在数据分析的世界里,数据是核心,而如何高效地生成和处理数据则成为每位数据分析师必备的技能之一。今天,我们要探讨一个有趣的话题——“造数”。
但这里的“造数”并非意味着编造数据,而是指在确保数据安全的前提下,模拟生成一些用于测试的数据。在众多工具中,faker库以其强大的功能和易用性脱颖而出,成为数据分析师们手中的得力助手。
接下来,让我们一起走进faker库的世界,看看它是如何帮助数据分析师们轻松“造数”的?
1.常规数据模拟
常规数据模拟,比如我们生成一组范围在100到1000的31个数字,就可以使用一行代码np.random.randint(100,1000,31),如下使用随机数字生成sale随日期变化的折线图。
import pandas as pd
import numpy as np
import datetime
df=pd.dataframe(data=np.random.randint(100,1000,31),
index=pd.date_range(datetime.datetime(2022,12,1),periods=31),
columns=['sale']).plot(figsize=(9,6))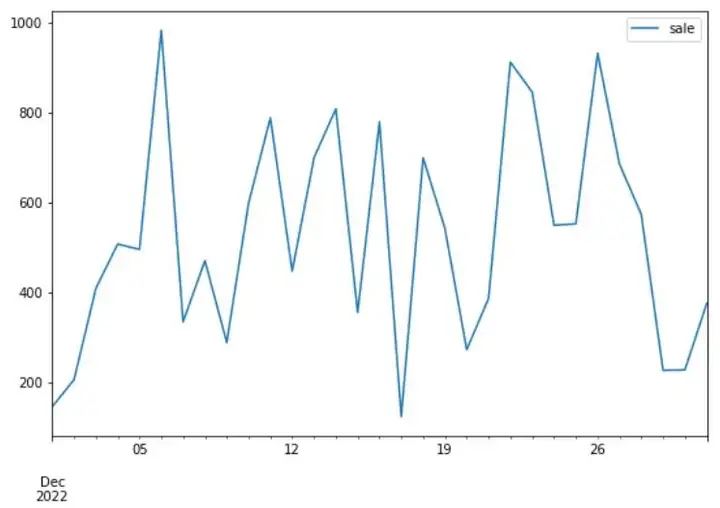
2.faker模拟数据
使用faker模拟数据需要提前下载faker库,在命令行使用pip install faker命令即可下载,当出现successfully installed的字样时表明库已经安装完成。
!pip install faker -i https://pypi.tuna.tsinghua.edu.cn/simple
导入faker库可以用来模拟生成数据,其中,locale="zh_cn"用来显示中文,如下生成包含姓名、手机号、身份证号、出生年月日、邮箱、地址、公司、职位这几个字段的数据。
#多行显示运行结果 from ipython.core.interactiveshell import interactiveshell interactiveshell.ast_node_interactivity = "all" from faker import faker faker=faker(locale="zh_cn") #模拟生成数据 faker.name() faker.phone_number() faker.ssn() faker.ssn()[6:14] faker.email() faker.address() faker.company() faker.job()

除了上面的字段,faker库还可以生成如下几类常用的数据,地址类、人物类、公司类、信用卡类、时间日期类、文件类、互联网类、工作类、乱数假文类、电话号码类、身份证号类。
#address 地址 faker.country() # 国家 faker.city() # 城市 faker.city_suffix() # 城市的后缀,中文是:市或县 faker.address() # 地址 faker.street_address() # 街道 faker.street_name() # 街道名 faker.postcode() # 邮编 faker.latitude() # 维度 faker.longitude() # 经度

#person 人物 faker.name() # 姓名 faker.last_name() # 姓 faker.first_name() # 名 faker.name_male() # 男性姓名 faker.last_name_male() # 男性姓 faker.first_name_male() # 男性名 faker.name_female() # 女性姓名

#company 公司 faker.company() # 公司名 faker.company_suffix() # 公司名后缀

#credit_card 银行信用卡 faker.credit_card_number(card_type=none) # 卡号
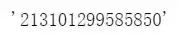
#date_time 时间日期 faker.date_time(tzinfo=none) # 随机日期时间 faker.date_time_this_month(before_now=true, after_now=false, tzinfo=none) # 本月的某个日期 faker.date_time_this_year(before_now=true, after_now=false, tzinfo=none) # 本年的某个日期 faker.date_time_this_decade(before_now=true, after_now=false, tzinfo=none) # 本年代内的一个日期 faker.date_time_this_century(before_now=true, after_now=false, tzinfo=none) # 本世纪一个日期 faker.date_time_between(start_date="-30y", end_date="now", tzinfo=none) # 两个时间间的一个随机时间 faker.time(pattern="%h:%m:%s") # 时间(可自定义格式) faker.date(pattern="%y-%m-%d") # 随机日期(可自定义格式)

#file 文件 faker.file_name(category="image", extension="png") # 文件名(指定文件类型和后缀名) faker.file_name() # 随机生成各类型文件 faker.file_extension(category=none) # 文件后缀

#internet 互联网 faker.safe_email() # 安全邮箱 faker.free_email() # 免费邮箱 faker.company_email() # 公司邮箱 faker.email() # 邮箱

#job 工作 faker.job()#工作职位
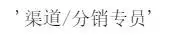
#lorem 乱数假文 faker.text(max_nb_chars=200) # 随机生成一篇文章 faker.word() # 随机单词 faker.words(nb=10) # 随机生成几个字 faker.sentence(nb_words=6, variable_nb_words=true) # 随机生成一个句子 faker.sentences(nb=3) # 随机生成几个句子 faker.paragraph(nb_sentences=3, variable_nb_sentences=true) # 随机生成一段文字(字符串) faker.paragraphs(nb=3) # 随机生成成几段文字(列表)

#phone_number 电话号码 faker.phone_number() # 手机号码 faker.phonenumber_prefix() # 运营商号段,手机号码前三位
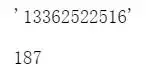
#ssn 身份证 faker.ssn() # 随机生成身份证号(18位)
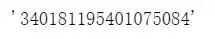
3.模拟数据并导出excel
使用faker库模拟一组数据,并导出到excel中,包含姓名、手机号、身份证号、出生日期、邮箱、详细地址等字段,先生成一个带有表头的空sheet表,使用faker库生成对应字段,并用append命令逐一添加至sheet表中,最后进行保存导出。
from faker import faker
from openpyxl import workbook
wb=workbook()#生成workbook 和工作表
sheet=wb.active
title_list=["姓名","手机号","身份证号","出生日期","邮箱","详细地址","公司名称","从事行业"]#设置excel的表头
sheet.append(title_list)
faker=faker(locale="zh_cn")#模拟生成数据
for i in range(100):
sheet.append([faker.name(),#生成姓名
faker.phone_number(),#生成手机号
faker.ssn(), #生成身份证号
faker.ssn()[6:14],#出生日期
faker.email(), #生成邮箱
faker.address(), #生成详细地址
faker.company(), #生成所在公司名称
faker.job(), #生成从事行业
])
wb.save(r'd:\系统桌面(勿删)\desktop\模拟数据.xlsx')
4.添加数值型数据
如果要生成一些可计算的随机数据,可以使用pandas、numpy这两个库,以上面的数据为例,添加可计算数据。
import pandas as pd import numpy as np # 读取excel文件 df = pd.read_excel(r'd:\系统桌面(勿删)\desktop\模拟数据.xlsx') df.head() # 设置随机数种子以确保结果可重复 np.random.seed(0) # 随机生成新字段的数据 df['销售数量'] = np.random.randint(1, 100, size=len(df)) df['销售单价'] = np.random.uniform(5, 50, size=len(df)).round(2) df['销售收入'] = df['销售数量'] * df['销售单价'] df['销售成本'] = np.random.uniform(5, 50, size=len(df)).round(2) df['销售利润'] = df['销售收入'] - df['销售成本'] df['利润率'] = (df['销售利润'] / df['销售收入']).round(4) df.to_excel(r'd:\系统桌面(勿删)\desktop\faker模拟数据.xlsx')
通过本节的分享,我们不难发现,faker库在数据分析中扮演着举足轻重的角色。它不仅能够模拟生成各种类型的数据,还能帮助我们快速构建测试数据集,从而提高数据分析的效率和准确性。更重要的是,faker库的使用也非常简单,只需几行代码,就能生成我们所需的数据。
以上就是python批量生成excel案例数据集的方法详解的详细内容,更多关于python生成excel数据集的资料请关注代码网其它相关文章!



发表评论