"imagepath": "captcha.png",
"imagedata": null,
"imageheight": 22,
"imagewidth": 76
}目前较为复杂还需要深度研究
到此这篇关于使用 python 和 labelme 实现图片验证码的自动标注的文章就介绍到这了,更多相关python图片验证码自动标注内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论