自打2022年英特尔正式发布旗下arc系列独立显卡,在独显领域的讨论终于从amd、nvidia两家之争扩展到了第三家。对于英特尔而言,首次试水的arc a系列在发布的2年内像升级打怪一般,攻克了一个又一个需要大量行业经验积累才能解决的问题,例如对dx9、dx11游戏的支持程度,再例如光线追踪单元利用的效率,以及驱动稳定程度等等。
从现在这个时间点来看,intel arc a系列虽然说不上一鸣惊人,但成长的速度令人印象深刻,光是过去一段时间接连50多次的驱动更新,以及对120款以上游戏发布当日的day-0支持,都让intel arc的性价比愈发凸显。

但只有驱动层面更新是远远不够的,特别是在ai视觉运算和光线追踪效果逐渐具备普适性,a、n两家新显卡蓄势待发,是时候重新定义性价比概念了。因此在距离ces 2025不到一个月的时间点上,英特尔正式发布并开卖锐炫arc b580系列,以battlemage战斗法师为名,点燃gpu迭代的第一把火。

如果你是intel arc a750用户,或者计划在近期构建一套高性价比的台式机pc,眼前的intel arc b850显然是值得期待的,它定位2000元档的价位段,并带来全新的xe2架构和大量的硬件升级,配合软件和驱动积极更新的节奏,都暗示着intel arc b850很有尝试的必要。
那么intel arc b850的战斗力究竟如何?我们的首发评测就此奉上。

战斗法师bmg-g21
在月初的媒体沟通会上,英特尔表明intel arc b系列先发的两款型号为intel arc b580和arc b570两款,其中intel arc b580先发,arc b570则会安排到2025年1月份。

两款gpu的核心均来自型号为mg-g21的soc,基于xe2架构打造,采用台积电n5制程,晶体管数量达到196亿个,die size为272mm2。因此intel arc b580和arc b570的主要区别在于xe core数量和显存数量的区别。

xe2架构同样已经应用到了前段时间已经发布的lunar lake cpu的核显中,全新的xe2架构加入了xve矢量引擎、更高效的xmx引擎等,特别是xmx矩阵单元在底层硬件设计上的升级,为后续的xess 2分辨率超采样技术得以实现,同时xmx矩阵单元带来的优势也是早期xe-lpg利用的dp4a指令集无法达到的效率。
xe2中的xe核心包含8个512bit矢量引擎,相比上一代xe的16个矢量引擎减少了一半,另一半用来放前面提到的2048bit xmx矩阵引擎来实现更好的运算支持。xmx矩阵引擎包含int2、int4、int8以及fp16、bf16在内精度计算,并对fp64提供支持,从而实现对更丰富的推理模型的兼容。

由于xmx引擎支持int8 4096 ops/clock和fp16 2048 ops/clock算力,远高于xve矢量引擎,因此在重负荷ai加速中,xe2可以承担更多的ai加速工作。
继续向下延伸就是构成xe核心部分之一的渲染切片(render slice)。新的渲染切片引入了对于excute indirect的支持,原来3d任务需要cpu把指令给到gpu,然后由gpu去运算执行,而在excute indirect功能支持下,部分命令可以直接在gpu本地执行,不需要cpu一条条告诉gpu做什么,而是gpu本身就具备draw、dispatch的能力,这些命令可以直接在gpu里直接完成。此外,几何单元改进达成顶点获取(vertex fetch)吞吐提升3倍,mesh shading性能提升3倍。
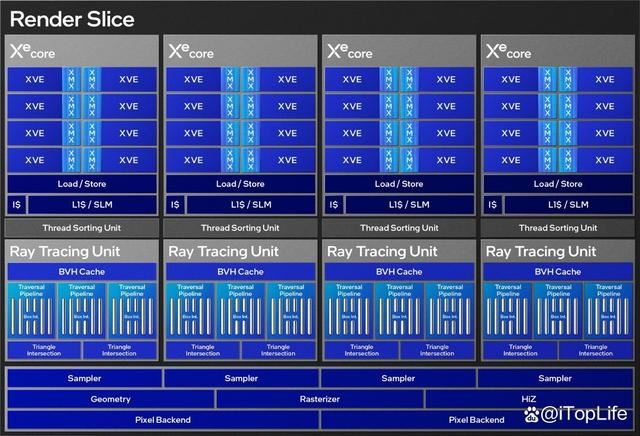
xe2缓存部分的压缩率和吞吐量也有了明显提升,包括提升了l1 cache的利用率,sampling吞吐提升2倍,pixel color cache提升1.33倍。因此尽管在xe核心数量上arc b580比arc a750要少,但实际上由于效率的提升,让性能显著增加。
英特尔用《堡垒之夜》举例,得益于在已经上对间接执行(execute indirect)支持,并通过simd16减少光照通道执行时间,以及l1缓存无序访问视图(unordered access views,uavs)写入,同样场景下xe2渲染体积雾的时间减少33%。
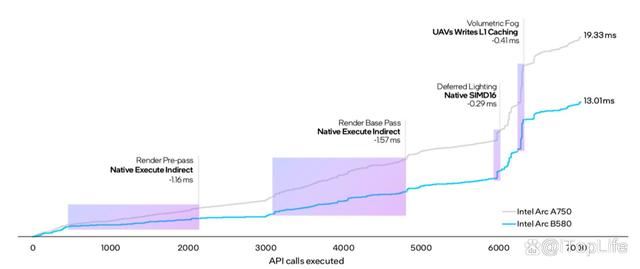
顺带一提,xe2在simd16的基础上,增加了对simd32的支持,即一次处理32个数据元素。虽然这个设计是基于simd16上获得而不是原生,但可以确保intel arc b580运行更大规模的矩阵乘法,或者处理图形渲染中更复杂的计算效率。
xe rtu光线追踪单元也进行了拓宽,提供三条遍历通道,18 x box intersections和2 x triangle intersections计算,能够更快速地进行盒子和三角形之间的交叉检测。其中box intersections是指单元在光线与盒子或者说包围体积相交时所能处理的数量,triangle intersection指代光线与三角形相交时所能处理的数量。

在媒体引擎方面,intel arc b系列使用了双mfx引擎设计,看可以提供8k 10bit hdr 120fps编码工作负载,并且从硬件提供包括vp9、av1等硬件支持。同时xe媒体引擎还提供hevc 4:2:2 10bit编解码,是目前windows平台唯一硬件原生支持此格式的gpu。

由于intel arc b580已经是完整的bmg-g21,因此包含了5个渲染切片,20个xe-core,160个xe矢量引擎,160个xmx矩阵引擎,20个光线追踪单元,20个纹理采样器,并配备了18mb l2缓存以减少内存访问延迟和带宽瓶颈问题。此外,intel arc b580的核心最高频率可以达到2850mhz,配备12gb 192-bit gddr6显存,显存带宽456gb/s。

发表评论