一、聚合查询
使用聚合查询前要先从 django.db.models 引入 avg、max、min、count、sum(首字母大写)
聚合查询返回值的数据类型是字典
聚合查询使用aggregate()对查询集执行聚合操作,它允许我们使用数据库提供的聚合函数(如 count(), avg(), sum(), max(), min() 等)来对查询集中的数据进行汇总计算,aggregate() 方法返回一个字典,字典的键是你指定的聚合函数别名,值是聚合计算的结果
queryset.aggregate(聚合函数)
# 别名使用
queryset.aggregate(别名 = 聚合函数名("属性名称"))
# 例:
result = book.objects.aggregate(average_price=avg('price'), total_books=count('id'))
# 结果示例: {'average_price': 100.25, 'total_books': 150}二、使用步骤
1.准备工作
还是之前那个fa的项目目录,在views.py内引入
# 导入聚合函数 from django.db.models import avg,max,min,count,sum
在models.py里面,定义一个book模型
class book(models.model):
title = models.charfield(max_length=255) # 书名
author = models.charfield(max_length=255) # 作者
price = models.decimalfield(max_digits=10, decimal_places=2) # 价格
rating = models.floatfield() # 评分
published_date = models.datefield() # 出版日期
pages = models.integerfield() # 页数
def __str__(self):
return self.title在数据库生成book表,执行下列命令
python manage.py makemigrations python manage.py migrate
这个时候我们就有一张book的表了,我们自己手动塞入一些数据(这里就不做新增了),然后在下一步实现聚合函数的使用
随意添加的数据
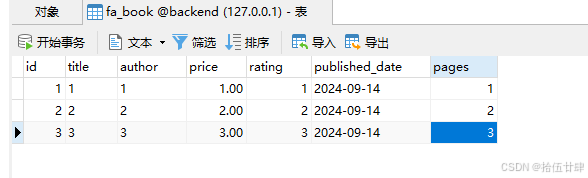
2.具体使用
定义一个方法去使用聚合函数,我们在views.py里面添加一个方法
def getbooksomeinfo(request):
# 计算书的平均价格
average_price = models.book.objects.aggregate(avg_price = avg('price'))
# 如果不加别名结果为: {'price__avg': 100.25}
# 获取书的最高价格
max_price = models.book.objects.aggregate(max('price'))
# 获取书的最低价格
min_price = models.book.objects.aggregate(min_price = min('price'))
# 统计书的总数量
# book_count = models.book.objects.aggregate(count('id'))
book_count = models.book.objects.aggregate(book_count = count('id'))
# 其实也可以使用 len(models.book.objects.all()) / models.book.objects.count()
# 计算所有书的总价格
total_price = models.book.objects.aggregate(total_price = sum('price'))
return httpresponse(f"平均价格: {average_price}, 最高价格: {max_price}, 最低价格: {min_price}, 总数量: {book_count}, 总价格: {total_price}")在路由urls.py里面添加
path('getbooksomeinfo', views.getbooksomeinfo, name='getbooksomeinfo'),访问链接http://127.0.0.1:8082/article/getbooksomeinfo

3.分组查询(annotate)
1.定义
annotate() 是 django orm 提供的一个方法,用于在查询集中为每个对象添加计算值。与 aggregate() 方法不同,annotate() 是逐个对象进行计算,而 aggregate() 是对整个查询集进行计算,并返回一个汇总结果
2.使用
使用前要先从 django.db.models 引入聚合函数,annotate() 方法接受一个或多个聚合函数作为参数,这些聚合函数会被应用到查询集中,并将结果作为额外字段添加到每个对象上
queryset.annotate(聚合函数)
3.具体案例
我们先修改一下刚刚定义的book模型,同时增加一个作者user模型
class user(models.model):
name = models.charfield(max_length=255) # 作者名称
def __str__(self):
return self.name
class book(models.model):
title = models.charfield(max_length=255) # 书名
# author = models.charfield(max_length=255) # 作者
user = models.foreignkey(user, related_name='books', null=true, on_delete=models.cascade) # 作者
price = models.decimalfield(max_digits=10, decimal_places=2) # 价格
rating = models.floatfield() # 评分
published_date = models.datefield() # 出版日期
pages = models.integerfield() # 页数
def __str__(self):
return self.title执行命令生成数据表,user表和book表都先手动写入数据,不通过程序写入数据
views.py增加方法
def getbookformuser(request):
# 计算每个作者的书籍数量
# 这里的 'books' 是 models.user 类中定义的外键名称,如果外键名称不是 'books' 则需要修改
users_with_book_count = models.user.objects.annotate(book_count = count('books'))
users_with_book_count_str = ''
# 输出每个作者的书籍数量
for user in users_with_book_count:
users_with_book_count_str += f"{user.name} has {user.book_count} books.\n"
# 计算每个作者的书籍平均价格
# books__price 代表 books 外键的 price 字段
users_with_avg_price = models.user.objects.annotate(avg_price = avg('books__price'))
users_with_avg_price_str = ''
# 输出每个作者的书籍平均价格
for user in users_with_avg_price:
users_with_avg_price_str += f"{user.name} has an average book price of {user.avg_price}.\n"
# 计算每个作者的书籍总价格和最高评分
users_with_totals = models.user.objects.annotate(total_price = sum('books__price'), highest_rating = max('books__rating'))
users_with_totals_str = ''
# 输出每个作者的书籍总价格和最高评分
for user in users_with_totals:
users_with_totals_str += f"{user.name} has a total book price of {user.total_price} and the highest rating is {user.highest_rating}.\n"
# 返回带有换行符的 html 响应,确保编码为utf-8
return httpresponse(
f"每个作者的书籍数量: <br>{users_with_book_count_str}<br>"
f"每个作者的书籍平均价格: <br>{users_with_avg_price_str}<br>"
f"每个作者的书籍总价格和最高评分: <br>{users_with_totals_str}",
content_type="text/html; charset=utf-8"
)增加路由
path('getbookformuser', views.getbookformuser, name='getbookformuser'),访问链接http://127.0.0.1:8000/article/getbookformuser

4.f() 查询
1.定义
f() 表达式用于在数据库中直接引用字段的值,而不是将值从数据库取出后再进行计算。它允许你在数据库层面进行原子性的计算操作,从而避免出现竞争条件或数据不同步的问题,常用于以下场景:
对字段值进行加减、乘除等数学运算。
比较同一个模型中不同字段的值。
更新字段时直接使用该字段的当前值。
2.使用
要使用 f() 表达式,你需要从 django.db.models 中导入 f 类
from django.db.models import f
字段值的更新(如:增加浏览数)
先更新一下book模型
class book(models.model):
title = models.charfield(max_length=255) # 书名
# author = models.charfield(max_length=255) # 作者
user = models.foreignkey(user, related_name='books', null=true, on_delete=models.cascade) # 作者
price = models.decimalfield(max_digits=10, decimal_places=2) # 价格
rating = models.floatfield() # 评分
published_date = models.datefield() # 出版日期
pages = models.integerfield() # 页数
views = models.integerfield(default=0) # 浏览量
def __str__(self):
return self.title定义方法和路由
def addviews(request):
# 增加阅读量
article_id = 1
models.book.objects.filter(id=article_id).update(views=f('views') + 1)
return httpresponse('views added successfully')
path('addviews', views.addviews, name='addviews'),访问链接http://127.0.0.1:8000/article/addviews
一些其他场景
定义方法和路由
def someotherinfo(request):
# 比较同一个模型的两个字段的值
# 获取 price 大于 discount_price 的商品,这个查询会返回所有 price 大于 discount_price 的 product 实例
# 注意:f() 函数用于引用其他字段的值,不能用于直接比较两个字段的值,price和views都是字段名
book_gt_discount = models.book.objects.filter(price__gt=f('views'))
book_gt_discount_str = ''
for item in book_gt_discount:
book_gt_discount_str += f"book {item.id} has a price of {item.price} and views of {item.views}\n"
# 多字段运算
# 获取所有books的总价格和评分的乘积
# 使用 f() 表达式在 annotate 中
books = models.book.objects.annotate(total_price=f('price') * f('views'))
str_books = ''
for item in books:
str_books += f"book {item.id} has total price {item.total_price}\n"
# 查询时对字段进行运算
# 获取book的价格大于其views加500的书籍
high_books = models.book.objects.filter(price__gt=f('views') + 500.00)
high_books_str = ''
for item in high_books:
high_books_str += f"book {item.id} has a price of {item.price}\n"
return httpresponse(
f"book_gt_discount: <br>{book_gt_discount_str}<br>"
f"str_books: <br>{str_books}<br>"
f"high_books_str: <br>{high_books_str}",
content_type="text/html; charset=utf-8"
)
path('someotherinfo', views.someotherinfo, name='someotherinfo'),访问链接http://127.0.0.1:8000/article/someotherinfo
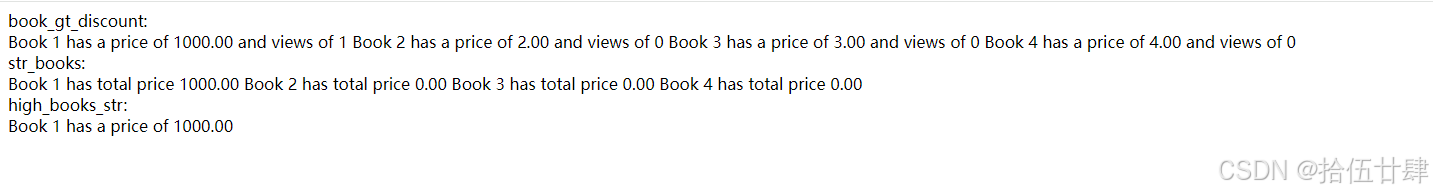
5.q() 查询
1.定义
q() 对象来自 django.db.models,用于创建复杂的查询条件。你可以使用它来结合多个条件,执行与(and)或或(or)操作,甚至是非(not)操作,尤其是在需要执行“or”操作或者需要多个条件组合时非常有用。q() 对象使得构建复杂的查询变得更加灵活和强大,
使用前还是先导入
from django.db.models import q
2.查询
定义方法和路由
def searchbyq(request):
# 按价格和阅读量查询书籍
# 注意:q() 函数用于构建复杂的查询条件,可以与其他条件组合使用
# 这里的 q() 函数与 price__gt 条件组合使用,表示价格大于 500.00
# 与 views__gt 条件组合使用,表示阅读量大于 1
books_and = models.book.objects.filter(q(price__gt=500.00) & q(views__gt=1))
books_and_str = ''
for item in books_and:
books_and_str += f"book {item.id} has a price of {item.price} and views of {item.views}\n"
# 按价格或阅读量查询书籍
# 这里的 q() 函数与 price__gt 条件组合使用,表示价格大于 500.00
# 与 views__gt 条件组合使用,表示阅读量大于 1
books_or = models.book.objects.filter(q(price__gt=500.00) | q(views__gt=1))
books_or_str = ''
for item in books_or:
books_or_str += f"book {item.id} has a price of {item.price} and views of {item.views}\n"
# 按价格范围查询书籍
# 这里的 q() 函数与 price__range 条件组合使用,表示价格在 500.00 到 1000.00 之间
books_range = models.book.objects.filter(q(price__range=(500.00, 1000.00)))
books_range_str = ''
for item in books_range:
books_range_str += f"book {item.id} has a price of {item.price}\n"
# not 查询 这里使用的 ~q() 函数表示价格不大于 500.00
books_not = models.book.objects.filter(~q(price__gt=500.00))
books_not_str = ''
for item in books_not:
books_not_str += f"book {item.id} has a price of {item.price}\n"
return httpresponse(
f"books_and_str: <br>{books_and_str}<br>"
f"books_or_str: <br>{books_or_str}<br>"
f"books_range_str: <br>{books_range_str}"
f"books_not_str: <br>{books_not_str}",
content_type="text/html; charset=utf-8"
)
path('searchbyq', views.searchbyq, name='searchbyq'),访问链接http://127.0.0.1:8000/article/searchbyq

到此这篇关于django 聚合查询的文章就介绍到这了,更多相关django 聚合查询内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论