spring cloud 是一套基于 spring boot 的框架集合,用于构建分布式微服务架构。它提供了一系列工具和库,帮助开发者更轻松地管理分布式系统中的关键问题,比如服务注册与发现、负载均衡、分布式配置管理、熔断与降级、链路追踪等。
下图展示了微服务架构中每个主要功能模块的常用解决方案。

一、相关功能的介绍
1. 服务注册与发现
服务注册:服务注册与发现用于让各个服务在启动时自动注册到一个中央注册中心(如 nacos、eureka),并且能让其他服务通过注册中心找到并调用它们的地址。
发现:每个服务启动后会将自身的地址和端口信息注册到注册中心;其他服务要调用它时,通过注册中心获取服务实例的地址,而不需要固定的地址。
2. 服务调用和负载均衡
服务调用:服务之间的通信方式,可以通过 http(如 restful api)或 rpc(远程过程调用)进行服务之间的请求。
负载均衡:在微服务架构中,通常会有多个相同的服务实例分布在不同的服务器上。负载均衡用于在多个实例间分配请求,常见的策略有轮询、随机、最小连接数等,从而提升系统的处理能力和容错性。
3. 分布式事务
分布式事务用于保证多个服务在处理同一个业务操作时的一致性。例如,用户下单时,需要支付服务和库存服务同时完成,如果某一方失败,整个操作需要回滚。
4. 服务熔断和降级
服务熔断:用于防止一个服务的故障传导到其他服务。如果某个服务在短时间内出现大量的错误或响应缓慢,熔断机制会自动切断对该服务的调用,避免对系统造成更大影响。
服务降级:在服务出现问题时,提供降级策略,比如返回默认值或简化响应内容,使系统能够在部分服务不可用的情况下继续运行。
5. 服务链路追踪
服务链路追踪用于跟踪分布式系统中一次请求的完整路径,分析其跨多个服务的执行情况,方便发现延迟或错误。
6. 服务网关
服务网关作为服务的统一入口,处理所有外部请求,提供认证授权、负载均衡、路由分发、监控等功能。它还能对请求进行限流、熔断、降级等保护。
7. 分布式配置管理
分布式配置管理用于集中管理各服务的配置文件,支持动态更新,不需要重启服务。 可以在配置更新后自动推送至各服务节点,使它们能实时更新配置信息,提升了系统的灵活性和一致性。
二、前置内容和准备工作
1、 不同服务之间的调用
下面两个了解其中一个就行
resttemplate
resttemplate 是 spring 提供的一个同步 http 客户端,用于与 restful web 服务进行交互。它支持多种 http 方法,包括 get、post、put、delete 等,简化了调用 rest api 的过程。
在微服务架构中,服务之间需要进行通信,resttemplate 通过简单的 http 调用实现这一点。通过服务注册和发现机制,可以动态获取服务的地址和端口。
配置resttemplate
确保 pom.xml 文件中包含了 spring web 相关的依赖:
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-web</artifactid>
</dependency>创建 resttemplate bean
在 spring boot 应用程序中,通常在配置类中创建一个 resttemplate 的 bean:
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import org.springframework.web.client.resttemplate;
@configuration
public class appconfig {
@bean
public resttemplate resttemplate() {
return new resttemplate();
}
}resttemplate常用方法
get 请求
resttemplate.getforobject(url, string.class); // getforobject(string url, class<t> responsetype):发起 get 请求,并返回响应体。
post 请求
resttemplate.postforobject(url, request, myresponseobject.class); // postforobject(string url, object request, class<t> responsetype):发起 post 请求,将请求体发送给指定 url,并返回响应体。
put 请求
resttemplate.put(url, request); // put(string url, object request):发起 put 请求,将请求体发送到指定 url。
delete 请求
resttemplate.delete(url); // delete(string url):发起 delete 请求。
openfeign
feign 是一个声明式的 web 服务客户端,它简化了与 http 服务交互的方式。使得开发人员能够通过简单的注解方式调用 restful web 服务,而不需要手动编写繁琐的 http 请求代码。(resttemplate和这个了解一种即可)
引入依赖
如果在使用 spring cloud,可以在你的 pom.xml 中加入 feign 相关的依赖:
<dependency>
<groupid>org.springframework.cloud</groupid>
<artifactid>spring-cloud-starter-openfeign</artifactid>
</dependency>启用 feign:
在 spring boot 应用的主类或者配置类中添加 @enablefeignclients 注解,启用 feign 客户端:
import org.springframework.cloud.openfeign.enablefeignclients;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
@springbootapplication
@enablefeignclients // 启用 feign 客户端
public class myapplication {
public static void main(string[] args) {
springapplication.run(myapplication.class, args);
}
}定义 feign 接口:
feign 使用接口定义 http 请求。通过注解指定请求的类型和路径:
import org.springframework.cloud.openfeign.feignclient;
import org.springframework.web.bind.annotation.getmapping;
import org.springframework.web.bind.annotation.requestparam;
@feignclient(name = "account-service") // 指定服务名称, 这里是指注册到naocs的服务名
public interface accountclient {
@getmapping("/account/balance")
string getbalance(@requestparam("userid") string userid);
}在上面的例子中:
@feignclient(name = "account-service")表示 feign 客户端将向名为account-service的服务发起请求。@getmapping("/account/balance")表示该方法会向/account/balance路径发送 get 请求,并返回响应。
调用 feign 客户端:
在其他服务中调用 feign 客户端接口,就像调用本地方法一样:
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.web.bind.annotation.requestmapping;
import org.springframework.web.bind.annotation.restcontroller;
@restcontroller
public class ordercontroller {
@autowired
private accountclient accountclient;
@requestmapping("/order/test")
public string createorder(string userid) {
// 调用 feign 客户端方法
string balance = accountclient.getbalance(userid);
return "account balance: " + balance;
}
}2、 准备工作(引入spring cloud依赖)
1. dependencymanagement
dependencymanagement 是 maven 构建工具中的一个元素,用于定义项目中依赖的管理方式。它允许我们在父 pom 文件或依赖管理部分中集中声明依赖的版本号和作用范围,所有子模块(子项目)可以自动继承这些声明,而不需要在每个子模块的 pom.xml 中重复定义。
统一依赖版本管理:dependencymanagement 能够帮助你统一管理多个模块中某个依赖的版本。例如,你可以在一个中央位置(通常是父 pom 文件)声明 spring boot 的版本号,这样所有子项目都会使用这个版本,而不需要每个项目中都定义。
简化子项目中的依赖声明:
子项目无需在每个 pom.xml 文件中声明依赖的版本号,只需要定义依赖的 groupid 和 artifactid,版本号将从 dependencymanagement 中继承。
根项目 pom 文件
<packaging>pom</packaging>
<dependencymanagement>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-dependencies -->
<dependency>
<groupid>org.springframework.cloud</groupid>
<artifactid>spring-cloud-dependencies</artifactid>
<version>2023.0.3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba.cloud/spring-cloud-alibaba-dependencies -->
<dependency>
<groupid>com.alibaba.cloud</groupid>
<artifactid>spring-cloud-alibaba-dependencies</artifactid>
<version>2023.0.1.3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencymanagement>子项目 pom 文件
<parent>
<groupid>com.cloud</groupid>
<artifactid>learncloudalibaba</artifactid>
<version>0.0.1-snapshot</version>
<relativepath>../pom.xml</relativepath>
</parent>
<!-- 下面这个是我根项目的pom文件的内容, 要确保上面子项目中 parent 中的 groupid artifactid version 跟下面 根项目的一致-->
<!-- <groupid>com.cloud</groupid>-->
<!-- <artifactid>learncloudalibaba</artifactid>-->
<!-- <version>0.0.1-snapshot</version>-->2. 引入依赖 spring cloud
spring cloud dependencies

2. 引入依赖 spring cloud alibaba
spring-cloud-alibaba-dependencies

3. 版本兼容性问题
参考文章 地址

这里我引入的是 springcloud 2023 , springcloudalibaba 2023, springboot 3.2, jdk 17
下面讲解一下每个主要功能模块的部署和配置
三、服务注册与发现 nacos
1. 准备工作
下载 nacos 本地服务 (地址)

添加依赖到子模块
在需要被nacos注册的模块中加入下面配置,启动项目即可在 localhost:8848/nacos 中查看到已经被注册到中央注册中心
<!-- nacos 服务注册和发现 -->
<dependency>
<groupid>com.alibaba.cloud</groupid>
<artifactid>spring-cloud-starter-alibaba-nacos-discovery</artifactid>
</dependency>简单配置
spring.cloud.nacos.discovery.server-addr=localhost:8848
在启动类上加上@enablediscoveryclient注解@enablediscoveryclient 是一个注解,用于启用服务注册与发现功能,通常在使用 spring cloud 和 nacos 的服务中添加。它告诉 spring boot 应用要注册到服务注册中心,以便其他服务能够发现它。
2. 以单例启动
解压进入nacos的 bin目录,以单例模式启动
.\startup.cmd -m standalone # localhost:8848/nacos 进行访问, 默认账号密码都是 nacos
3. 常见配置
spring.cloud.nacos.discovery.namespace=命名空间id # 指定命令空间, 不同空间下的实例不可互相访问 spring.cloud.nacos.discovery.group=default_group # 默认是default_group,指定group,不同group下的实例不可互相访问 spring.cloud.nacos.discovery.cluster-name=beijing # 指定当前实例是哪个集群,一般按照地区划分,讲请求发送距离近的实例 spring.cloud.loadbalancer.nacos.enabled=true # 开启 优先向跟当前发送请求的实例 在同一集群的实例发送请求 spring.cloud.nacos.discovery.weight=1 # 当前实例的权值,权值在1-100,默认是1,权值越大越容易接收请求,一般给配置高的服务器权值高一些
4. nacos 集群架构
对于 nacos 集群,主要的作用是 实现高可用和数据一致性,保证服务注册和配置管理的可靠性。
集群架构
nacos 集群通常包含多个节点,部署在不同的机器或虚拟机上,以提供服务注册、配置管理的冗余和高可用性。当一个节点发生故障时,其他节点可以继续提供服务,从而保证系统的稳定运行。
数据一致性(raft 协议)
nacos 集群内部使用 raft 协议 来实现服务数据的强一致性。这种一致性保证了同一服务的多个实例在集群中都能被正确地注册和发现。(在集群中的任意以nacos中注册,即可被整个集群的nacos访问)
- leader 选举:在 nacos 集群中,一个节点会被选举为 leader,其它节点作为 follower。leader 负责处理写请求并同步数据到 follower 节点。
- 数据同步:当服务实例的注册、注销或配置变更等写请求发生时,leader 会将数据同步到所有 follower,确保数据在集群中的一致性。
高可用性和故障恢复
- 当 leader 节点故障时,集群中的其他节点会重新选举一个新的 leader,继续处理写请求和同步数据。
- follower 节点接收 leader 的数据更新请求并定期与 leader 进行心跳检测,以保证集群稳定运行。
可以通过nginx反向代理,实现只暴漏一个nacos服务地址,nginx内容实现负载均衡
也可以通过loadbalancer或是在 application 中添加集群的所有地址实现简单的负载均衡
# 会选其中一个地址注册服务
spring.cloud.nacos.discovery.server-addr: 172.20.10.2:8870,172.20.10.2:8860,172.20.10.2:8848
5. 集群模式部署
配置数据库
nacos 集群需要一个共享的数据库来存储配置信息。可以使用 mysql 作为存储引擎。
在 mysql 中创建一个数据库:
create database nacos_config;
进入mysql,执行 nacos 提供的 sql 脚本:
mysql> use nacos_config; database changed mysql> source d:\kafka\nacos\conf\mysql-schema.sql
配置 nacos 集群
打开每个节点的 conf/application.properties 文件,进行以下配置:
server.port=8848 spring.datasource.platform=mysql spring.sql.init.platform=mysql ### count of db: db.num=1 db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_cofig?characterencoding=utf8&connecttimeout=1000&sockettimeout=3000&autoreconnect=true&useunicode=true&usessl=false&servertimezone=utc db.user.0=root db.password.0=password
打开每个节点的 conf/cluster.conf 文件,进行以下配置:
172.20.10.2:8848 # 前面是ip地址,内网的或是公网的 172.20.10.2:8860 172.20.10.2:8870
一些坑
这里我要在本地启动三个nacos,那就需要复制 nacos 文件夹,然后分别修改里面的 application.properties 和 cluster.conf 的配置文件,其中 server.port=8848 端口之间不要离太近。(离太近nacos 2.0 版本会出问题)这里弄成了 8848, 8860, 8870 端口

启动 nacos 实例
在每台服务器上启动 nacos 服务。执行以下命令:
.\startup.cmd -m cluster
注意:每个节点启动时,cluster.conf 文件中需要列出所有节点的 ip 和端口。
四、服务调用和负载均衡 loadbalancer
spring cloud loadbalancer 是 spring cloud 中的一个负载均衡模块,用于在服务调用时实现客户端负载均衡。
1. 基本概念
spring cloud loadbalancer 通过客户端负载均衡,在服务调用者和多个实例之间分配流量。它通过服务发现(比如使用 nacos)获取可用服务实例的列表,并根据不同的负载均衡策略(如轮询、随机等)选择一个实例进行请求分发。
2. 配置环境
在项目中使用 spring cloud loadbalancer,在每个需要使用客户端负载均衡功能的子模块中添加:
<dependency>
<groupid>org.springframework.cloud</groupid>
<artifactid>spring-cloud-starter-loadbalancer</artifactid>
</dependency>配置默认策略(轮询)
spring.cloud.loadbalancer.configurations=default
3. 负载均衡的使用方式
spring cloud loadbalancer 支持使用 resttemplate 、webclient 、openfeign 进行负载均衡。
使用 resttemplate
定义 resttemplate bean 并标注 @loadbalanced 注解:
@configuration
public class appconfig {
@bean
@loadbalanced // 启用 resttemplate 的负载均衡
public resttemplate resttemplate() {
return new resttemplate();
}
}发起请求
使用 @loadbalanced 的 resttemplate 时,可以直接通过服务名称调用服务,而不需要手动指定服务的 ip 地址和端口,避免了ip和端口写死, 只向一个实例发送请求的情况。
(我们同一个服务名称一般会有多个实例(分布式), 通过带有 @loadbalanced注解的 resttemplate 可以实现负载均衡, 让请求根据我们的配置分别发送到不同的实例)
@autowired
private resttemplate resttemplate;
public string callservice() {
// 使用服务名代替实际地址
return resttemplate.getforobject("http://module2/api/v1/data", string.class);
}4. 测试 负载均衡
假设我们有一个根模块, 根模块下面有三个模块 module1,module2,module3。module2 和 module3 我们在本地的不同端口各启动两个(模拟分布式)。当我们通过module1调用 module2 和 module3 的方法,观察请求的分布
将多个实例注册到nacos
这里演示的nacos用的单例模式,最终效果如下图

下面是如何启动让module2和module3分别启动两个实例

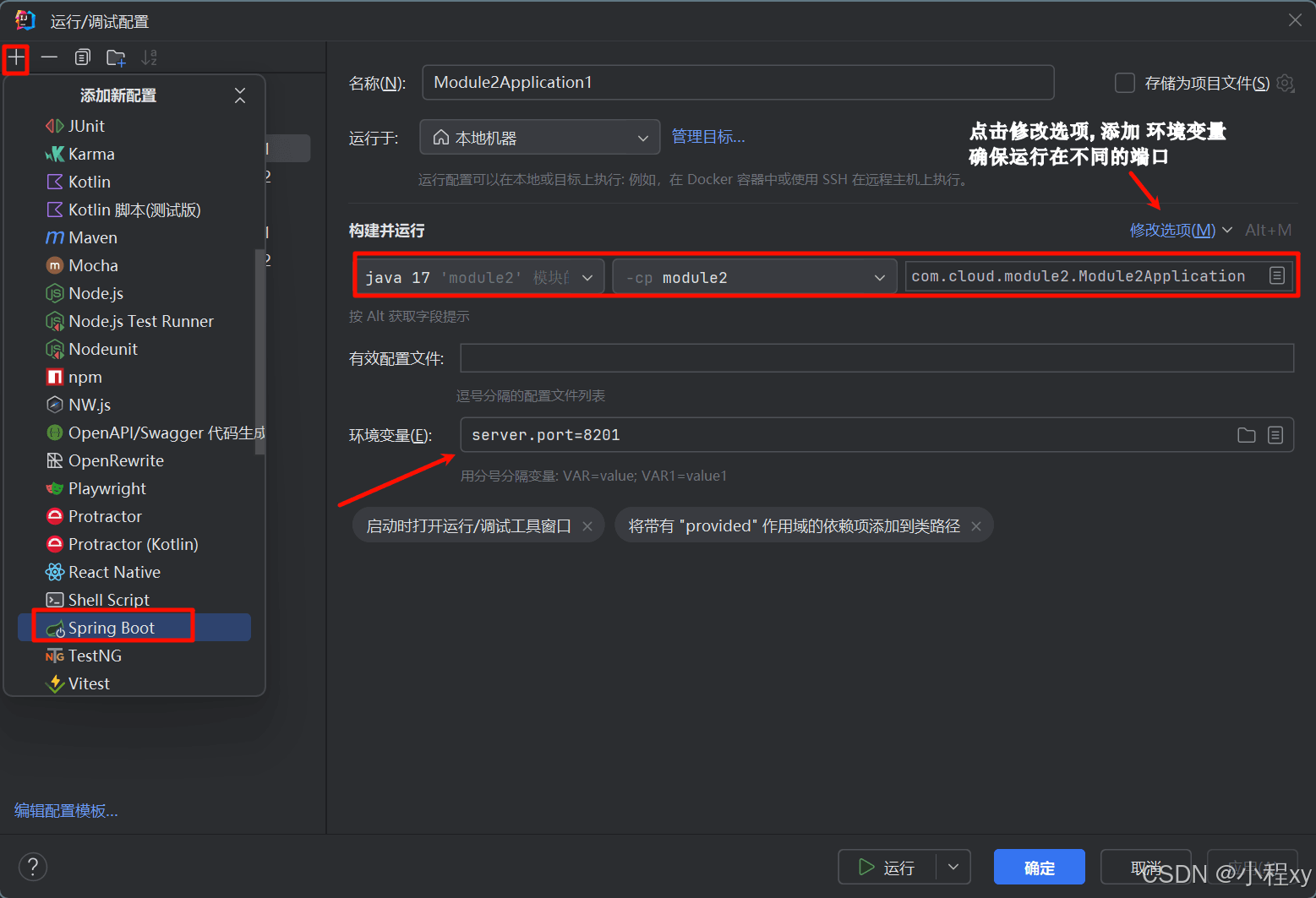
查看请求分布
三个module中的demo代码
module1 中,通过get方法访问 /test 时,会向 module2 和 module3 的实例发送请求。(spring cloud loadbalancer 会根据配置实现负载均衡)
@autowired
resttemplate resttemplate;
@getmapping("/test")
public string test() {
string module2 = resttemplate.getforobject("http://module2/api/test", string.class);
string module3 = resttemplate.getforobject("http://module3/api/test", string.class);
return module2 + "\n" + module3;
}module2 中
@getmapping("/api/test")
public string test() {
system.out.println("module2 test");
return "module2 test";
}module3 中
@getmapping("/api/test")
public string test() {
system.out.println("module3 test");
return "module3 test";
}当我们在浏览器访问 16 次 /test 的时候, resttemplate.getforobject 会向对应的module发送16次请求。观察module2的两个实例和module3的两个实例可以看到 分别接收到了 8 次请求(默认是轮询)。如下图




5. 使用不同的负载均衡器
上面的配置是所有服务都是用默认的负载均衡器,即轮询的负载均衡器。下面讲一下怎么让不同服务使用不同的负载均衡器
创建两个配置文件,把轮询负载均衡器和随机负载均衡器注册为bean
@configuration
public class defaultloadbalancerconfig {
@bean
reactorloadbalancer<serviceinstance> roundrobinloadbalancer(environment environment,
loadbalancerclientfactory loadbalancerclientfactory) {
string name = environment.getproperty(loadbalancerclientfactory.property_name); // 获取负载均衡器名称
return new roundrobinloadbalancer(loadbalancerclientfactory.getlazyprovider(name, serviceinstancelistsupplier.class), name);
}
}@configuration
public class randomloadbalancerconfig {
@bean
// 定义一个bean
reactorloadbalancer<serviceinstance> randomloadbalancer(environment environment, // 注入环境变量
loadbalancerclientfactory loadbalancerclientfactory) { // 注入负载均衡器客户端工厂
string name = environment.getproperty(loadbalancerclientfactory.property_name); // 获取负载均衡器的名称
// 创建并返回一个随机负载均衡器实例
return new randomloadbalancer(loadbalancerclientfactory.getlazyprovider(name, serviceinstancelistsupplier.class), name);
}
}创建resttempalte
// module2 使用默认,module3 使用随机
@configuration
@loadbalancerclients({
@loadbalancerclient(value = "module2", configuration = randomloadbalancerconfig.class),
@loadbalancerclient(value = "module3", configuration = defaultloadbalancerconfig.class)
})
public class appconfig {
@bean
@loadbalanced // 启用 resttemplate 的负载均衡
public resttemplate resttemplate() {
return new resttemplate();
}
}五、分布式事务 seata
seata 是一款开源的分布式事务解决方案,旨在解决微服务架构中跨服务的事务一致性问题。它提供了易于使用、性能高效的分布式事务管理功能,帮助开发者在分布式系统中保持数据一致性。
1. seata 的概要
seata 由阿里巴巴发起,最初的目的是为了解决微服务场景下的数据一致性问题,尤其是在分布式数据库事务中。seata 提供了全局事务、分支事务以及资源管理等功能。
- 全局事务:在分布式事务中,通常一个事务可能会涉及多个服务或数据库,seata 通过全局事务 id 来保证跨服务事务的原子性。
- 分支事务:每个服务或数据库在执行全局事务时会变成一个分支事务,seata 负责协调各个分支事务的提交与回滚。
- at模式:seata 提供了基于数据库的 at (automatic transaction) 模式,它通过对数据库的预存操作和恢复操作来实现事务的一致性。
- tcc模式:tcc (try, confirm, cancel) 是 seata 支持的另一种事务模式,适用于需要显式操作的场景。
- saga模式:saga 是另一种事务模型,适合于长事务和复杂业务场景。

- rm(resourcemanager):用于直接执行本地事务的提交和回滚。
- tm(transactionmanager):tm是分布式事务的核心管理者。比如现在我们需要在借阅服务中开启全局事务,来让其自身、图书服务、用户服务都参与进来,也就是说一般全局事务发起者就是tm。
- tc(transactionmanager)这个就是我们的seata服务器,用于全局控制,一个分布式事务的启动就是由tm向tc发起请求,tc再来与其他的rm进行协调操作
tm请求tc开启一个全局事务,tc会生成一个xid作为该全局事务的编号,xid会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起;rm请求tc将本地事务注册为全局事务的分支事务,通过全局事务的xid进行关联;tm请求tc告诉xid对应的全局事务是进行提交还是回滚;tc驱动rm将xid对应的自己的本地事务进行提交还是回滚;
下面以官网的案例来演示整个使用过程
2. 准备工作
下载seata服务(tc)
下载seata-service压缩包,解压进入/bin (下载地址), 执行 ./seata-server.bat
配置 seata:
在 conf 目录下,你会找到一个配置文件 application.yml。编辑该文件以配置 seata server 的各种参数,比如数据库连接、事务日志等。
server:
port: 7091
spring:
application:
name: seata-server
logging:
config: classpath:logback-spring.xml
file:
path: ${log.home:${user.home}/logs/seata}
extend:
logstash-appender:
destination: 127.0.0.1:4560
kafka-appender:
bootstrap-servers: 127.0.0.1:9092
topic: logback_to_logstash
console:
user:
username: seata
password: seata
seata:
config:
# support: nacos, consul, apollo, zk, etcd3
type: nacos
nacos:
server-addr: 127.0.0.1:8848
namespace:
group: seata_group
username: nacos
password: nacos
registry:
# support: nacos, eureka, redis, zk, consul, etcd3, sofa
type: nacos
nacos:
application: seata-server
server-addr: 127.0.0.1:8848
group: seata_group
namespace:
cluster: default
username: nacos
password: nacos
store:
# support: file 、 db 、 redis 、 raft
mode: db
db:
datasource: druid
db-type: mysql
driver-class-name: com.mysql.jdbc.driver
url: jdbc:mysql://127.0.0.1:3306/seata?rewritebatchedstatements=true
user: mysql
password: mysql
min-conn: 10
max-conn: 100
global-table: global_table
branch-table: branch_table
lock-table: lock_table
distributed-lock-table: distributed_lock
query-limit: 1000
max-wait: 5000
# server:
# service-port: 8091 #if not configured, the default is '${server.port} + 1000'
security:
secretkey: seatasecretkey0c382ef121d778043159209298fd40bf3850a017
tokenvalidityinmilliseconds: 1800000
ignore:
urls: /,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.jpeg,/**/*.ico,/api/v1/auth/login,/metadata/v1/**数据库配置
创建 seata 数据库,并访问 该地址,在seata数据库中执行里面所有的sql脚本
创建 seata_account, seata_order, seata_storage数据库,访问 该地址, 在上面三个数据库中都创建 undo_log 表,在对应的数据库中创建对应的 业务表。(地址中有sql脚本)
启动 seata server:
使用以下命令启动 seata server:
sh bin/seata-server.sh
最终效果如下

创建三个模块(account, order, storage),加入相关依赖(数据库驱动,mybatis…),然后按照下面加入 nacos 和 seata 依赖和配置
3. seata 与 spring boot 集成
3.1 添加 seata 依赖
<dependency>
<groupid>com.alibaba.cloud</groupid>
<artifactid>spring-cloud-starter-alibaba-seata</artifactid>
<exclusions>
<exclusion>
<groupid>io.seata</groupid>
<artifactid>seata-spring-boot-starter</artifactid>
</exclusion>
</exclusions>
</dependency>3.2 配置 seata
在 spring boot 项目的 application.yml 中配置 seata。
seata:
registry:
type: nacos
nacos:
server-addr: localhost:8848
namespace: ""
group: seata_group # 组名 跟我们之前配置的seata的配置文件的是对应的
application: seata-server # 服务名 跟我们之前配置的seata的配置文件的是对应的
tx-service-group: default_tx_group
service:
vgroup-mapping:
default_tx_group: default
data-source-proxy-mode: at3.3 开启事务管理
@globaltransactional 是 seata 提供的注解,用于实现分布式事务的管理。它是 seata 的全局事务控制器,通过这个注解,你可以在一个跨多个微服务的操作中,确保数据的一致性和事务的回滚。
作用:
- 开启全局事务:使用
@globaltransactional注解可以标记方法为全局事务,seata 会在这个方法执行时开启一个全局事务。 - 事务的提交与回滚:在方法执行过程中,如果发生异常,seata 会自动回滚所有与该全局事务相关的子事务。相反,如果方法执行成功,seata 会提交所有子事务。
基本语法:
@globaltransactional(name = "your-global-tx-name", rollbackfor = exception.class)
public void yourmethod() {
// your business logic
}参数:
name:指定全局事务的名称,通常为了区分不同的事务,可以给它一个有意义的名字。rollbackfor:指定哪些异常类型会导致事务回滚,默认是runtimeexception和error,如果需要捕获其他异常,可以通过此参数指定。
4. 演示流程
下面是通过访问 order 订单服务,然后执行 创建新的订单-> 扣除用户支付的钱 -> 减去用户购买商品的数量更新商品库存
@restcontroller
public class createordercontroller {
@autowired
ordermapper ordermapper;
@autowired
resttemplate resttemplate;
@requestmapping("/order/test")
@globaltransactional(name = "create-order", rollbackfor = exception.class)
public string createorder(@requestparam string userid,
@requestparam string commoditycode,
@requestparam integer count,
@requestparam integer money
) {
// 创建订单
order order = new order(null, userid, commoditycode, count, money);
ordermapper.insert(order);
// 扣除账户余额
map<string, string> mp1 = new hashmap<>();
mp1.put("userid", userid);
mp1.put("money", money.tostring());
string resp1 = resttemplate.postforobject("http://localhost:8001/account/test", mp1, string.class);
// 减去用户购买商品数量,更新库存
map<string, string> mp2 = new hashmap<>();
mp2.put("commoditycode", commoditycode);
mp2.put("count", count.tostring());
string resp2 = resttemplate.postforobject("http://localhost:8003/storage/test", mp2, string.class);
if ("ok".equals(resp1) && "ok".equals(resp2)) {
return "ok";
}
return "error";
}
}如果在调用其他服务时(扣除账户余额,更新库存时),如果抛出异常的话,整个事务就会回滚。比如减去用户购买商品数量时发现库存不足,抛出异常,整个事务回滚,之前的创建订单和扣除账户余额都会回滚
六、服务熔断和降级 sentinel
sentinel 是阿里巴巴开源的分布式系统流量控制组件,主要用于保护微服务在高并发、突发流量等场景下的稳定性和可靠性。sentinel 提供了 流量控制、熔断降级、系统自适应保护等机制
1. sentinel 的核心功能
sentinel 提供了以下核心功能:
- 流量控制:根据预定义的规则限制访问频率或数量,避免系统过载。
- 熔断降级:在请求失败率或响应时间过高时自动降级,防止雪崩效应。
- 系统自适应保护:基于系统的负载情况自动进行保护,如 cpu 使用率、内存占用等。
- 热点参数限流:对请求中的参数进行限流,比如按不同用户 id 或商品 id 限制请求。
2. sentinel 的基本概念
在 sentinel 中,核心是“资源”,可以是服务、接口或方法。每一个资源都会绑定一套限流规则或熔断规则。以下是 sentinel 的几个基本概念:
- 资源 (resource):受保护的对象,如 api 接口或数据库操作。
- 规则 (rule):用于定义流量控制、熔断降级的条件。
- slot chain:sentinel 使用 slot chain 机制来应用限流、降级、系统保护等规则。每一个 slot chain 包含多个 slot,不同 slot 处理不同的规则。
3. sentinel 的监控和控制台
sentinel 提供了 dashboard 管理控制台,可以用来监控各个资源的访问情况,并动态配置流量控制和熔断规则。(下载地址, 下载jar包)
启动 jar 包。

访问 http://localhost:8888/ (这里我设置的端口是 8888) 进入控制台。
账号密码都是 sentinel
引入 sentinel
<dependency>
<groupid>com.alibaba.cloud</groupid>
<artifactid>spring-cloud-starter-alibaba-sentinel</artifactid>
</dependency>spring.cloud.sentinel.transport.dashboard=localhost:8888
访问module任意controller后就可以看到 module1 加入到控制台

4. @sentinelresource注解
@sentinelresource 是 sentinel 中用于标记 方法 的注解,它允许你在方法调用时应用 sentinel 的规则和控制策略。通过使用这个注解,你可以将 sentinel 的流量控制、熔断降级、热点参数限流等功能集成到业务逻辑中。
1. value 参数:资源名称
- 作用:指定该方法的 资源名称,这个名称会作为 sentinel 资源的标识,用来应用流控、熔断、降级等策略。通常可以是方法名或其他具代表性的字符串。
- 默认值:方法名(如果未指定)。
2. blockhandler
- 参数:限流或熔断处理方法
- 作用:当资源受到 流量控制(如限流)或 熔断降级(如调用失败)时,会调用指定的
blockhandler方法。(handelblock方法一定要写上blockexception ex) - 类型:
blockhandler的方法可以是当前类中的一个静态方法,或是其他类的静态方法。
示例:
@sentinelresource(value = "myresource", blockhandler = "handleblock")
public string somemethod() {
// 你的业务逻辑
return "hello, sentinel!";
}
// 流控或熔断时的处理方法
public static string handleblock(blockexception ex) {
return "service is currently unavailable due to high traffic. please try again later.";
}在这个例子中,当 myresource 资源被流控或熔断时,handleblock 方法将被调用,返回一条友好的错误信息。
3. fallback
参数:降级处理方法
- 作用:当资源发生 异常 或 超时 时,触发降级逻辑,会调用指定的
fallback方法。这个方法需要与原始方法的签名一致。(流量超限或熔断触发时也会调用fallback,如果同时有fallback和blockhandler, 会优先调用blockhandler) - 类型:
fallback的方法可以是当前类中的一个静态方法,或是其他类的静态方法。
示例:
@sentinelresource(value = "myresource", fallback = "fallbackmethod")
public string somemethod() {
// 可能会抛出异常的业务逻辑
throw new runtimeexception("something went wrong");
}
// 降级方法
public static string fallbackmethod(throwable ex) {
return "service is temporarily unavailable due to internal error. please try again later.";
}在这个例子中,当 somemethod 方法抛出异常时,fallbackmethod 会被调用,返回一个默认的降级响应。
4. exceptionstoignore 参数:忽略的异常类型
- 作用:指定不触发 降级 或 熔断 的异常类型。即使这些异常发生,也不会进入
fallback或blockhandler。 - 默认值:没有忽略的异常,所有的异常都会触发降级逻辑。
5. blockhandlerclass 参数:自定义流控处理类
- 作用:指定一个类,其中包含
blockhandler处理方法。这样可以将流控处理方法与业务逻辑分离,便于管理。 - 默认值:如果未指定,
blockhandler方法会在当前类中查找。
示例:
@sentinelresource(value = "myresource", blockhandler = "handleblock", blockhandlerclass = blockhandler.class)
public string somemethod() {
// 业务逻辑
return "hello, sentinel!";
}
// 自定义流控处理类
public class blockhandler {
public static string handleblock(blockexception ex) {
return "service is temporarily unavailable due to traffic control.";
}
}6. fallbackclass 参数:自定义降级处理类
- 作用:指定一个类,其中包含
fallback处理方法。这样可以将降级处理方法与业务逻辑分离,便于管理。 - 默认值:如果未指定,
fallback方法会在当前类中查找。
示例:
@sentinelresource(value = "myresource", fallback = "fallbackmethod", fallbackclass = fallbackhandler.class)
public string somemethod() {
// 业务逻辑
throw new runtimeexception("something went wrong");
}
// 自定义降级处理类
public class fallbackhandler {
public static string fallbackmethod(throwable ex) {
return "service is temporarily unavailable due to an error.";
}
}5. 流量控制
5.1 流控模式
- 直接:只针对于当前接口。
- 关联:如果指定的关联接口超过qps(每秒的请求数),会导致当前接口被限流。
- 链路:更细粒度的限流,能精确到具体的方法, 直接和关联只能对接口进行限流
链路流控模式指的是,当从指定接口过来的资源请求达到限流条件时,开启限流。
# 关闭context收敛,这样被监控方法可以进行不同链路的单独控制 spring.cloud.sentinel.web-context-unify: false # 比如我 /test1 和 /test2 接口下都调用了 test 方法,那么我可以在sentinel 控制台中分别对 /test1 和 /test2 的 test 进行设置

5.2 流控效果
快速拒绝: 既然不再接受新的请求,那么我们可以直接返回一个拒绝信息,告诉用户访问频率过高。
预热: 依然基于方案一,但是由于某些情况下高并发请求是在某一时刻突然到来,我们可以缓慢地将阈值提高到指定阈值,形成一个缓冲保护
排队等待: 不接受新的请求,但是也不直接拒绝,而是进队列先等一下,如果规定时间内能够执行,那么就执行,要是超时就算了。
5.3 实现对方法的限流控制
我们可以使用到@sentinelresource对某一个方法进行限流控制,无论是谁在何处调用了它,,一旦方法被标注,那么就会进行监控。
@restcontroller
public class testcontroller {
@autowired
resttemplate resttemplate;
@autowired
myservice myservice;
@getmapping("/test1")
public string test1() {
return myservice.test();
}
@getmapping("/test2")
public string test2() {
return myservice.test();
}
}
// ------------------------
@service
public class myservice {
@sentinelresource("mytest") // 标记方法
public string test() {
return "test";
}
}添加 spring.cloud.sentinel.web-context-unify=false, 可以对 /test1 和 /test2 的 mytest单独控制

不添加的, 无法单独控制

一些坑
如果在方法上添加了 @sentinelresource 注解,但是不在控制台中显示的话(不显示mytest), 可能是因为添加的方法没有加入到spring容器中进行管理。比如我当时下面这样写就出现了不在控制台显示的情况。
@restcontroller
public class testcontroller {
@getmapping("/test1")
public string test1() {
return test();
}
@sentinelresource("mytest")
public string test() {
return "test";
}
}5.4 处理限流情况
当访问某个 接口 出现限流时,会抛出限流异常,重定向到我们添加的路径
@requestmapping("/blockpage")
public string blockpage() {
return "blockpage";
}# 用于设置当 流控 或 熔断 触发时,返回给用户的 阻塞页面 spring.cloud.sentinel.block-page=/blockpage
当访问的某个 方法 出现了限流,为 blockhander 指定方法,当限流时会访问 test2, 并且可以接受 test 的参数
@service
public class myservice {
@sentinelresource(value = "mytest", blockhandler = "test2")
public string test(int id) {
return "test";
}
public string test2(int id, blockexception ex) {
return "test 限流了 " + id;
}
}5.5 处理异常的处理
当调用 test 时抛出了异常的话,那么就会执行 fallback 指定的方法, exceptionstoignore 指定的是忽略掉的异常。(限流的话会抛出限流的异常,也会被捕获,执行 fallback 指定的方法)
如果 fallback 和 blockhandler 都指定了方法,出现限流异常会优先执行 blockhandler 的方法
@service
public class myservice {
@sentinelresource(value = "mytest", fallback = "except", exceptionstoignore = ioexception.class)
public string test(int id) {
throw new runtimeexception("hello world");
}
// 注意参数, 必须是跟 test 的参数列表相同, 然后可以多加一个获取异常的参数
public string except(int id, throwable ex) {
system.out.println("hello = " + ex.getmessage());
return ex.getmessage();
}
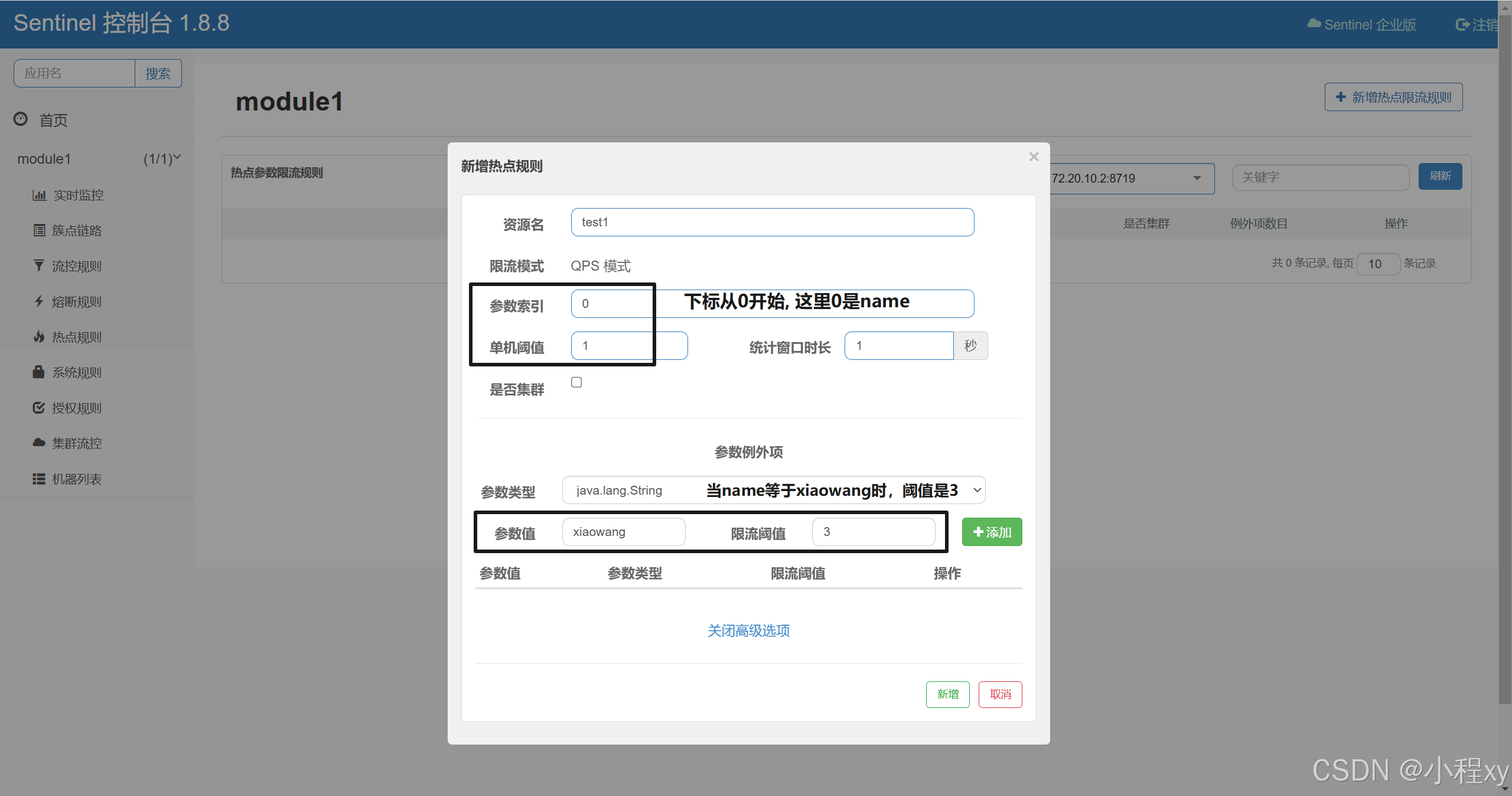
}5.6 热点参数限流
对接口或方法的某个参数进行限流
@getmapping("/test1")
@sentinelresource(value = "test1")
public string test1(@requestparam(required = false) string name, @requestparam(required = false) string age) {
return name + " " + age;
}
6. 熔断降级
1. 服务熔断
当某个服务的错误率或失败次数(如异常或超时)超过预设的阈值时,熔断器就会“断开”,该服务的调用将不会继续执行。熔断器“断开”后,所有请求都会被 拒绝,直到熔断器进入 恢复阶段,然后根据预设规则恢复正常工作。
2. 熔断规则
2.1 熔断规则

熔断规则定义了什么情况下触发熔断。常见的触发条件有:
- 异常比例(异常比例熔断):当某个资源的调用异常(如超时、返回错误等)比例超过设定的阈值时,触发熔断。
- 错误数(错误数熔断):当某个资源的调用错误次数超过设定的阈值时,触发熔断。
- rt(响应时间熔断):当某个资源的调用响应时间超过设定的阈值时,触发熔断。
这些规则是可以配置的,通常会在应用初始化时进行设置。
2.2 熔断恢复机制
熔断后,sentinel 会进入 自恢复机制,通过设定的时间窗口,逐渐恢复正常的服务调用。这一恢复过程通常包括以下两个阶段:
- 半开状态:熔断器进入半开状态,允许一定数量的请求尝试访问该资源。此时系统会验证该资源是否已恢复,若恢复则正常调用,若失败则继续熔断。
- 正常状态:如果半开状态中的请求均成功,则熔断器恢复为正常状态,恢复正常的请求处理。
3. 服务降级 (service degradation)
服务降级是指在某些情况下,通过返回一个默认值、简单处理或快速失败来减少服务的压力,避免因资源超载或异常请求导致服务崩溃。sentinel 通过配置不同的降级策略,使得系统能够在流量激增或服务不稳定时自动切换到降级模式。
最后简单介绍一下限流,熔断,降级之间的联系。 根据降级的概念,当出现限流或熔断的时候都会触发降级的方法,只不过熔断会根据自己的配置,来跟熔断的服务断开联系,不再接受请求。而限流的话不会断开服务,而是继续接受请求,如果请求不满足 限流规则的话,还是会进入到降级的方法
七、服务链路追踪
在zipkin官网下载 zipkin.jar 包。下载地址
micrometer tracing 是 spring 官方在现代可观测性(observability)体系中的新工具,用于实现分布式链路追踪。
1. 核心概念
span
- 每个 span 表示一个操作的执行过程(如调用某个方法、处理一个 http 请求)。
- 包含操作的开始时间、持续时间、名称等信息。
- trace 是由多个 span 组成的分布式调用链。
trace
- 表示分布式系统中多个服务协作完成的整体调用链。
- 包括一个根 span 和多个子 span。
context propagation
- 在分布式系统中,需要在服务之间传递上下文(如 traceid 和 spanid),以实现跨服务的追踪。
- micrometer tracing 通过支持 w3c trace context 标准(opentelemetry 默认标准)完成上下文传递。
2. 工作原理
生成和传播追踪信息
- 服务 a 生成 traceid 和 spanid,并通过 http header 或消息队列传递给服务 b。
- 服务 b 接收这些信息,继续生成新的 span 并关联到 trace。
采样策略
- 决定是否记录 trace 数据(例如只采样部分请求以减少性能开销)。
- micrometer tracing 提供多种采样策略,可以通过配置控制。
导出追踪数据
- micrometer tracing 支持将追踪数据导出到多个后端(如 jaeger、zipkin 或 prometheus)。这里我们用
zipkin - 通过 opentelemetry bridge 提供对多种观察后端的支持。
3. 简单配置
在 spring boot 3+ 项目中,micrometer tracing 的依赖配置如下:
引入依赖
在 pom.xml 中添加以下依赖:
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-actuator</artifactid>
</dependency>
<dependency>
<groupid>io.micrometer</groupid>
<artifactid>micrometer-tracing</artifactid>
</dependency>
<dependency>
<groupid>io.micrometer</groupid>
<artifactid>micrometer-tracing-bridge-brave</artifactid>
</dependency>
<dependency>
<groupid>io.micrometer</groupid>
<artifactid>micrometer-observation</artifactid>
</dependency>
<dependency>
<groupid>io.zipkin.reporter2</groupid>
<artifactid>zipkin-reporter-brave</artifactid>
</dependency>
<!-- 使用feign的话加入下面这个依赖 -->
<!-- <dependency>-->
<!-- <groupid>io.github.openfeign</groupid>-->
<!-- <artifactid>feign-micrometer</artifactid>-->
<!-- </dependency>-->配置
management:
zipkin:
tracing:
endpoint: http://localhost:9411/api/v2/spans
tracing:
sampling:
probability: 1.0 #采样率默认0.1(10次只能有一次被记录),值越大手机越及时之后就可以访问 http://127.0.0.1:9411
八、服务网关 gateway
gateway(网关)是微服务架构中的一个重要组件,它通常用作客户端和多个微服务之间的中介,负责请求的路由、负载均衡、认证、限流、安全控制等功能。它通常部署在前端,起到了“入口”作用,是微服务的前端统一访问点。
1. 网关的核心功能
网关的核心职责是将外部请求路由到相应的微服务,同时提供一些重要的功能:
- 请求路由: 网关根据请求的路径、请求头、参数等信息,将请求转发到对应的微服务。
- 负载均衡: 网关能够实现请求的负载均衡,将请求分发到多个后端服务实例,提升服务的可用性和性能。
- 安全性: 网关通常是整个系统的第一道防线,可以进行请求的身份验证、授权控制、加密等。
- 服务发现: 通过与服务注册中心集成,网关可以动态地获取微服务的实例信息,实现动态路由。
- 过滤器: 允许在请求处理过程中添加自定义逻辑。过滤器分为“全局过滤器”和“局部过滤器”。
- 动态路由: 可以动态添加路由规则,无需重新启动网关。
2. 准备工作
引入依赖
<!-- gateway 依赖 -->
<dependency>
<groupid>org.springframework.cloud</groupid>
<artifactid>spring-cloud-starter-gateway</artifactid>
</dependency>
<!-- 需要基于注册中心转发请求的话,加上 nacos 依赖 -->
<dependency>
<groupid>com.alibaba.cloud</groupid>
<artifactid>spring-cloud-starter-alibaba-nacos-discovery</artifactid>
</dependency>
<!-- 如果用到 lb: 的话需要在引入getaway的pom中引入loadbalancer -->
<dependency>
<groupid>org.springframework.cloud</groupid>
<artifactid>spring-cloud-starter-loadbalancer</artifactid>
</dependency>配置路由规则:
spring:
application:
name: gateway
cloud:
nacos:
discovery:
server-addr: localhost:8848
gateway:
# 配置路由,这里是一个列表,每一项都包含很多信息
routes:
- id: module1 # 路由名称(nacos中的服务名)
uri: lb://module1 # 路由地址,lb表示使用负载均衡到微服务,也可以使用http正常转发
predicates: # 路由规则,决定哪些请求会被路由
- path=/test1/** # 请求的路径匹配规则
filters: # 向请求头中添加 test=hello world
- addrequestheader=test, hello world
server:
port: 8002在 spring cloud gateway 中,predicates 和 filters 是配置路由规则和处理请求
常见的 predicates(路由匹配条件):
path:根据请求路径进行匹配path=/users/**:匹配以/users/开头的路径。- 示例:
/users/123、/users/details。
method:根据 http 方法进行匹配method=get:只匹配get请求。method=post:只匹配post请求。- 示例:
get /users/123、post /users。
host:根据请求的 host 进行匹配host=*.example.com:匹配所有请求的 host 名称为example.com的请求。- 示例:
get /users请求的 host 为api.example.com。
query:根据查询参数进行匹配query=username={value}:匹配查询参数username的值。- 示例:
get /users?username=john。
header:根据请求头进行匹配header=authorization=bearer {token}:匹配带有特定 authorization 头的请求。- 示例:
get /users/123,并且authorization=bearer <token>。
- 常见的
filters(过滤器): filters用于在请求和响应之间进行处理,通常用于修改请求头、响应体、重定向等。这里的过滤器是局部的过滤器addrequestheader:添加请求头addrequestheader=x-request-foo, bar:向请求中添加x-request-foo头,值为bar。- 示例:请求中会包含
x-request-foo: bar。
addresponseheader:添加响应头addresponseheader=x-response-foo, baz:向响应中添加x-response-foo头,值为baz。
setpath:修改请求路径setpath=/newpath/{segment}:将请求的路径设置为新的路径。- 示例:请求
/users/123会被设置为/newpath/123。
redirectto:重定向请求到其他地址redirectto=301, /new-location:将请求重定向到/new-location。- 示例:会发出
301重定向到/new-location。
上面的predicates和filters只写了一部分,具体可以参考spring官网 地址
spring cloud gateway 与其他网关对比
- 与 nginx 对比: nginx 是一个高性能的 web 服务器,可以作为反向代理和负载均衡器。虽然 nginx 可以用作网关,但它不提供像 spring cloud gateway 那样丰富的业务逻辑处理能力(如动态路由、api 聚合、过滤器等)。spring cloud gateway 更多地专注于微服务架构中的业务需求。
3. 自定义全局和局部过滤器
过滤器是网关的一个重要特性,可以在请求和响应的生命周期中做一些额外的处理。
- 全局过滤器(global filter):全局过滤器可以处理所有请求和响应。你可以在全局过滤器中添加日志记录、认证、限流等操作。
- 局部过滤器(gateway filter):局部过滤器是针对某个特定路由的过滤器。你可以在路由配置中使用这些过滤器进行特定操作。
3.1 自定义全局过滤器
在 spring cloud gateway 中,全局过滤器(global filters)用于在请求和响应过程中对所有路由进行处理。
过滤器的作用:
- 请求过滤: 在请求到达后端微服务之前对请求做一些处理,比如增加请求头、日志记录、权限校验等。
- 响应过滤: 在响应从后端微服务返回到客户端之前对响应做一些修改,比如修改响应内容、加密、日志记录等。
1. 创建一个全局过滤器
首先,需要创建一个实现 globalfilter 接口的类。在这个类中,你可以定义过滤器的逻辑。
import org.springframework.cloud.gateway.filter.gatewayfilterchain;
import org.springframework.cloud.gateway.filter.globalfilter;
import org.springframework.core.ordered;
import org.springframework.http.httpheaders;
import org.springframework.stereotype.component;
import org.springframework.web.server.serverwebexchange;
import reactor.core.publisher.mono;
@component
public class addheaderglobalfilter implements globalfilter, ordered {
@override
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain) {
return chain.filter(exchange);
}
@override
public int getorder() {
return 1;
}
}2. 全局过滤器的工作原理
filter():在这里你可以获取到serverwebexchange对象,它包含了请求和响应的所有信息。你可以在这里操作请求和响应的内容,进行一些预处理或后处理。最后,调用chain.filter(exchange)以传递请求继续向下执行其他过滤器或路由。getorder():返回一个整数值,用来决定过滤器的执行顺序。值越小的过滤器会优先执行。一般来说,数字越小的过滤器会在请求刚开始时执行,而数字大的过滤器会在请求的最后阶段执行。- 如果你有多个全局过滤器,它们会按照
getorder()返回值的顺序执行。
3. 示例:添加请求头
假设我们需要为每个请求添加一个特定的请求头。
package com.cloud.gateway.config;
import org.springframework.cloud.gateway.filter.gatewayfilterchain;
import org.springframework.cloud.gateway.filter.globalfilter;
import org.springframework.core.ordered;
import org.springframework.http.httpheaders;
import org.springframework.stereotype.component;
import org.springframework.web.server.serverwebexchange;
import reactor.core.publisher.mono;
@component
public class addheaderglobalfilter implements globalfilter, ordered {
@override
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain) {
// 获取请求的 headers
httpheaders headers = exchange.getrequest().getheaders();
// 打印原始请求头
system.out.println("request headers: " + headers);
// 为请求添加一个新的头部
exchange.getrequest().mutate()
.header("test", "hello world") // 添加请求头
.build();
// 继续传递到下一个过滤器
return chain.filter(exchange);
}
@override
public int getorder() {
return 1;
}
}3.1 自定义局部过滤器 自定义局部过滤器(gatewayfilter):
import org.springframework.cloud.gateway.filter.gatewayfilter;
import org.springframework.cloud.gateway.filter.factory.abstractgatewayfilterfactory;
import org.springframework.http.httpstatus;
import org.springframework.stereotype.component;
@component
public class authfilter extends abstractgatewayfilterfactory<authfilter.config> {
public authfilter () {
super(config.class);
}
@override
public gatewayfilter apply(config config) {
return (exchange, chain) -> {
system.out.println("authfilter");
// 下面实现自己的逻辑
string token = exchange.getrequest().getheaders().getfirst("token");
if (token == null || !token.equals(config.gettoken())) {
exchange.getresponse().setstatuscode(httpstatus.unauthorized);
return exchange.getresponse().setcomplete();
}
return chain.filter(exchange); // 继续处理链中的其他过滤器
};
}
public static class config {
private string token;
public string gettoken() {
return token;
}
public void settoken(string token) {
this.token = token;
}
}
}使用局部过滤器
局部过滤器通常在路由配置中使用,你可以将它应用于特定的路由,例如:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://user-service
predicates:
- path=/users/**
filters:
- authfilter # 这里引用自定义的局部过滤器九、分布式配置管理 nacos
分布式配置管理功能的主要作用是在不同的服务之间集中管理和统一分发配置。这使得系统在配置变更时无需重启服务,可以实时更新配置,从而达到快速响应的效果。
基本概念
- data id(数据 id):表示每个配置的唯一标识。在 nacos 中,一个配置项通常用 data id 表示,通常为字符串形式,代表唯一的配置文件名。
- group(组):用于将不同的配置项进行分组管理,方便区分开发、测试、生产环境等场景。
- namespace(命名空间):用于逻辑隔离配置数据。不同命名空间内的配置是互相隔离的,这在多租户场景中非常有用。
- 配置项:每个具体的配置信息称为配置项,可以是一个或多个键值对。
nacos 配置管理的使用步骤

引入 nacos 配置管理
引入依赖
<dependency>
<groupid>org.springframework.cloud</groupid>
<artifactid>spring-cloud-starter-bootstrap</artifactid>
</dependency>
<dependency>
<groupid>com.alibaba.cloud</groupid>
<artifactid>spring-cloud-starter-alibaba-nacos-config</artifactid>
</dependency>配置 nacos 服务器地址
在 bootstrap.yml 文件中,设置 nacos 配置中心地址和必要的配置信息:
spring:
application:
name: module1
profiles:
active: dev
cloud:
nacos:
config:
server-addr: localhost:8848 # 服务地址
file-extension: yamldata_id 一般命名采用 application.name-profiles.active.filex-extension,根据上面的配置,我的dataid就是 module1-dev.yaml

获取配置
可以使用 spring boot 的 @value 注解来获取 nacos 中的配置项。例如:
@restcontroller
@refreshscope
public class testnacosconfigcontroller {
@value("${test}") // 获取到 test 的值
private string test;
@getmapping("/nacos/config")
public string nacosconfig() {
return test;
}
}动态刷新配置
使用 @refreshscope 注解,自动刷新配置:(当我们配置中心修改时,不需要重启项目,test 就会自动更新)
@restcontroller
@refreshscope
public class testcontroller {
@value("${test}")
private string test;
@getmapping("/nacos/config")
public string getconfig() {
return test;
}
}我踩的一些坑:
- 最好是新建一个
bootstrap.yaml文件写nacos config的配置,不要直接在 application 中写,不然会遇到奇怪的bug。 bootstrap.yaml中一定还要写上spring: application: name: module1 profiles: active: dev这些东西,即使你在 application 中已经写了- 如果都按照上面的要求做了,但是就是无法通过
@value获取到配置属性的话,可以尝试降低spring-cloud-starter-alibaba-nacos-config的版本。
这里我学习的时候就遇到了,通过第一个配置(2023.0.1.3)死活获取不到 test,但是用第二个配置(降低版本的),其他的都没改,就可以获取到。
<dependency>
<groupid>com.alibaba.cloud</groupid>
<artifactid>spring-cloud-starter-alibaba-nacos-config</artifactid>
</dependency><dependency>
<groupid>com.alibaba.cloud</groupid>
<artifactid>spring-cloud-starter-alibaba-nacos-config</artifactid>
<version>2023.0.1.2</version>
</dependency>到此这篇关于spring cloud内容汇总(各个功能模块、启动、部署)的详细过程的文章就介绍到这了,更多相关spring cloud启动部署内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论