pandas空数据处理
数据清洗是对一些没有用的数据进行处理的过程。
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理。
数据准备
import pandas as pd data = pd.read_csv(r'../input/pandas/property-data.csv') data
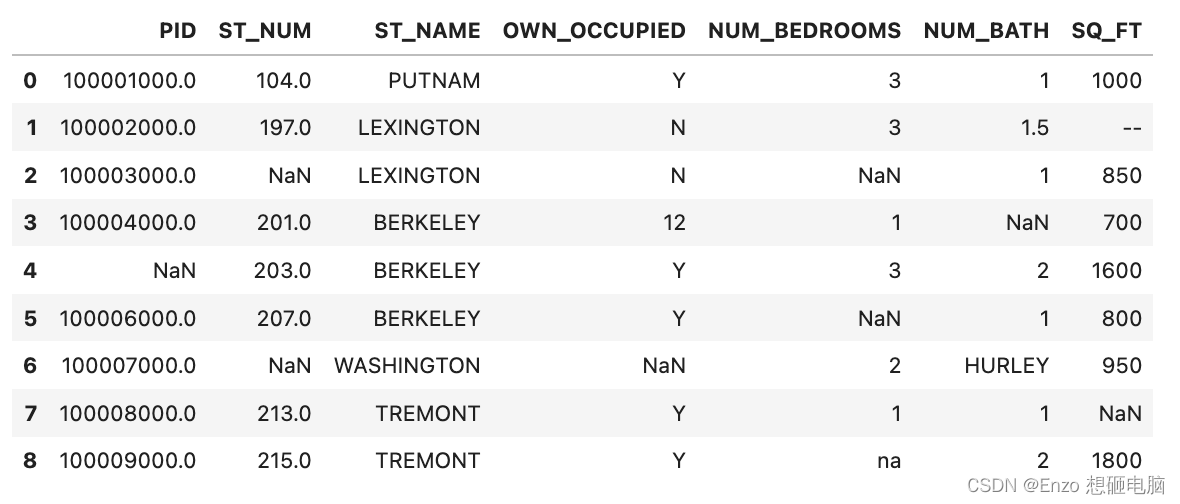
1、判断空值 .isna()
data.isna()
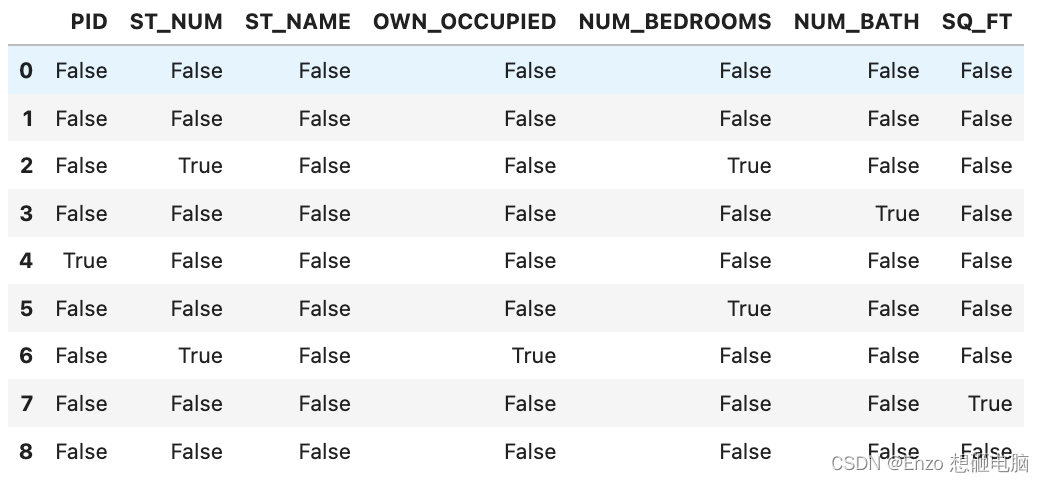
对比可以看出:pandas 把 nan 当作空数据,na 和 – 不是空数据
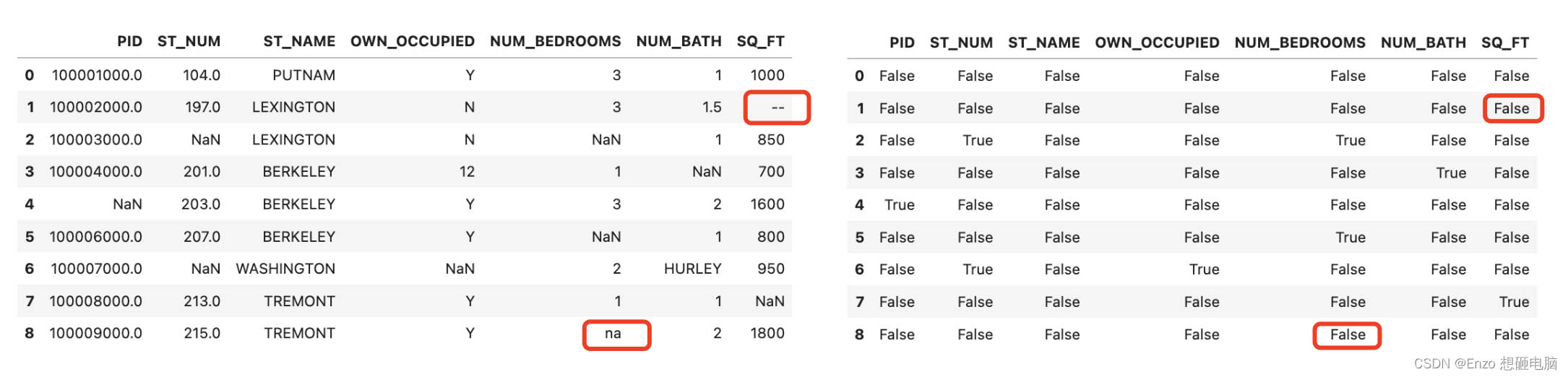
我们可以在读取数据的时候,指定哪些属于空数据
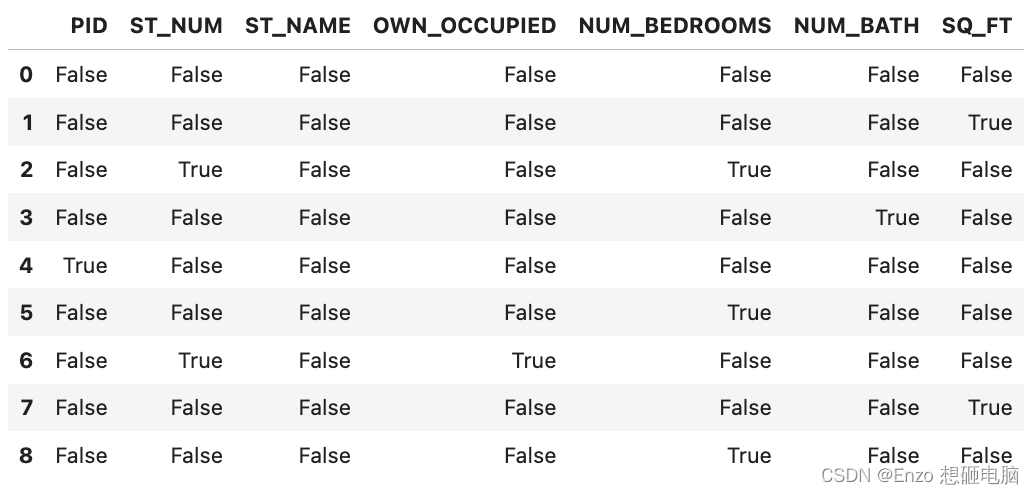
data = pd.read_csv('../input/pandas/property-data.csv', na_values = ["nan", "na", "--"])
data.isna()
# 统计每个特征的空值的数量,再按照空值数量降序排列 data.isna().sum().sort_values(ascending=false)

2、空值删除 .dropna()
如果我们要删除包含空字段的行,可以使用 dropna() 方法,语法格式如下
dataframe.dropna(axis=0, how='any', thresh=none, subset=none, inplace=false)
参数说明:
axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。how:默认为 ‘any’ ,如果一行(或一列)里任何一个数据有出现 na 就去掉整行,如果设置 how=‘all’ , 一行(或列)都是 na 才去掉这整行。thresh:设置需要多少非空值的数据才可以保留下来的。subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。inplace:如果设置 true,将计算得到的值直接覆盖之前的值并返回 none,修改的是源数据。
假设我们要删掉 ‘st_num’ 和 ‘num_bedrooms’ 中有空值的行, 并且直接在原数据里面删 ( inplace=true )
data.dropna(subset=['st_num', 'num_bedrooms'], inplace=true) data
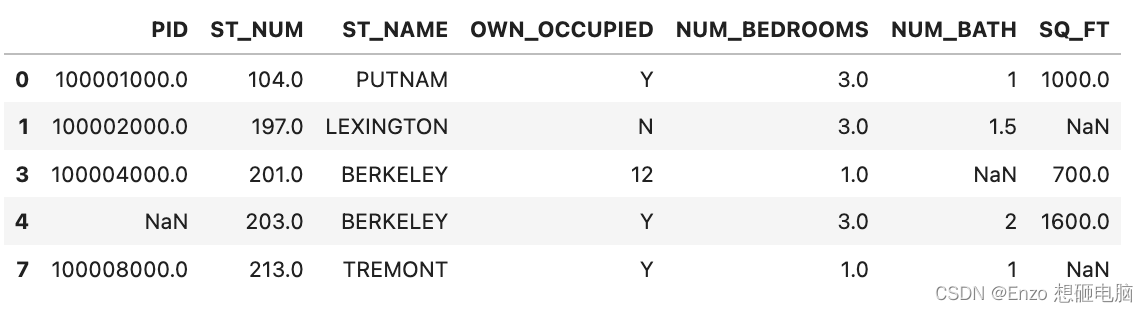
3、空值替换 .dropna()
data['num_bedrooms'].fillna('0.0', inplace = true)
data
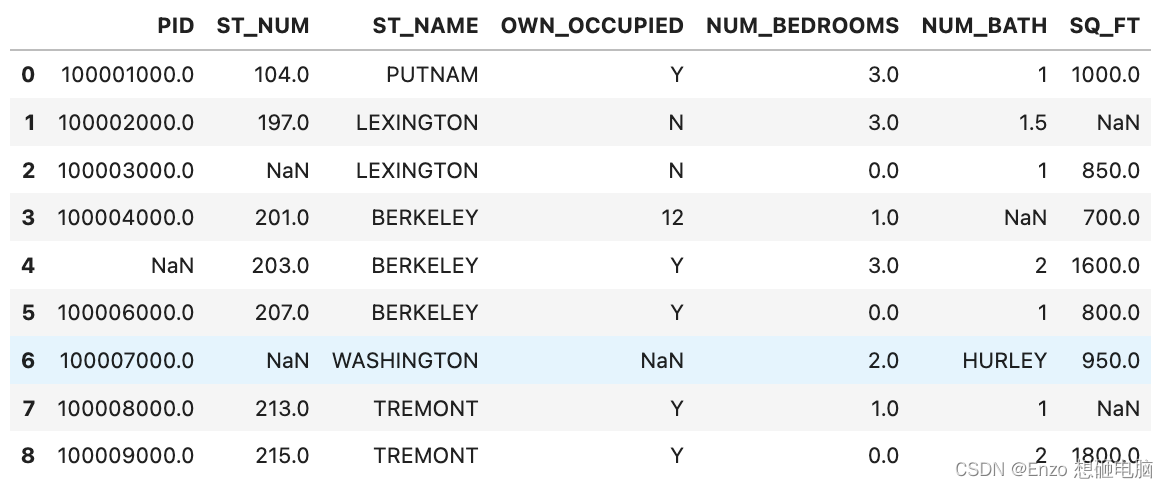
除了直接指定常数替换,常用的替换空单元格的方法是计算列的均值(mean:所有值加起来的平均值)、中位数值(median 排序后排在中间的数)或众数(mode 出现频率最高的数)。
1) 用平均值填充
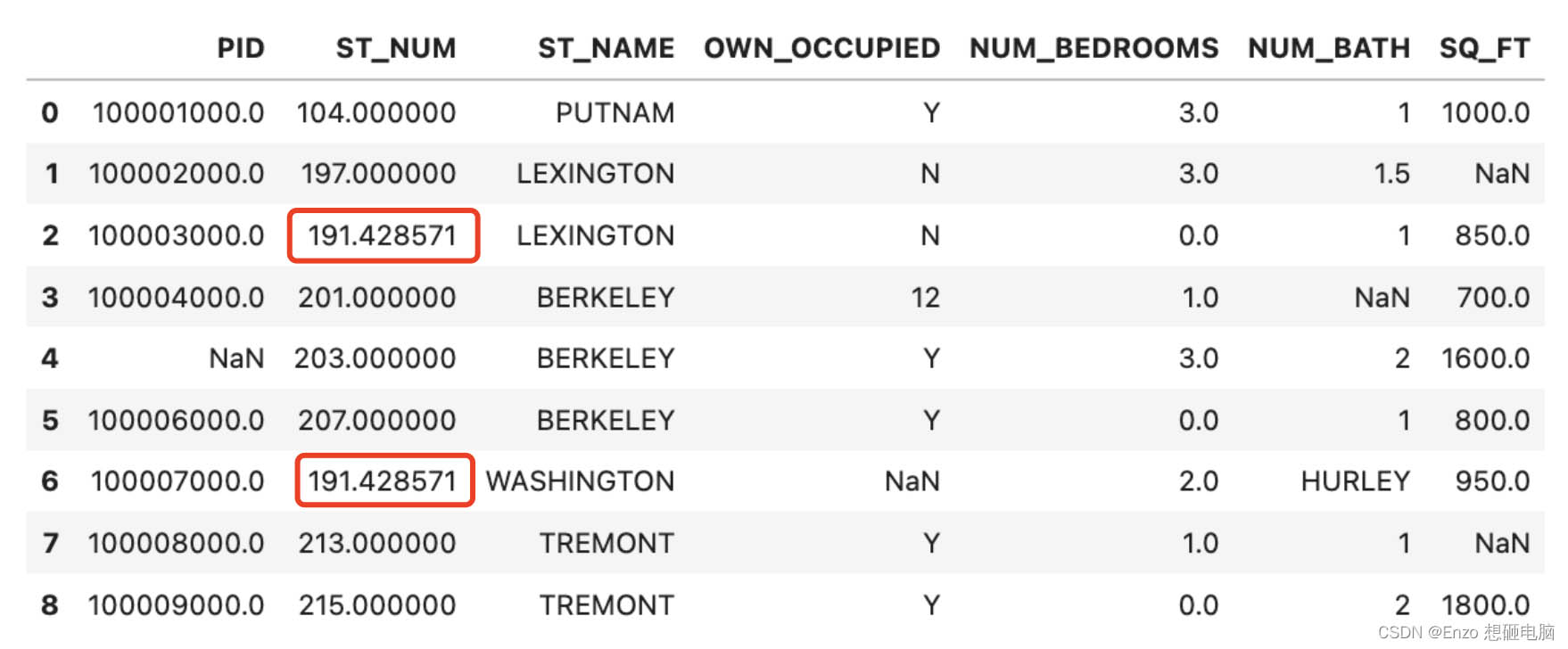
x = data["st_num"].mean() data["st_num"].fillna(x, inplace = true) data
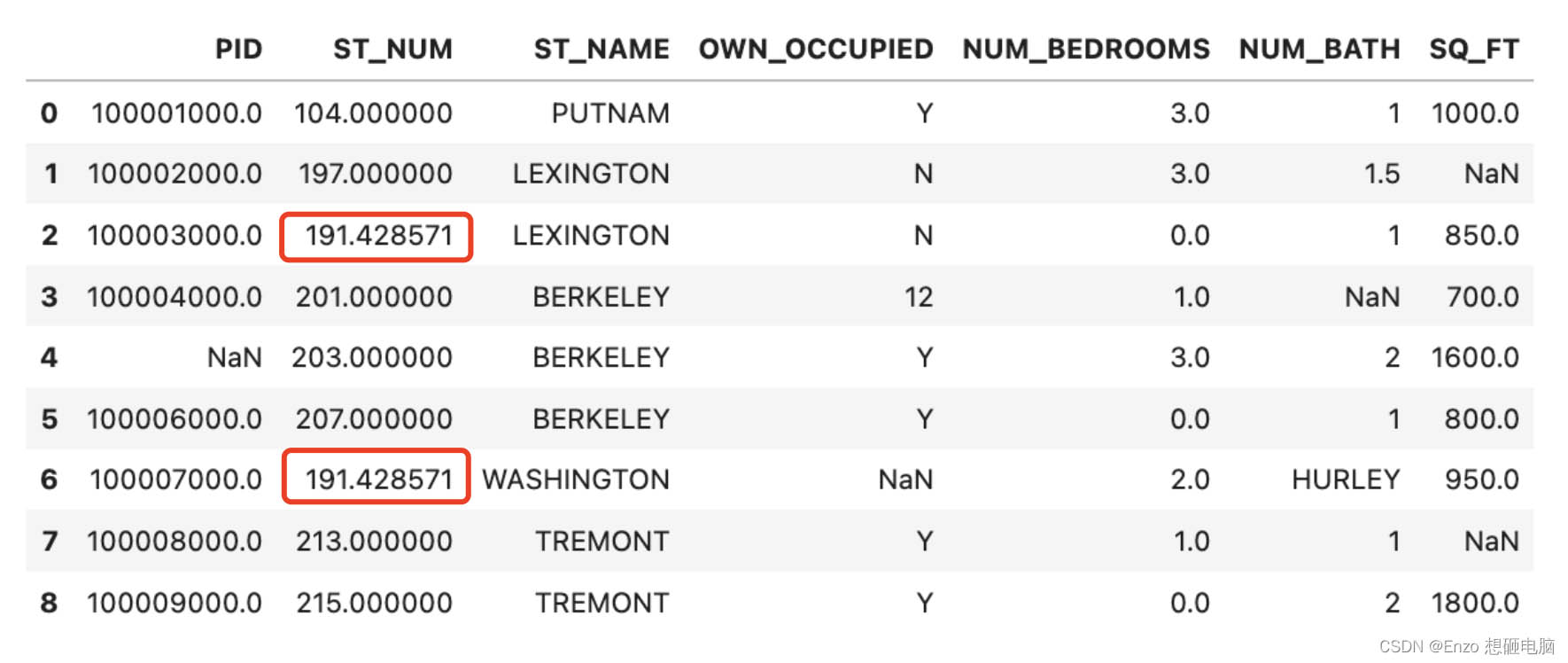
2) 用中位数填充
```python x = data["st_num"].median() data["st_num"].fillna(x, inplace = true) data
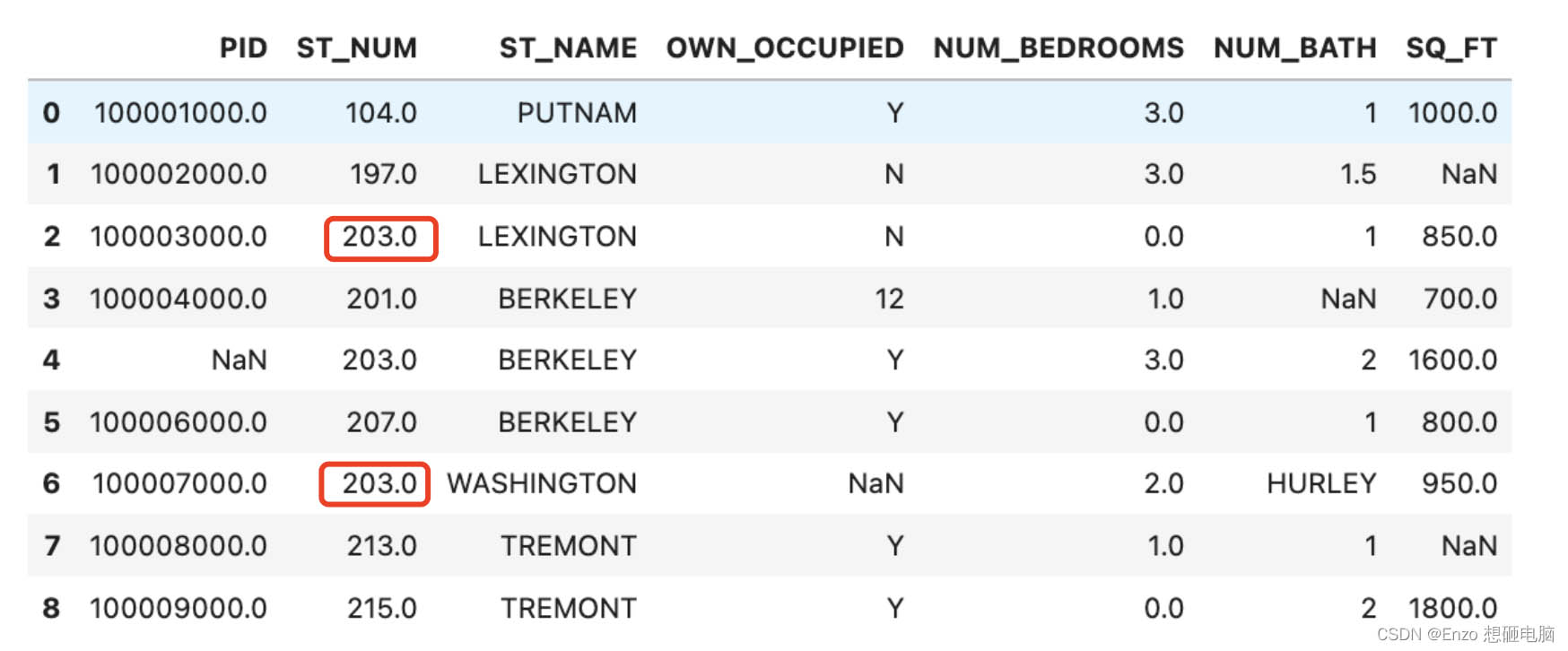
3) 用众数填充
x = data["st_num"].mode() data["st_num"].fillna(x, inplace = true) data
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论