简介
python-docx 是开源的一个 python 库,用于读取、创建和更新microsoft word 2007+(.docx)文件。目前最新版本是1.1.2。
官方文档地址:python-docx.readthedocs.io/en/latest/
其开源仓库地址:github.com/python-openxml/python-docx
准备docx文档
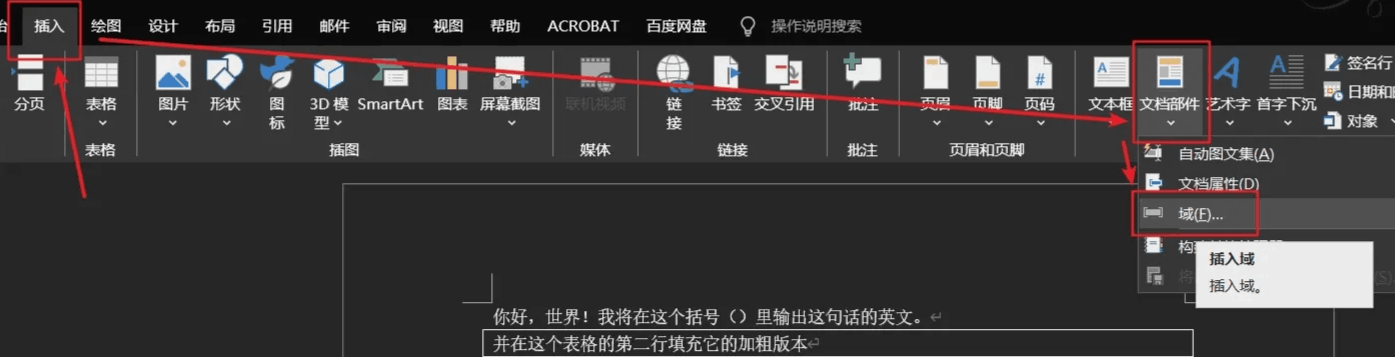
docx 文档可以用 office 打开,也可以用 wps,这边截图使用的是 wps,因为里面邮件合并部分 “插入合并域/next域” 自带的小书名号非常独特,这个符号的正式名称是角引号,主要用于法语、俄语、西班牙语等欧洲语言中,中文语境里使用较少,很适合作为后面遍历行段内容替换字符串时的标识符。
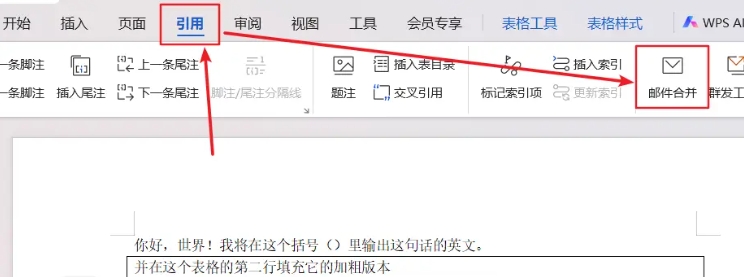
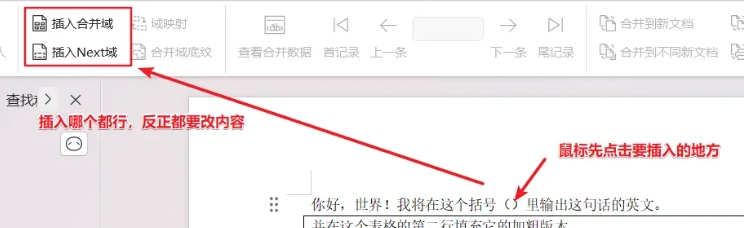
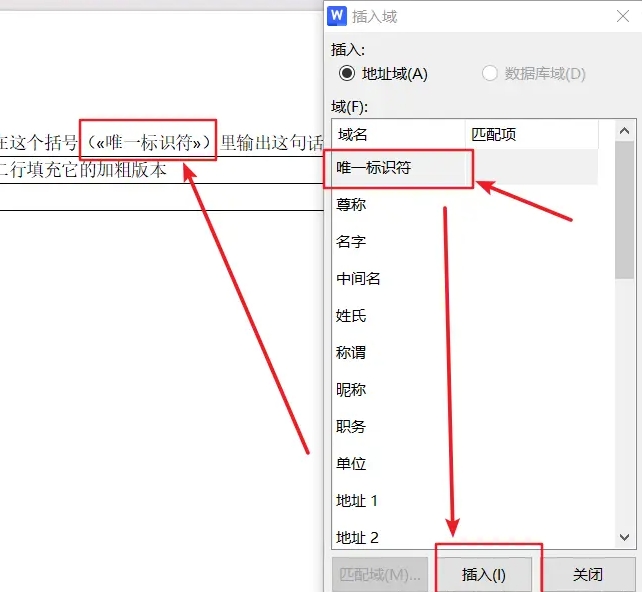
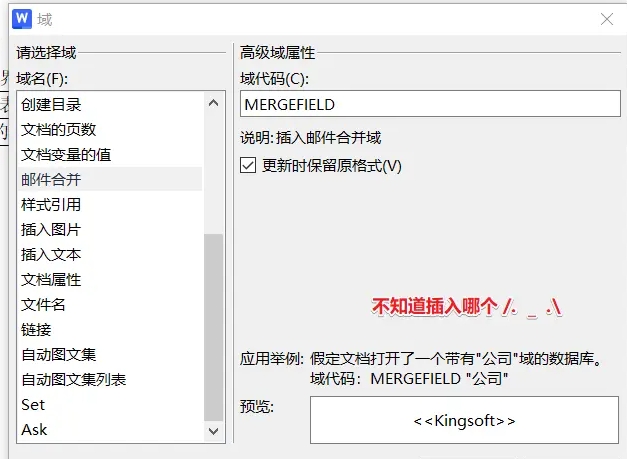
在 “插入域” 弹窗的选项中选择域名为 “唯一标识符” 的选项插入,先前鼠标定位的位置就会添加上这个小书名号包裹的 “唯一标识符”。
只要插入了一个标识符,剩下的就可以复制粘贴了。角引号里面的内容也可以改成自己想要的字段名称,中英文不限。

像下面的示例表格,便是直接从前面这个唯一标识符复制过来的。复制时记得把角引号包裹住了。wps里面鼠标点击标识符时会自动出现截图中的深色区域,很方便检查。

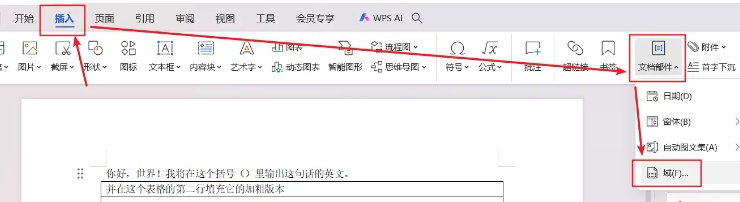
不过这个邮件合并域功能目前我只在 wps 的 “引用” 模块里有找到,在 office 的 word 里没有找到对应的地方。虽然 “插入” 里可以选择 “域”,但操作起来容易出错,我自己就没看懂应该选哪个去插入……
python代码
前面特地添加一个表格做示例,主要是因为获取文档内容时,表格需要单独的遍历。
from docx import document
def merge_docx(doc, data):
'''
替换文档里各个占位符,替换后保存
:param data: 数据data = { '这句话的英文': 'hello world!','这句话的加粗版本': 'hello world!' }
:return:
'''
# 遍历文档中的所有段落
for para in doc.paragraphs:
# 替换每个自定义合并域
for key, value in data.items():
if f"«{key}»" in para.text:
para.text = para.text.replace(f"«{key}»", value)
# 遍历文档中的所有表格,再遍历单元格内段落
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
cell_text = cell.paragraphs[0].text
if cell_text[1:-1] in data.keys():
key = cell_text[1:-1]
val = data[key] # cell.text.replace(f"«{key}»", data[key])
pa = cell.paragraphs[0]
pa.clear()
r = pa.add_run(val)
r.bold = true # 加粗需要在run级别设置
data={ '这句话的英文': 'hello world!','这句话的加粗版本': 'hello world!' }
doc=document('test.docx')
merge_docx(doc,data)
doc.save('result.docx')
执行完毕,文档成功生成,里面的内容也成功替换,如下图:

docx转pdf
有时候,文档需要转换成 pdf 格式,python-docx 缺少相应的工具,因此只能寻求其他工具,比如 win32com,恰好,win32com 可以调用到办公软件里的 wdexportformatpdf 方法,用来将文件导出成pdf。
这个方法在 office 和 wps 里都有存在,wps 的 weboffice 文档 可以做参考。

office 官方的文档也可以看看。
两个软件的可用方法还是有区别的,只是恰好在导出成pdf这方面是一致。体现在代码中,最主要的便只剩下的调用的底层办公软件对象。
import win32com, pythoncom
from win32com.client import constants, gencache
def word2pdf(word_path):
pdf_path = word_path.replace(".docx", ".pdf")
pythoncom.coinitialize()
wc = win32com.client.constants
# 下面这个地方,wps 就用 kwps.application ,office就用 word.application
wps = gencache.ensuredispatch("kwps.application")
doc = wps.documents.open(word_path, readonly=1)
doc.saveas2(filename=pdf_path, fileformat=wc.wdexportformatpdf)
wps.documents.close(wc.wddonotsavechanges)
wps.documents.close()
wps.quit()
word2pdf('result.docx')
执行完毕,文件成功导出。任务完成。
到此这篇关于python-docx读取模板文档并填充数据的文章就介绍到这了,更多相关python-docx读取模板文档内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论