1. 浏览器引擎工作原理
浏览器引擎是用来处理、渲染和显示网页内容的核心组件。其主要任务是将用户输入的url所代表的网页资源加载并呈现出来,通常包括html、css、javascript以及各种多媒体内容。浏览器引擎的工作原理可以分为以下几个主要步骤:
1.1 url解析和请求
- 当用户输入url或点击链接时,浏览器引擎会对url进行解析,并通过网络模块向服务器发送http请求。请求返回后,服务器将相应的html文档和资源(如图片、css文件)发送给浏览器。
1.2 html解析和dom树构建
- 获取html文档后,浏览器引擎将开始解析html内容,将其转换为一个dom树(文档对象模型)。dom树是一种结构化的表示方式,将网页的层次结构转变成可操作的节点树。
1.3 css解析和样式计算
- 在构建dom树的同时,浏览器引擎会解析所有与样式相关的css内容(包括内部样式表、外部css文件、以及通过javascript动态加载的样式)。
- 浏览器将css样式应用到dom树中各个节点上,生成一个称为“渲染树”的结构,用于后续的布局和绘制。
1.4 布局(layout)
- 渲染树生成后,浏览器引擎会根据节点的位置、大小及样式信息确定每个元素在屏幕上的具体位置。这个过程被称为布局(或回流),生成的是“布局树”。
1.5 绘制和渲染
- 布局树完成后,浏览器会将布局信息转化为图像,并将其绘制在屏幕上,这一过程称为“绘制”。
- 在此过程中,浏览器使用图形引擎,将网页内容渲染为像素。这通常涉及处理图像、文本、视频等多媒体内容。
1.6 javascript引擎和交互处理
- 浏览器引擎会调用javascript引擎来执行页面中的javascript代码,通常是在html解析过程中进行。javascript可以操作dom树、样式及其他页面内容,以实现动态交互。
- javascript代码可以在文档加载时执行,也可以响应用户事件(如点击、输入)进行动态操作。
1.7 渲染优化
- 为了提升用户体验,浏览器引擎会进行多种优化。例如懒加载图像、减少重排重绘(reflow和repaint)、启用缓存等,以减少网络和计算资源的消耗,提高加载速度和页面流畅度。
1.8 总结
浏览器引擎的整个过程涉及网络请求、html和css解析、dom和渲染树构建、布局、绘制、javascript执行等多个环节。这些环节紧密相连,共同作用,最终将网页内容在屏幕上展示出来并实现与用户的交互。
2. 渲染案例文件
下面提供了一个简单的html和css示例文件,将在编写的引擎中解析
2.1 示例 html (index.html)
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>simple browser example</title>
<link rel="stylesheet" href="/style.css" rel="external nofollow" >
</head>
<body>
<h1>welcome to my simple browser page</h1>
<p>this is a paragraph to demonstrate basic styling in our simple browser engine.</p>
<div class="content">
<p>this content is inside a styled div container.</p>
<p class="highlight">this paragraph has a special class applied.</p>
</div>
<a href="https://example.com" rel="external nofollow" >visit example.com</a>
</body>
</html>
2.2 示例 css (style.css)
/* 通用样式 */
body {
font-size: 14px;
color: #333333;
}
h1 {
font-size: 24px;
color: #1e90ff; /* 深蓝色标题 */
}
p {
font-size: 16px;
color: #4b0082; /* 深紫色文本 */
}
/* 特定的类和标签样式 */
.content {
padding: 10px;
border: 1px solid #888888;
margin: 10px 0;
background-color: #f0f8ff; /* 浅蓝色背景 */
}
.highlight {
color: #ff4500; /* 橙红色高亮 */
font-weight: bold;
}
a {
color: #0000ee; /* 默认蓝色链接 */
text-decoration: underline;
font-size: 16px;
}
2.3 解释
html:
- 包含一个标题
<h1>、两个段落<p>、一个带有content类名的<div>容器和一个链接<a>。 - 使用
<link rel="stylesheet">标签引入外部css文件style.css。
- 包含一个标题
css:
- 为
body、h1、p、.content(类选择器)和.highlight(类选择器)定义样式。 body定义了默认字体大小和颜色。h1设定了字体大小和颜色,p为普通段落设定了字体和颜色。.content为div容器设置了边框、填充和背景颜色。.highlight类用于突出显示特殊段落文本。a定义了链接的颜色和下划线样式,便于点击。
- 为
2.4 使用方法
将上述两个文件放在同一个目录下,在该目录下通过python搭建简易服务器
python -m http.server
3. 引擎代码
3.1 代码
首先构建dom树,然后构建一个cssom(css对象模型)树,并使用它与dom树结合,决定元素的样式和渲染效果。
以下是如何实现这个的python代码示例:
import requests
from bs4 import beautifulsoup
import tkinter as tk
import re
class simplebrowserengine:
def __init__(self, url):
self.url = url
self.html_content = ""
self.css_content = ""
self.dom_tree = none
self.cssom_tree = {}
def load_url(self):
print(f"加载url: {self.url}")
response = requests.get(self.url)
if response.status_code == 200:
self.html_content = response.text
print("页面加载成功!")
print(self.html_content)
else:
print("页面加载失败。")
# 提取和加载css
self.load_css()
def load_css(self):
print("加载css样式...")
soup = beautifulsoup(self.html_content, 'html.parser')
# 找到所有css链接
css_links = [link['href'] for link in soup.find_all('link', rel='stylesheet') if 'href' in link.attrs]
# 获取并合并所有css内容
for css_link in css_links:
if css_link.startswith("/"):
css_link = self.url + css_link
response = requests.get(css_link)
if response.status_code == 200:
self.css_content += response.text + "\n"
# 如果有内嵌css样式
style_tags = soup.find_all('style')
for tag in style_tags:
self.css_content += tag.string + "\n"
print("css加载完成!")
def parse_html(self):
print("解析html...")
self.dom_tree = beautifulsoup(self.html_content, 'html.parser')
print("dom树已构建!")
def parse_css(self):
print("解析css...")
# 解析css并构建cssom树(简单选择器)
rules = re.findall(r'([^\{]+)\{([^\}]+)\}', self.css_content)
for selector, properties in rules:
selector = selector.strip()
prop_dict = {}
for prop in properties.split(';'):
if ':' in prop:
name, value = prop.split(':')
prop_dict[name.strip()] = value.strip()
self.cssom_tree[selector] = prop_dict
print("cssom树已构建!")
def apply_styles(self, element):
# 查找应用在element的样式
style = {}
for selector, properties in self.cssom_tree.items():
if selector == element.name or (element.get('class') and selector in element.get('class')):
style.update(properties)
return style
def render(self, window):
print("开始渲染...")
# 遍历dom树,并应用cssom样式
for elem in self.dom_tree.find_all(['h1', 'h2', 'p', 'a', 'div']):
style = self.apply_styles(elem)
# 应用样式并渲染标签
font_size = int(style.get('font-size', '12').replace('px', ''))
color = style.get('color', 'black')
text = elem.get_text()
label = tk.label(window, text=text, font=("helvetica", font_size), fg=color)
# 如果是链接,显示为蓝色并添加点击事件
if elem.name == 'a':
label.config(fg="blue", cursor="hand2", font=("helvetica", font_size, "underline"))
link = elem.get('href')
label.bind("<button-1>", lambda e, link=link: self.open_link(link))
label.pack()
print("渲染完成!")
def open_link(self, link):
# 处理相对链接
if link.startswith("/"):
link = self.url + link
print(f"打开链接: {link}")
new_window = tk.tk()
new_window.title("simple browser - " + link)
new_engine = simplebrowserengine(link)
new_engine.load_url()
new_engine.parse_html()
new_engine.parse_css()
new_engine.render(new_window)
new_window.mainloop()
def start(self):
self.load_url()
self.parse_html()
self.parse_css()
window = tk.tk()
window.title("simple browser - " + self.url)
self.render(window)
window.mainloop()
# 示例:浏览 https://example.com
url = "http://127.0.0.1:8000/"
browser = simplebrowserengine(url)
browser.start()
3.2 代码解释
- css 加载:在
load_css函数中加载所有链接的css文件和页面内的<style>标签内容,并将其合并到self.css_content中。 - cssom 树构建:使用正则表达式解析css内容,构建一个简单的cssom树,将选择器和样式属性存储在
self.cssom_tree中。 - 样式应用:
apply_styles函数根据dom元素的标签名和类名找到匹配的css样式,并返回样式字典。 - 渲染标签:根据
self.cssom_tree中的样式设置字体大小和颜色,并使用tkinter在窗口中展示。<a>标签作为链接显示,支持点击打开链接。 - 启动:
start方法加载html和css内容,解析dom和cssom树,最终调用render函数在窗口中渲染页面。
3.3 安装前提
运行代码前需要安装requests和beautifulsoup4:
pip install requests beautifulsoup4
3.4 说明
- 此代码实现了一个简单的css解析和应用,可以设置基本的字体大小和颜色。
tkinter不是专业的图形引擎,因此仅能展示基础的css样式,复杂的布局和高级样式属性(如浮动、定位等)无法完整支持。
4. 其它
4.1 效果
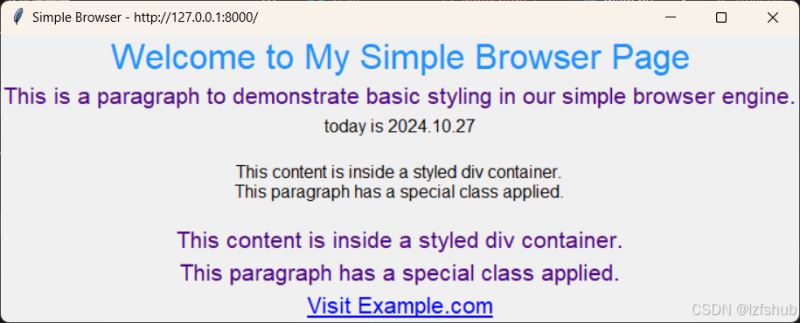
以上就是基于python实现一个简单的浏览器引擎的详细内容,更多关于python浏览器引擎的资料请关注代码网其它相关文章!





发表评论