任务背景
为提高办公效率,用python试手了一个word任务,要求如下:
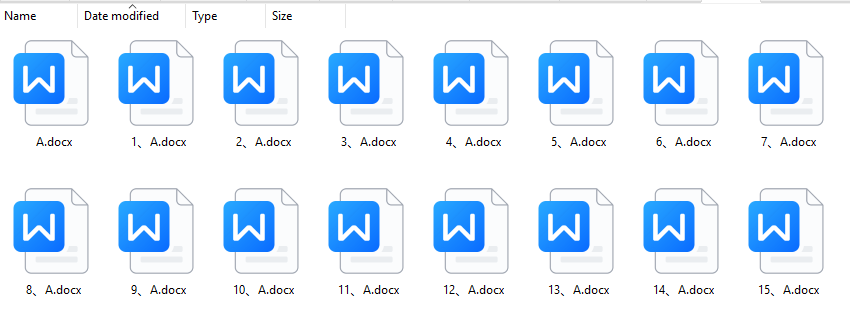
给你一个基础word文档a,格式为docx,名字为:a.docx。a文档中有表格和文字,要求是将里面的字符串"完成绘画"分别替换成完成制作款式x和复习制作款式x,输出相应副本,命名为对应序号增序文档,如:1、a.docx, 2、a.docx。
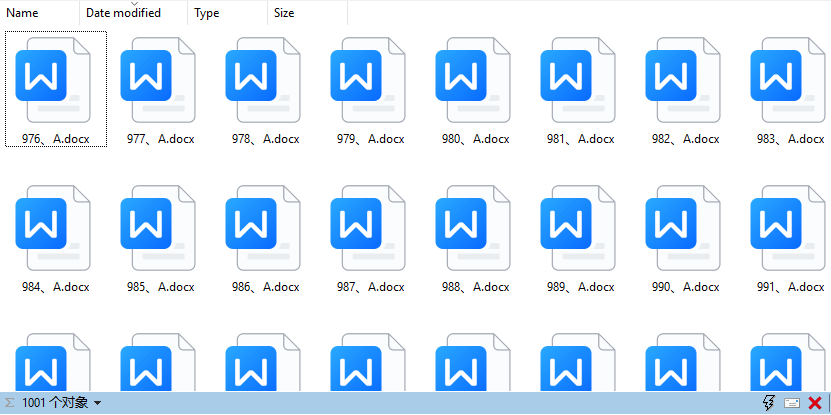
要求是输出1000份这样的增序文档。
编码思路
从问题中可提炼以下实现思路:
初始化,输入目标目录、文件命名格式、待替换源字符串、目标字符串
支持文档段落和表格内容查找,支持文本替换
文本增序和命名增序处理
效果预览:
代码实现
文件名:doc_copy_replace.py
代码如下:
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
"""
created on tue oct 29 22:20:16 2024
@author: 来知晓
"""
from docx import document
def read_ducment(old, new, document):
# 遍历文档
for paragraph in document.paragraphs:
for run in paragraph.runs:
#替换功能
if old in run.text:
run.text=run.text.replace(old,new)
# 遍历表格
for table in document.tables:
for row in table.rows:
for cell in row.cells:
#遍历表格段落内容,回到上个步骤,将cell当作paragraph处理
for paragraph in cell.paragraphs:
for run in paragraph.runs:
#替换功能
if old in cell.text:
run.text=run.text.replace(old,new)
# doc_path = r'd:\iocode\来知晓\tmp\a.docx'
# doc_new_path = r'd:\iocode\来知晓\tmp\new.docx'
# str_src = '完成绘画'
# str_tar_odd = '完成制作款式'
# str_tar_even = '复习制作款式'
# # 单样例测试
# document = document(doc_path)
# read_ducment(str_src, str_tar, document)
# document.save(doc_new_path)
# 正式demo
cnt = 1000
doc_new_dir = r'd:\iocode\来知晓\tmp'
doc_path_origin = r'd:\iocode\来知晓\tmp\a.docx'
str_src = '完成绘画'
str_tar_odd = '完成制作款式'
str_tar_even = '复习制作款式'
cnt_d2 = cnt // 2
str_split = '\\'
for i in range(cnt_d2):
k = i + 1
str_file_name = r'、a.docx'
doc_new_path_odd = doc_new_dir + str_split + str(2*k-1) + str_file_name
str_tar_odd_conca = str_tar_odd + str(k)
document_odd = document(doc_path_origin)
read_ducment(str_src, str_tar_odd_conca, document_odd)
document_odd.save(doc_new_path_odd)
doc_new_path_even = doc_new_dir + str_split + str(2*k) + str_file_name
str_tar_even_conca = str_tar_even + str(k)
document_even = document(doc_path_origin)
read_ducment(str_src, str_tar_even_conca, document_even)
document_even.save(doc_new_path_even)到此这篇关于python word实现批量替换文本并生成副本的文章就介绍到这了,更多相关python word批量替换文本内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论