背景
事情的开始是这样的,前段时间接了个需求,给公司的商城官网提供一个查询预计送达时间的接口。接口很简单,根据请求传的城市+仓库+发货时间查询快递的预计送达时间。因为商城下单就会调用这个接口,所以对接口的性能要求还是挺高的,据老员工的说法是特别是大促的时候,访问量还是比较大的。
因为数据量不是很大,每天会全量推今天和明天的预计送达时间到mysql,总数据量大约7k+。每次推完数据后会把数据全量写入到redis中,做一个缓存预热,然后设置过期时间为1天。
鉴于之前redis集群出现过压力过大查询缓慢的情况,进一步保证接口的高性能和高可用,防止redis出现压力大,查询慢,缓存雪崩,缓存穿透等问题,我们最终采用了reids + caffeine两级缓存的策略。
本地缓存优缺点
优点:
- 本地缓存,基于本地内存,查询速度是很快的。适用于:实时性要求不高,更新频率不高等场景。(我们的数据每天凌晨更新一次,总量7k左右)
- 查询本地缓存与查询远程缓存相比可以减少网络的i/o,降低网络上的一些消耗。(我们的redis之前出现过查询缓慢的情况)
缺点:
- caffeine既然是本地缓存,在分布式环境的情况下就要考虑各个节点之间缓存的一致性问题,一个节点的本地缓存更新了,怎么可以同步到其他的节点。
- caffeine不支持持久化的存储。
- caffeine使用本地内存,需要合理设置大小,避免内存溢出。
流程图
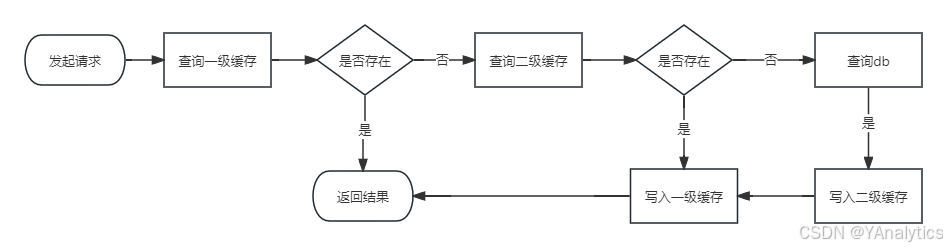
代码实现
mysql表
create table `t_estimated_arrival_date` ( `id` int(11) unsigned not null auto_increment comment '主键id', `warehouse_id` varchar(32) character set utf8mb4 collate utf8mb4_general_ci null default null comment '货仓id', `warehouse` varchar(255) character set utf8mb4 collate utf8mb4_general_ci null default null comment '发货仓', `city` varchar(255) character set utf8mb4 collate utf8mb4_general_ci null default null comment '签收城市', `delivery_date` date null default null comment '发货时间', `estimated_arrival_date` date null default null comment '预计到货日期', primary key (`id`) using btree, unique index `uk_warehouse_id_city_delivery_date`(`warehouse_id`, `city`, `delivery_date`) using btree ) engine = innodb comment = '预计到货时间表(具体到day:t, t+1,近90天到货时间众数)' row_format = dynamic; insert into `t_estimated_arrival_date` values (9, '6', '湖熟正常仓', '兰州市', '2024-07-08', '2024-07-10'); insert into `t_estimated_arrival_date` values (10, '6', '湖熟正常仓', '兰州市', '2024-07-09', '2024-07-11'); insert into `t_estimated_arrival_date` values (11, '6', '湖熟正常仓', '兴安盟', '2024-07-08', '2024-07-11'); insert into `t_estimated_arrival_date` values (12, '6', '湖熟正常仓', '兴安盟', '2024-07-09', '2024-07-12'); insert into `t_estimated_arrival_date` values (13, '6', '湖熟正常仓', '其他', '2024-07-08', '2024-07-19'); insert into `t_estimated_arrival_date` values (14, '6', '湖熟正常仓', '其他', '2024-07-09', '2024-07-20'); insert into `t_estimated_arrival_date` values (15, '6', '湖熟正常仓', '内江市', '2024-07-08', '2024-07-10'); insert into `t_estimated_arrival_date` values (16, '6', '湖熟正常仓', '内江市', '2024-07-09', '2024-07-11'); insert into `t_estimated_arrival_date` values (17, '6', '湖熟正常仓', '凉山彝族自治州', '2024-07-08', '2024-07-11'); insert into `t_estimated_arrival_date` values (18, '6', '湖熟正常仓', '凉山彝族自治州', '2024-07-09', '2024-07-12'); insert into `t_estimated_arrival_date` values (19, '6', '湖熟正常仓', '包头市', '2024-07-08', '2024-07-11'); insert into `t_estimated_arrival_date` values (20, '6', '湖熟正常仓', '包头市', '2024-07-09', '2024-07-12'); insert into `t_estimated_arrival_date` values (21, '6', '湖熟正常仓', '北京城区', '2024-07-08', '2024-07-10'); insert into `t_estimated_arrival_date` values (22, '6', '湖熟正常仓', '北京城区', '2024-07-09', '2024-07-11');
pom.xm
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-aop</artifactid>
</dependency>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-data-redis</artifactid>
</dependency>
<!--redis连接池-->
<dependency>
<groupid>org.apache.commons</groupid>
<artifactid>commons-pool2</artifactid>
</dependency>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-cache</artifactid>
</dependency>
<dependency>
<groupid>com.github.ben-manes.caffeine</groupid>
<artifactid>caffeine</artifactid>
<version>2.9.2</version>
</dependency>
<dependency>
<groupid>mysql</groupid>
<artifactid>mysql-connector-java</artifactid>
<version>8.0.28</version>
</dependency>
<dependency>
<groupid>com.baomidou</groupid>
<artifactid>mybatis-plus-boot-starter</artifactid>
<version>3.3.1</version>
</dependency>
application.yml
server:
port: 9001
spring:
application:
name: springboot-redis
datasource:
name: demo
url: jdbc:mysql://localhost:3306/test?userunicode=true&&characterencoding=utf8&allowmultiqueries=true&usessl=false
driver-class-name: com.mysql.cj.jdbc.driver
username:
password:
# mybatis相关配置
mybatis-plus:
mapper-locations: classpath:mapper/*.xml
configuration:
cache-enabled: true
use-generated-keys: true
default-executor-type: reuse
use-actual-param-name: true
# 打印日志
# log-impl: org.apache.ibatis.logging.stdout.stdoutimpl
redis:
host: 192.168.117.73
port: 6379
password: root
# redis:
# lettuce:
# cluster:
# refresh:
# adaptive: true
# period: 10s
# pool:
# max-idle: 50
# min-idle: 8
# max-active: 100
# max-wait: -1
# timeout: 100000
# cluster:
# nodes:
# - 192.168.117.73:6379
logging:
level:
com.itender.redis.mapper: debug
配置类
- redisconfig
/**
* @author yuanhewei
* @date 2024/5/31 16:18
* @description
*/
@configuration
public class redisconfig {
@bean
public redistemplate<string, object> redistemplate(redisconnectionfactory connectionfactory) {
redistemplate<string, object> redistemplate = new redistemplate<>();
redistemplate.setconnectionfactory(connectionfactory);
jackson2jsonredisserializer<object> serializer = new jackson2jsonredisserializer<>(object.class);
objectmapper mapper = new objectmapper();
mapper.setvisibility(propertyaccessor.all, jsonautodetect.visibility.any);
mapper.activatedefaulttyping(laissezfairesubtypevalidator.instance, objectmapper.defaulttyping.non_final, jsontypeinfo.as.property);
serializer.setobjectmapper(mapper);
// 如果不序列化在key value 使用redis客户端工具 直连redis服务器 查看数据时 前面会有一个 \xac\xed\x00\x05t\x00\x05 字符串
// stringredisserializer 来序列化和反序列化 string 类型 redis 的 key value
redistemplate.setkeyserializer(new stringredisserializer());
redistemplate.setvalueserializer(serializer);
// stringredisserializer 来序列化和反序列化 hash 类型 redis 的 key value
redistemplate.sethashkeyserializer(new stringredisserializer());
redistemplate.sethashvalueserializer(serializer);
redistemplate.afterpropertiesset();
return redistemplate;
}
}
- caffeineconfig
/**
* @author yuanhewei
* @date 2024/7/9 14:16
* @description
*/
@configuration
public class caffeineconfig {
/**
* caffeine 配置类
* initialcapacity:初始缓存空间大小
* maximumsize:缓存的最大数量,设置这个值避免内存溢出
* expireafterwrite:指定缓存的过期时间,是最后一次写操作的一个时间
* 容量的大小要根据自己的实际应用场景设置
*
* @return
*/
@bean
public cache<string, object> caffeinecache() {
return caffeine.newbuilder()
// 初始大小
.initialcapacity(128)
//最大数量
.maximumsize(1024)
//过期时间
.expireafterwrite(60, timeunit.seconds)
.build();
}
@bean
public cachemanager cachemanager(){
caffeinecachemanager cachemanager=new caffeinecachemanager();
cachemanager.setcaffeine(caffeine.newbuilder()
.initialcapacity(128)
.maximumsize(1024)
.expireafterwrite(60, timeunit.seconds));
return cachemanager;
}
}
mapper
这里采用了mybatis plus
/**
* @author yuanhewei
* @date 2024/7/9 18:11
* @description
*/
@mapper
public interface estimatedarrivaldatemapper extends basemapper<estimatedarrivaldateentity> {
}
service
/**
* @author yuanhewei
* @date 2024/7/9 14:25
* @description
*/
public interface doublecacheservice {
/**
* 查询一级送达时间-常规方式
*
* @param request
* @return
*/
estimatedarrivaldateentity getestimatedarrivaldatecommon(estimatedarrivaldateentity request);
/**
* 查询一级送达时间-注解方式
*
* @param request
* @return
*/
estimatedarrivaldateentity getestimatedarrivaldate(estimatedarrivaldateentity request);
}
实现类
/**
* @author yuanhewei
* @date 2024/7/9 14:26
* @description
*/
@slf4j
@service
public class doublecacheserviceimpl implements doublecacheservice {
@resource
private cache<string, object> caffeinecache;
@resource
private redistemplate<string, object> redistemplate;
@resource
private estimatedarrivaldatemapper estimatedarrivaldatemapper;
@override
public estimatedarrivaldateentity getestimatedarrivaldatecommon(estimatedarrivaldateentity request) {
string key = request.getdeliverydate() + redisconstants.colon + request.getwarehouseid() + redisconstants.colon + request.getcity();
log.info("cache key: {}", key);
object value = caffeinecache.getifpresent(key);
if (objects.nonnull(value)) {
log.info("get from caffeine");
return estimatedarrivaldateentity.builder().estimatedarrivaldate(value.tostring()).build();
}
value = redistemplate.opsforvalue().get(key);
if (objects.nonnull(value)) {
log.info("get from redis");
caffeinecache.put(key, value);
return estimatedarrivaldateentity.builder().estimatedarrivaldate(value.tostring()).build();
}
log.info("get from mysql");
datetime deliverydate = dateutil.parse(request.getdeliverydate(), "yyyy-mm-dd");
estimatedarrivaldateentity estimatedarrivaldateentity = estimatedarrivaldatemapper.selectone(new querywrapper<estimatedarrivaldateentity>()
.eq("delivery_date", deliverydate)
.eq("warehouse_id", request.getwarehouseid())
.eq("city", request.getcity())
);
redistemplate.opsforvalue().set(key, estimatedarrivaldateentity.getestimatedarrivaldate(), 120, timeunit.seconds);
caffeinecache.put(key, estimatedarrivaldateentity.getestimatedarrivaldate());
return estimatedarrivaldateentity.builder().estimatedarrivaldate(estimatedarrivaldateentity.getestimatedarrivaldate()).build();
}
@doublecache(cachename = "estimatedarrivaldate", key = {"#request.deliverydate", "#request.warehouseid", "#request.city"},
type = doublecache.cachetype.full)
@override
public estimatedarrivaldateentity getestimatedarrivaldate(estimatedarrivaldateentity request) {
datetime deliverydate = dateutil.parse(request.getdeliverydate(), "yyyy-mm-dd");
estimatedarrivaldateentity estimatedarrivaldateentity = estimatedarrivaldatemapper.selectone(new querywrapper<estimatedarrivaldateentity>()
.eq("delivery_date", deliverydate)
.eq("warehouse_id", request.getwarehouseid())
.eq("city", request.getcity())
);
return estimatedarrivaldateentity.builder().estimatedarrivaldate(estimatedarrivaldateentity.getestimatedarrivaldate()).build();
}
}
这里的代码本来是采用了常规的写法,没有采用自定义注解的方式,注解的方式是参考了后面那位大佬的文章,加以修改实现的。因为我的cachekey可能存在多个属性值的组合。
annotitions
/**
* @author yuanhewei
* @date 2024/7/9 14:51
* @description
*/
@target(elementtype.method)
@retention(retentionpolicy.runtime)
@documented
public @interface doublecache {
/**
* 缓存名称
*
* @return
*/
string cachename();
/**
* 缓存的key,支持springel表达式
*
* @return
*/
string[] key();
/**
* 过期时间,单位:秒
*
* @return
*/
long expiretime() default 120;
/**
* 缓存类型
*
* @return
*/
cachetype type() default cachetype.full;
enum cachetype {
/**
* 存取
*/
full,
/**
* 只存
*/
put,
/**
* 删除
*/
delete
}
}
aspect
/**
* @author yuanhewei
* @date 2024/7/9 14:51
* @description
*/
@slf4j
@component
@aspect
public class doublecacheaspect {
@resource
private cache<string, object> caffeinecache;
@resource
private redistemplate<string, object> redistemplate;
@pointcut("@annotation(com.itender.redis.annotation.doublecache)")
public void doublecachepointcut() {
}
@around("doublecachepointcut()")
public object doaround(proceedingjoinpoint point) throws throwable {
methodsignature signature = (methodsignature) point.getsignature();
method method = signature.getmethod();
// 拼接解析springel表达式的map
string[] paramnames = signature.getparameternames();
object[] args = point.getargs();
treemap<string, object> treemap = new treemap<>();
for (int i = 0; i < paramnames.length; i++) {
treemap.put(paramnames[i], args[i]);
}
doublecache annotation = method.getannotation(doublecache.class);
string elresult = doublecacheutil.arrayparse(lists.newarraylist(annotation.key()), treemap);
string realkey = annotation.cachename() + redisconstants.colon + elresult;
// 强制更新
if (annotation.type() == doublecache.cachetype.put) {
object object = point.proceed();
redistemplate.opsforvalue().set(realkey, object, annotation.expiretime(), timeunit.seconds);
caffeinecache.put(realkey, object);
return object;
}
// 删除
else if (annotation.type() == doublecache.cachetype.delete) {
redistemplate.delete(realkey);
caffeinecache.invalidate(realkey);
return point.proceed();
}
// 读写,查询caffeine
object caffeinecacheobj = caffeinecache.getifpresent(realkey);
if (objects.nonnull(caffeinecacheobj)) {
log.info("get data from caffeine");
return caffeinecacheobj;
}
// 查询redis
object rediscache = redistemplate.opsforvalue().get(realkey);
if (objects.nonnull(rediscache)) {
log.info("get data from redis");
caffeinecache.put(realkey, rediscache);
return rediscache;
}
log.info("get data from database");
object object = point.proceed();
if (objects.nonnull(object)) {
// 写入redis
log.info("get data from database write to cache: {}", object);
redistemplate.opsforvalue().set(realkey, object, annotation.expiretime(), timeunit.seconds);
// 写入caffeine
caffeinecache.put(realkey, object);
}
return object;
}
}
因为注解上的配置要支持spring的el表达式。
public static string parse(string elstring, sortedmap<string, object> map) {
elstring = string.format("#{%s}", elstring);
// 创建表达式解析器
expressionparser parser = new spelexpressionparser();
// 通过evaluationcontext.setvariable可以在上下文中设定变量。
evaluationcontext context = new standardevaluationcontext();
map.foreach(context::setvariable);
// 解析表达式
expression expression = parser.parseexpression(elstring, new templateparsercontext());
// 使用expression.getvalue()获取表达式的值,这里传入了evaluation上下文
return expression.getvalue(context, string.class);
}
public static string arrayparse(list<string> elstrings, sortedmap<string, object> map) {
list<string> result = lists.newarraylist();
elstrings.foreach(elstring -> {
elstring = string.format("#{%s}", elstring);
// 创建表达式解析器
expressionparser parser = new spelexpressionparser();
// 通过evaluationcontext.setvariable可以在上下文中设定变量。
evaluationcontext context = new standardevaluationcontext();
map.foreach(context::setvariable);
// 解析表达式
expression expression = parser.parseexpression(elstring, new templateparsercontext());
// 使用expression.getvalue()获取表达式的值,这里传入了evaluation上下文
result.add(expression.getvalue(context, string.class));
});
return string.join(redisconstants.colon, result);
}
controller
/**
* @author yuanhewei
* @date 2024/7/9 14:14
* @description
*/
@restcontroller
@requestmapping("/doublecache")
public class doublecachecontroller {
@resource
private doublecacheservice doublecacheservice;
@postmapping("/common")
public estimatedarrivaldateentity getestimatedarrivaldatecommon(@requestbody estimatedarrivaldateentity estimatedarrivaldate) {
return doublecacheservice.getestimatedarrivaldatecommon(estimatedarrivaldate);
}
@postmapping("/annotation")
public estimatedarrivaldateentity getestimatedarrivaldate(@requestbody estimatedarrivaldateentity estimatedarrivaldate) {
return doublecacheservice.getestimatedarrivaldate(estimatedarrivaldate);
}
}
代码中演示了redis + caffeine实现两级缓存的方式,一种是传统常规的方式,另一种是基于注解的方式实现的。具体实现可以根据自己项目中的实际场景。
最后的测试结果也是两种方式都可以实现查询先走一级缓存;一级缓存不存在查询二级缓存,然后写入一级缓存;二级缓存不存在,查询mysql然后写入二级缓存,再写入一级缓存的目的。测试结果就不贴出来了
总结
本文介绍redis+caffeine实现两级缓存的方式。一种是常规的方式,一种的基于注解的方式。具体的实现可根据自己项目中的业务场景。
至于为什么要用redis+caffeine的方式,文章也提到了,目前我们redis集群压力还算挺大的,而且接口对rt的要求也是比较高的。有一点好的就是我们的数据是每天全量推一边,总量也不大,实时性要求也不强。所以就很适合本地缓存的方式。
使用本地缓存也要注意设置容量的大小和过期时间,否则容易出现内存溢出。
其实现实中很多的场景直接使用redis就可以搞定的,没必要硬要使用caffeine。这里也只是简单的介绍了最简单基础的实现方式。对于其他一些复杂的场景还要根据自己具体的业务进行设计。我自己也是边学边用。
到此这篇关于redis+caffeine 实现两级缓存的项目实践的文章就介绍到这了,更多相关redis+caffeine 两级缓存内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论