dense_rank()是一种窗口函数,用于在数据库中计算密集等级。它为每个行分配一个密集等级,并根据指定的排序顺序进行排列。比如:如果有两个排名为1的值,接下来的值将会被标记为2,而不是3。
一、dense_rank() 函数
dense_rank() 也是一个窗口函数,用于为结果集中的每一行分配排名。dense_rank() 在遇到相同的排序值时,会为相同的行分配相同的排名,并且下一个排名不会跳过。换句话说,如果有两个排名为1的值,接下来的值将会被标记为2,而不是3。
语法结构:
dense_rank() over (
partition by <expression>[{,<expression>...}]
order by <expression> [asc|desc], [{,<expression>...}]
)
- partition by:用于将结果集分区,针对每个分区单独排名。
- order by:指定排序的列,决定了排名的依据。
注意,over()里头的分组以及排序的执行晚于 where 、group by、 order by 的执行。
二、使用案例
数据准备:
create table `student`(
id int(10) not null primary key,
name varchar(20) not null,
score int(10) not null
);
insert into `student` values(1,'a',100);
insert into `student` values(2,'b',100);
insert into `student` values(3,'c',95);
insert into `student` values(4,'d',95);
insert into `student` values(5,'e',95);
insert into `student` values(6,'a',90);
insert into `student` values(7,'a',89);
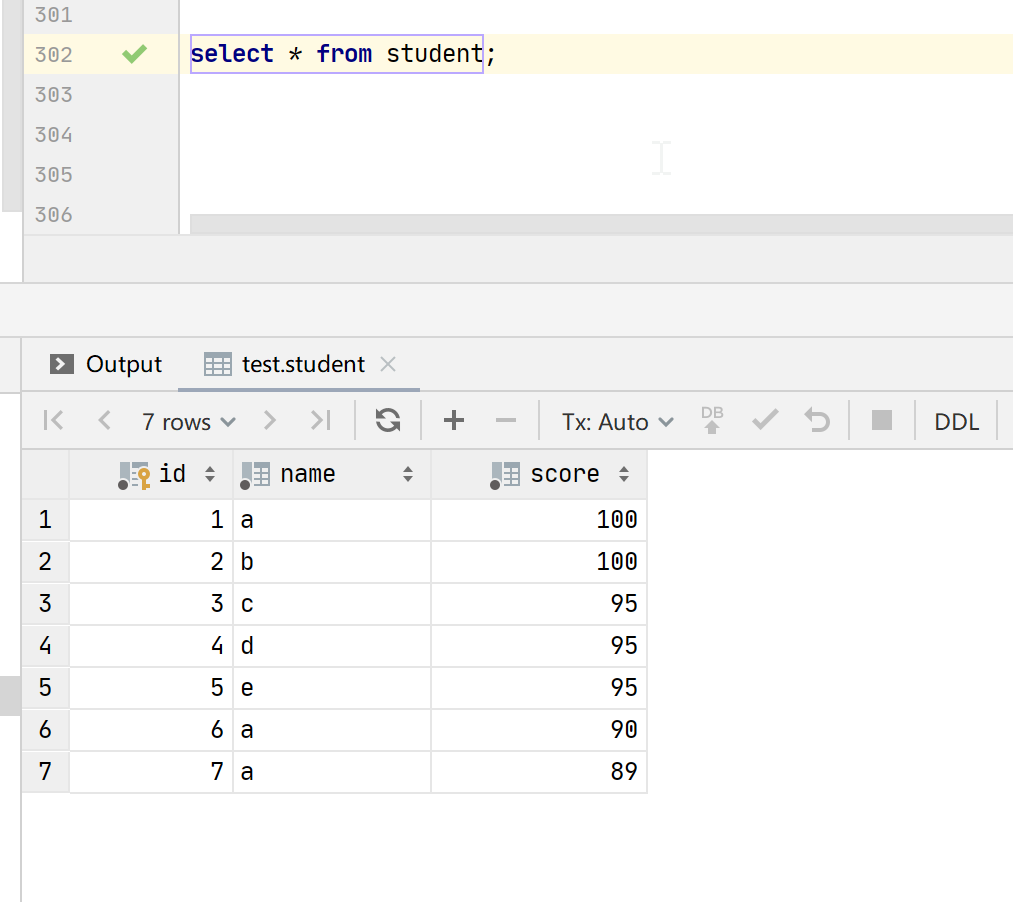
表数据:
2.1、按成绩进行排名
select *,dense_rank() over(order by score desc) as dr from `student`;
两个并列第一名后,下一个是第二名,不会跳过排名。
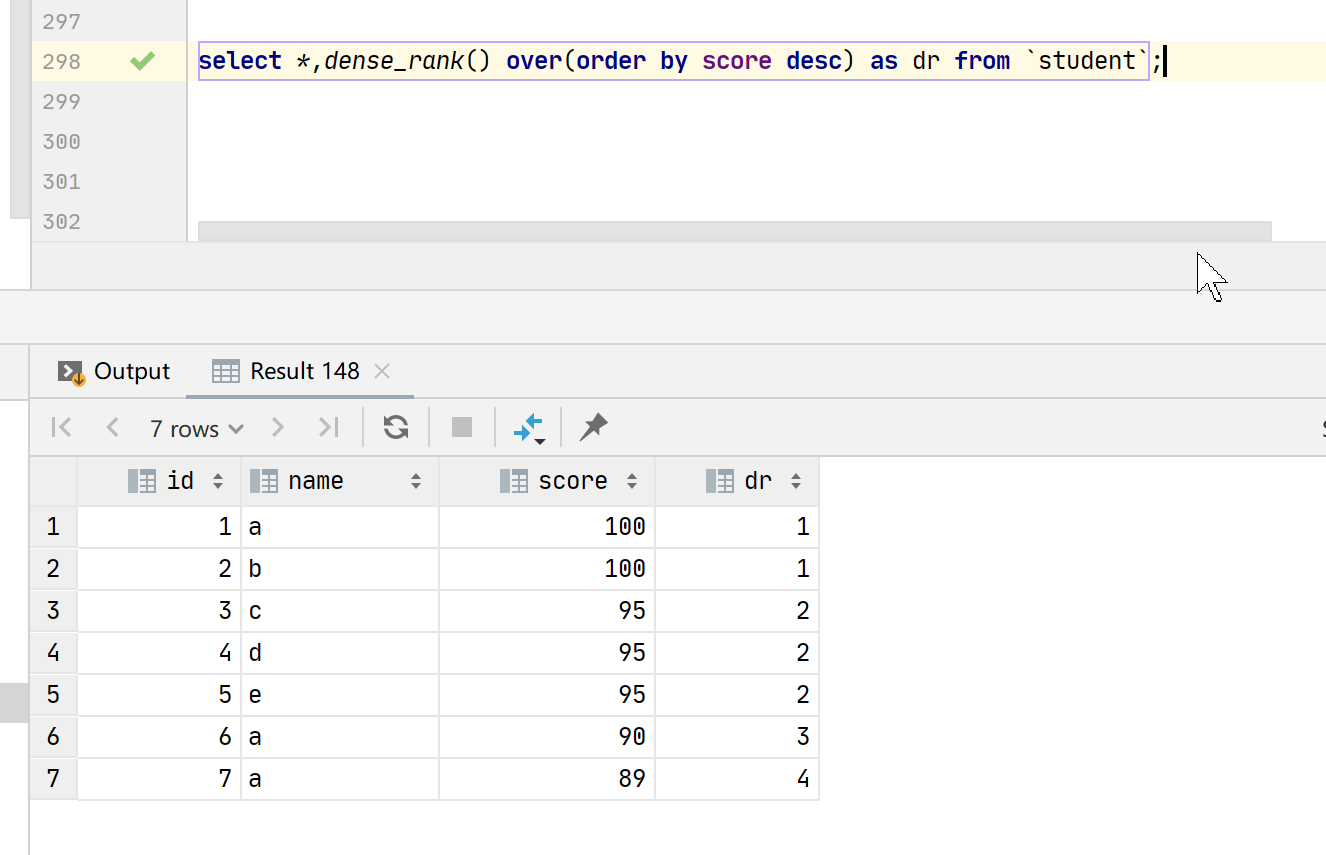
上图中over中没有使用partition进行分组,默认都是同一组
2.2、获取排名前五的数据
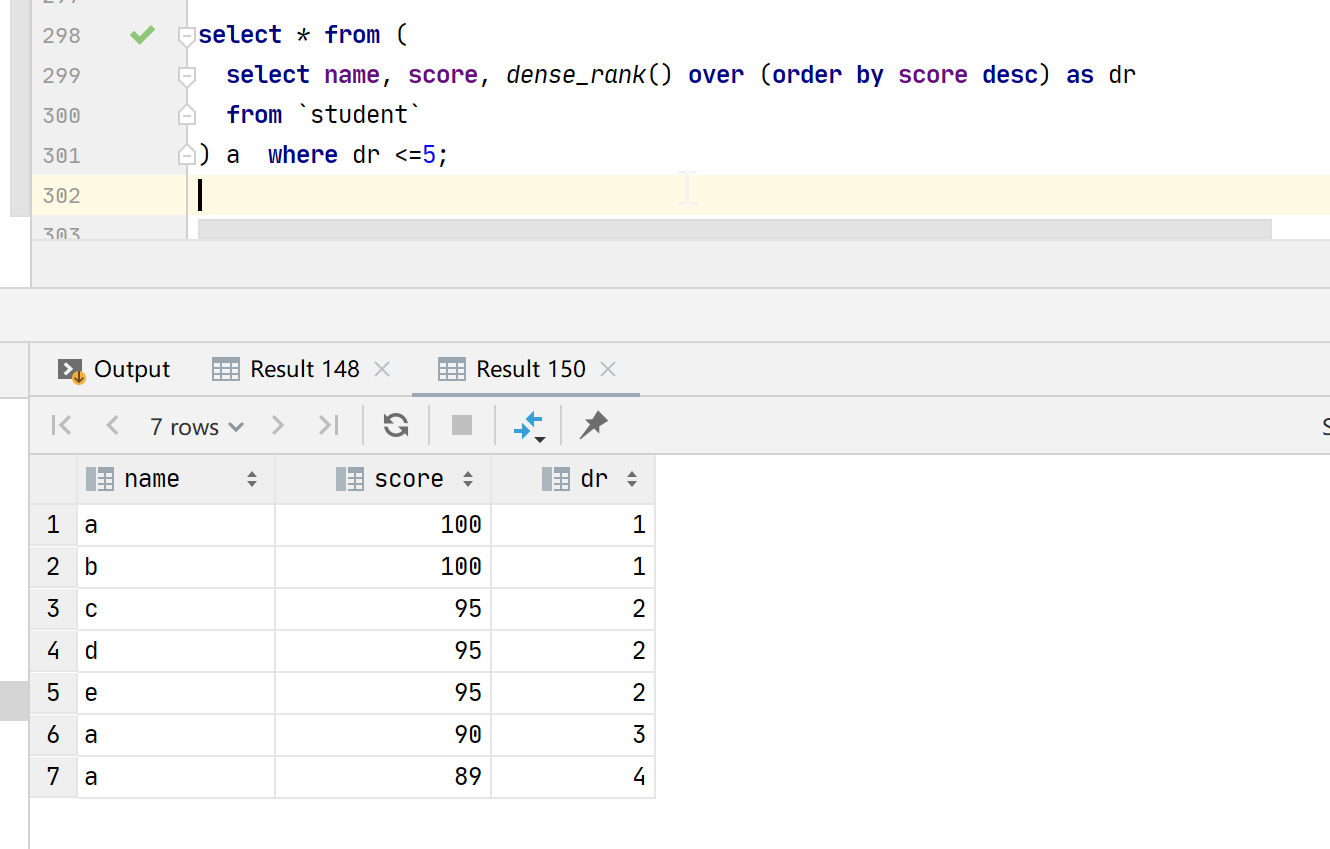
select * from ( select name, score, dense_rank() over (order by score desc) as dr from `student` ) a where `dr` <=5;
2.3、分组后再排名
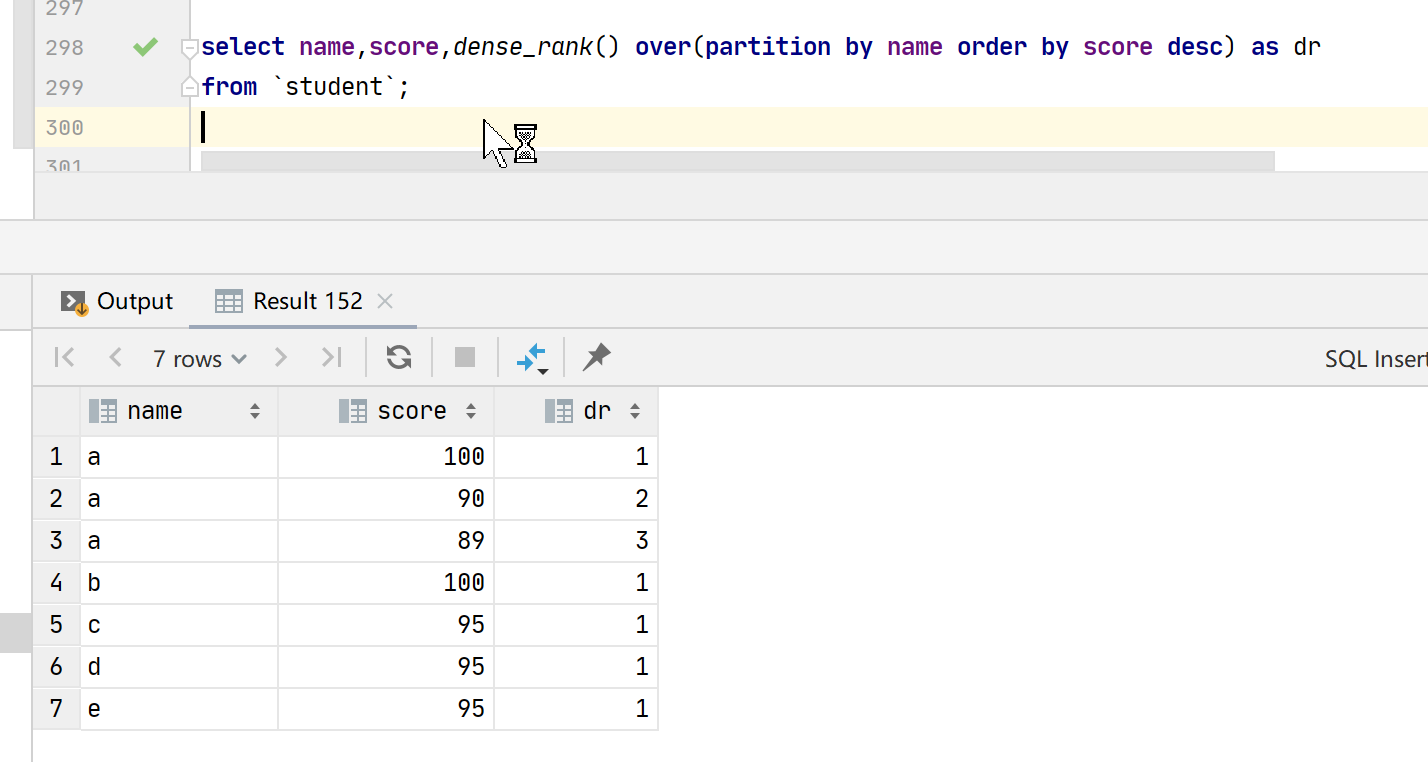
select name,score,dense_rank() over(partition by name order by score desc) as dr from `student`;
首先,partition by子句按姓名将结果集分成多个分区。
然后,order by子句按分数对结果集进行排序。
三、总结
在数据分析中,row_number()、rank() 和 dense_rank() 是非常有用的工具。它们可以帮助用户快速对数据进行排名和分类分析。虽然这三种函数的作用相似,但因其在处理重复值时的行为不同,所以在使用时需要根据具体需求进行选择。
3.1、row_number()、rank() 和 dense_rank() 的区别
- row_number():为每一行分配唯一的行号,适合唯一标识需求。
- rank():为重复值分配相同的排名,并在后续排名中跳过名次,适合需要处理排名的场景。
- dense_rank():为重复值分配相同的排名,但不跳过名次,适合希望连续排名的场景。
下面表格总结了这三个函数的主要区别:
| 函数 | 特点 | 排名示例 |
|---|---|---|
| row_number | 为每行分配唯一的数字 | 1, 2, 3, 4, … |
| rank | 相同的值共享相同的排名,排名会跳过数字 | 1, 1, 3, 4, … |
| dense_rank | 相同的值共享相同的排名,不跳过数字 | 1, 1, 2, 3, … |
具体请参考《》、《》、《》
到此这篇关于mysql之dense_rank()分组排序函数的使用的文章就介绍到这了,更多相关mysql dense_rank()分组排序内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论