mysql实现分布式锁有三种方式
1:基于行锁实现分布式锁
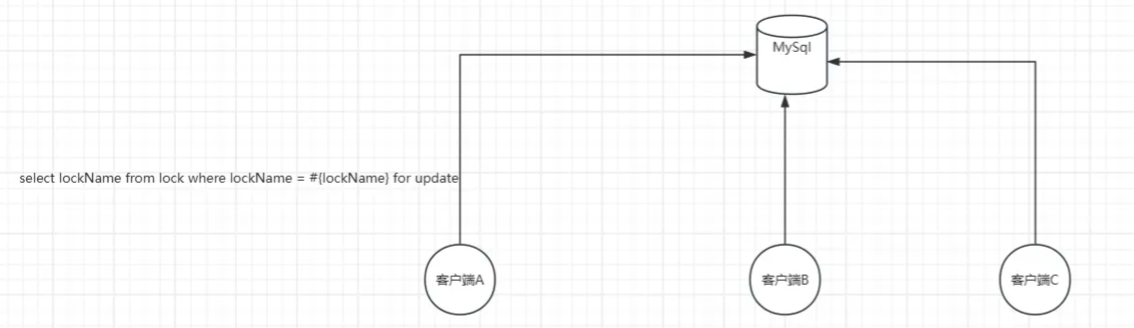
实现原理
首先我们的表lock要提前存好相对应的lockname,这时候多个客户端来执行
select lock_name from lock where lock_name = #{lockname} for update
由于第一个客户端来执行这条sql语句,给这行记录加了行锁,在这个客户端没有提交事务之前,其它客户端就会被阻塞住。所以这时候就只能有一个客户端去执行我们自己的业务了,其它客户端就只能阻塞等待,那么这个过程就是加锁
那么释放锁该怎么操作呢?
其实释放锁就很简单了,也就是将获取到锁的这个客户端的事务提交,这样其它客户端就可以来获取到这把行锁了,所以这时候就需要我们手动的提交事务了
代码实现
首先就是编写我们的加锁sql语句了
@select("select lock_name from lock where lock_name = #{lockname} for update")
list<string> querylocknameforupdate(@param("lockname") string lockname);
然后我们需要实现我们的加锁 和 解锁
public class mysqldistributelock {
//加锁的key,也就是我们提前存到表lock的值
private string lockname;
//手动提交事务需要的事务管理器,由外部传入
private datasourcetransactionmanager datasourcetransactionmanager;
//自定义编写的mybatis的mapper文件
private mysqllockmapper mysqllockmapper;
private transactionstatus status;
public mysqldistributelock(string lockname,datasourcetransactionmanager datasourcetransactionmanager,mysqllockmapper mysqllockmapper) {
this.lockname = lockname;
this.datasourcetransactionmanager = datasourcetransactionmanager;
this.mysqllockmapper = mysqllockmapper;
}
public void lock() {
transactiondefinition transactiondefinition = new defaulttransactiondefinition();
status = datasourcetransactionmanager.gettransaction(transactiondefinition);
while (true) {
try{
mysqllockmapper.querylocknameforupdate(this.lockname);
//如果加锁成功,就退出该循环
break;
}catch (exception e) {
//说明抛出异常了,让线程重试
try {
//让线程休眠一会
thread.sleep(100);
} catch (interruptedexception ignored) { }
}
}
}
public void unlock() {
//手动提交事务,也就是释放锁
datasourcetransactionmanager.commit(this.status);
}
}
最后看下业务方如何使用
@service
public class lockservice {
@resource
private datasourcetransactionmanager datasourcetransactionmanager;
@resource
private mysqldistributelock.mysqllockmapper mysqllockmapper;
public string deductstockmysqllock(string productid,integer count) {
mysqldistributelock lock = null;
try{
lock = new mysqldistributelock(productid,datasourcetransactionmanager,mysqllockmapper);
//加锁
lock.lock();
//加锁成功,开始执行我们自己的业务逻辑
}finally {
if(lock != null) {
lock.unlock();
}
}
return "success";
}
}
2:基于唯一索引实现分布式锁
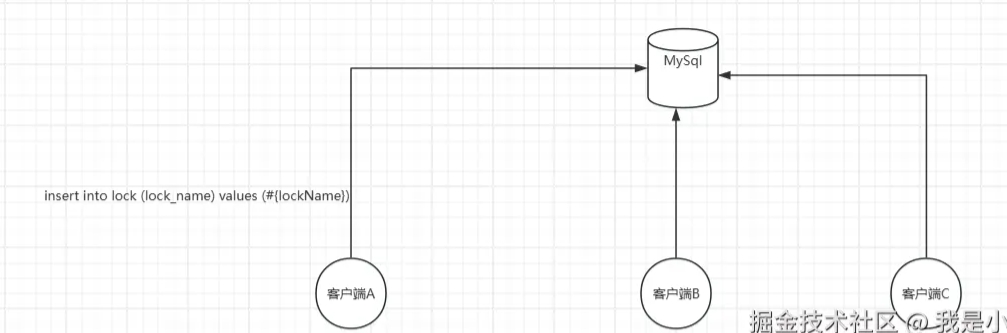
实现原理
首先我们的lock表要给lock_name字段建立一个唯一索引,这时候有多个客户端来加锁,本质上也就是添加一条记录,只不过lockname的值都是一样的
这时候客户端a成功的把lockname保存到lock表中了,那么其它客户端要保存这个lockname的时候(也就是执行加锁),由于唯一索引的缘故,就会插入失败。也就保证了同一个时间只能有一个客户端保存成功,也就是加锁成功了
那么如何释放锁呢?
在这个客户端业务执行完之后,手动的把这条记录删除掉,那么其它客户端就可以来继续加锁了
代码实现
首先我们在mapper文件中编写 加锁 和 解锁 的sql,这里为什么还要保存个uuid,后续会讲到(主要是防止锁被误删)
//加锁语句
@insert("insert into record_lock (lock_name, uuid) values (#{lockname}, #{uuid})")
integer insert(@param("lockname") string lockname, @param("uuid") string uuid);
//解锁语句
@delete("delete from record_lock where lock_name = #{lockname} and uuid = #{uuid}")
integer delete(@param("lockname") string lockname, @param("uuid") string uuid);
然后我们需要实现我们的加锁 和 解锁
public class mysqldistributelock {
private string lockname;
//自定义编写的mybatis的mapper文件
private mysqllockmapper mysqllockmapper;
private string uuid;
public mysqldistributelock(string lockname,mysqllockmapper mysqllockmapper,string uuid) {
this.lockname = lockname;
this.mysqllockmapper = mysqllockmapper;
this.uuid = uuid;
}
public void lock() {
while (true) {
try{
int result = mysqllockmapper.insert(this.lockname, this.uuid);
if(result > 0) {
//代表加锁成功
break;
}
} catch (exception e) {
}
//唯一索引加锁失败
try {
thread.sleep(100);
} catch (interruptedexception interruptedexception) {
throw new runtimeexception();
}
}
}
public void unlock() {
mysqllockmapper.delete(this.lockname,this.uuid);
}
}
最后看下业务方如何使用
@service
public class lockservice {
@resource
private mysqldistributelock.mysqllockmapper mysqllockmapper;
public string deductstockmysqllock(string productid,integer count) {
mysqldistributelock lock = null;
try{
lock = new mysqldistributelock(productid, mysqllockmapper,uuid.randomuuid().tostring());
//加锁
lock.lock();
//加锁成功,开始执行我们自己的业务逻辑
}finally {
if(lock != null) {
lock.unlock();
}
}
return "success";
}
}
基于唯一索引实现的分布式锁有没有什么问题呢??
死锁问题
我们试想一下,如果客户端a来加锁成功了,业务也执行完了,但是这时候释放锁的时候,也就是执行删除语句的时候因为一些原因导致删除失败了,那么这条记录一直存在,后续的线程就没办法再获取到锁了,这就是所谓的死锁
所以这时候我们还需要另外一个服务来定时扫描这些记录,如果这个记录超过了10分钟,或者20分钟还没有被删除掉,那么大概率是释放锁的时候失败了,所以需要再次删除这条记录
锁误删
为什么锁会误删呢? 为了防止死锁,我们会有一个单独的定时任务来扫描,假设我们判断一把锁超过10分钟就认为是释放锁失败了,这时候定时任务就会把这条记录删除掉,但是这时候就会有问题了,举个例子
客户端a首先获取到锁了,然后开始执行业务,但是因为业务比较复杂,执行完业务可能需要15分钟,这时候到第10分钟的时候,定时任务就会把这条记录给删除掉了
这时候因为记录没有了,客户端b来获取锁是能成功获取到的,所以这时候这把锁的持有者应该是客户端b的
到第15分钟的时候,客户端a业务执行完了,就是执行释放锁的逻辑,那么客户端a就会把这条记录给删除掉了,也就导致客户端a把客户端b的锁给释放掉了
所以在开头的时候,我们加锁除了要保存lockname,还要保存一个uuid,在释放锁的时候,判断一下uuid是否相等,如果不相等,那就不能删除这条记录了,因为这时候这把锁已经不是当前客户端持有的了
锁续期
大家可以想一下,分布式锁的主要目的就是同一个时间点只能有一个线程去执行业务,但是在上面我们可以看到,即使加了uuid来保证了锁误删,但是在同一个时间点可能是有多个线程在一起执行业务的,为了避免这种情况,就需要保证一个客户端在没有执行完业务以前,是不允许其它客户端执行业务的
但是定时任务判断的时间我们没办法预估,可能业务需要10分钟,也有可能是20分钟,我们没办法准确预估这个时间
所以我们在一个客户端加锁成功之后,可以起一个额外的线程,时时的更新加锁的时间,这就类似redisson的看门狗机制了,那么如何去做呢??
- 1:加锁的时候,除了保存lockname,uuid,额外保存一个加锁时间locktime
- 2:加锁成功之后,额外开启一个线程,每过10秒就更新locktime为当前时间
- 3:定时任务扫描到lcoktime距离当前时间超过10分钟或者5分钟的记录就删除掉这条记录
3:基于乐观锁实现分布式锁
基于乐观锁机制就是依靠版本机制来实现,我们一般在数据库会保存version,或者是时间戳,至于实现方式大家可以自己实现一下,这里就不做赘述了
以上就是mysql实现分布式锁详解的详细内容,更多关于mysql分布式锁的资料请关注代码网其它相关文章!




发表评论