前言
- 本文使用 spock(可集成spring boot项目) 编写测试用例,基于 groovy (jvm语言)
- 用例的目标为 mybatis 的查询api
- 用例数据量10w 行
- 用例仓库地址
1. 配置用例堆内存大小
-xmx100m,配置堆内存大小,让溢出情况更快出现
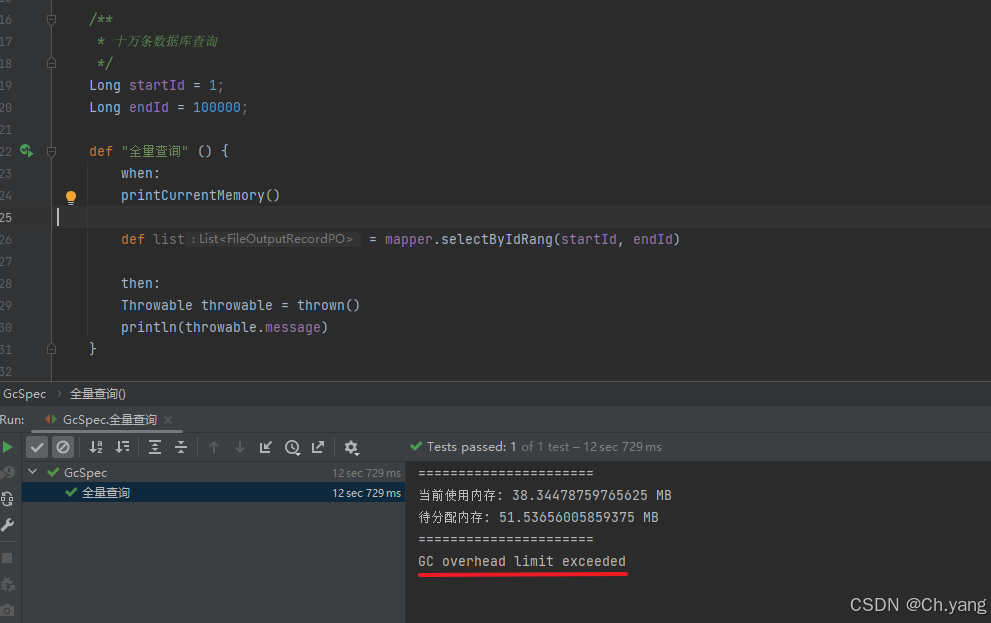
2. 单次全量查造成 gc overhead limit exceeded
“gc overhead limit exceeded”是java虚拟机(jvm)在运行时抛出的一个错误消息,它指示jvm花费了太多时间进行垃圾回收(gc),但回收的堆内存却很少
以下用例的意思是,期待抛出异常,并打印异常信息。
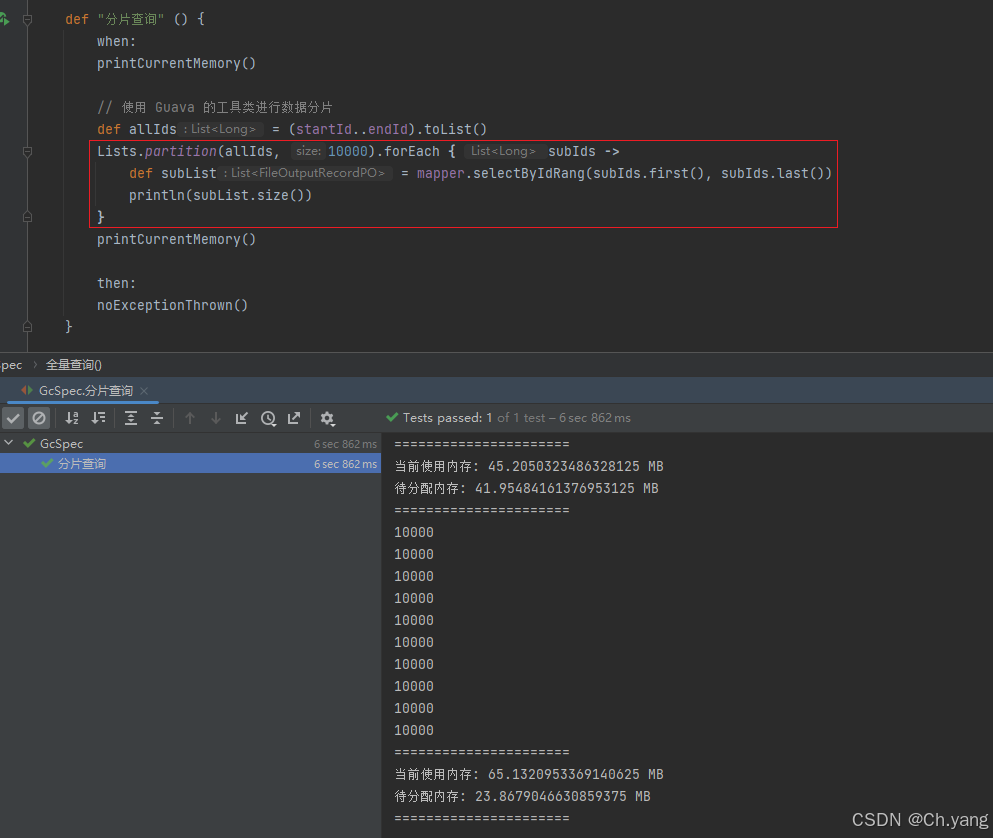
3. 分片查询减轻gc压力
使用 guava 的工具分片查询同一批数据,异常消失。
4. spock 语法积累
4.1 测试用例的钩子函数
- spock 相关的钩子函数造数
- setup 方法——用例执行前调用cleanup 方法——用例执行后调用
@springboottest(classes = ketchupapplication.class)
class gcspec extends specification {
@resource
fileoutputrecordmapper mapper
/**
* 十万条数据库查询
*/
long startid = 1;
long endid = 100000;
/**
* 生成十万条数据,测试用例执行完后删除
*/
def setup() {
def allids = (startid..endid).tolist()
lists.partition(allids, 1000).foreach { subids ->
def sub = subids.collect(it -> createpo(it))
mapper.batchinsertwithid(sub);
}
}
def cleanup() {
mapper.deletebyidrang(startid, endid)
}
}4.2 given when then expect 的用法
以下是已知的三种用例写法
def "分片查询" () {
given:
when:
then:
} def "分片查询" () {
when:
then:
} def "分片查询" () {
given:
expect:
}5. groovy 语法积累
5.1 rang 数据结构 rang 声明
def rang = (startid .. endid)
普通的 list 声明 ()
def list = [1,2,3]
rang 转 list
// 生成一个list,内部的元素是从1 到 100000的数值类型 def allids = (1 .. 100000).tolist()
5.2 list.collect
// 以下的 collect 写法比java简洁很多 def sub = subids.collect(it -> createpo(it)) // 等价于 java 的写法 list<fileoutputrecordpo> polist = subids.stream().map(it -> createpo(it)).collect(collectors.tolist())
6. guava 工具类积累
lists.partition(allids, 1000).foreach...
本文的集合分片工具来自:
<dependency>
<groupid>com.google.guava</groupid>
<artifactid>guava</artifactid>
<version>30.1-jre</version>
</dependency>后记
大数据量的查询时,避免用一个大list<>装大量数据,必要时将数据分片,减轻gc压力。
大数据的不同任务,尽量串行化执行,避免出现gc毛刺。
到此这篇关于java中验证 mybatis 数据分片可以减轻gc压力的文章就介绍到这了,更多相关 mybatis 数据分片减轻gc压力内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论