pandas.dataframe.rank
dataframe.rank(axis=0, method=‘average', numeric_only=nodefault.no_default, na_option=‘keep', ascending=true, pct=false)
参数解释
- axis: axis=0为按行排名,axis=1为按列排名
- method: 如何对具有相同价值(即领带)的记录组进行排序:
- numeric_only: 对于dataframe对象,如果设置为true,则只对数字列排序。
- na_option: 如何对nan值进行排序:
- ascending: 元素按升序/降序排列
- pct: 是否以百分比形式显示返回的排名。
example:
df = pd.dataframe(data={'animal': ['cat', 'penguin', 'dog',
'spider', 'snake'],
'number_legs': [4, 2, 4, 8, np.nan]})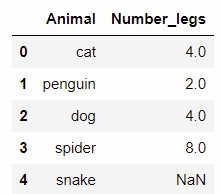
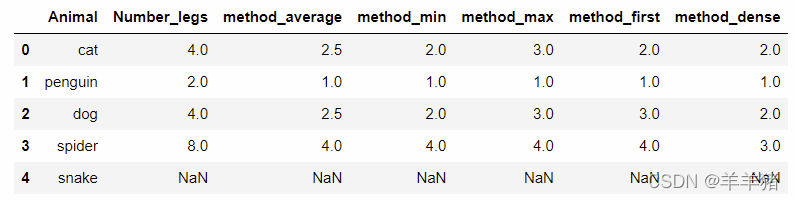
method: {‘average', ‘min', ‘max', ‘first', ‘dense'}, default ‘average'- average: 组里的平均排名
- min: 组里的最低排名
- max: 组里的最高排名
- first: 按照他们在数组中出现的顺序排列
- dense: 就像’ min '一样,但是在组之间rank总是增加1。
df['method_average'] = df['number_legs'].rank(method='average') df['method_min'] = df['number_legs'].rank(method='min') df['method_max'] = df['number_legs'].rank(method='max') df['method_first'] = df['number_legs'].rank(method='first') df['method_dense'] = df['number_legs'].rank(method='dense')
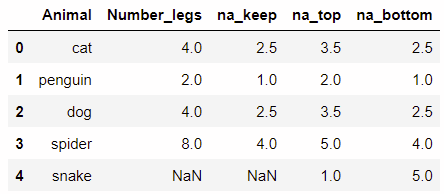
na_option: {‘keep', ‘top', ‘bottom'}, default ‘keep'- keep: 空值排序仍为空值
- top: 排序放在第一位
- bottom: 排在最后一位
df['na_keep'] = df['number_legs'].rank(na_option='keep') df['na_top'] = df['number_legs'].rank(na_option='top') df['na_bottom'] = df['number_legs'].rank(na_option='bottom')
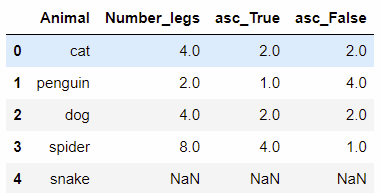
ascending: 升序为true, 降序为false
df['asc_true'] = df['number_legs'].rank(method='min', ascending=true) df['asc_false'] = df['number_legs'].rank(method='min', ascending=false)
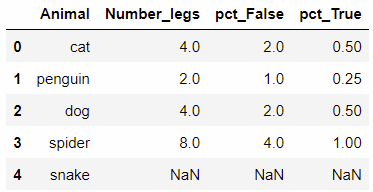
pct: 是否显示百分比
df['pct_true'] = df['number_legs'].rank(method='min', pct=true) df['pct_false'] = df['number_legs'].rank(method='min', pct=false)
分组排序
pandas.core.groupby.groupby.rank 官方文档
example:
df = pd.dataframe(
{"group": ["a", "a", "a", "a", "a", "b", "b", "b", "b", "b"],
"value": [2, 4, 2, 3, 5, 1, 2, 4, 1, 5],}
)
for method in ['average', 'min', 'max', 'dense', 'first']:
df[f'{method}_rank'] = df.groupby('group')['value'].rank(method)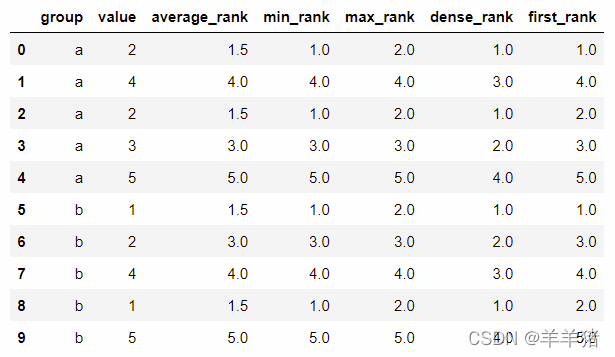
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论