一、复制概述
mysql的复制就是将来自一个mysql数据库服务器(主库)的数据复制到一个或多个mysql数据库服务器(从库)。其工作原理是通过binlog(二进制日志)记录事务变更然后传送到从库并重放事务,保持数据一致。
复制的主要步骤如下:
- 主库事务提交,mysql将事务变更记录到binlog。
- 主库上日志转储线程(binlog dump)将日志传递给从库i/o线程。
- 从库i/o线程将日志中的事件记录到本地的中继日志中(relay log)。
- 从库sql线程从中继日志中读取事务,应用变更,保持数据和主库一致。
示意图:
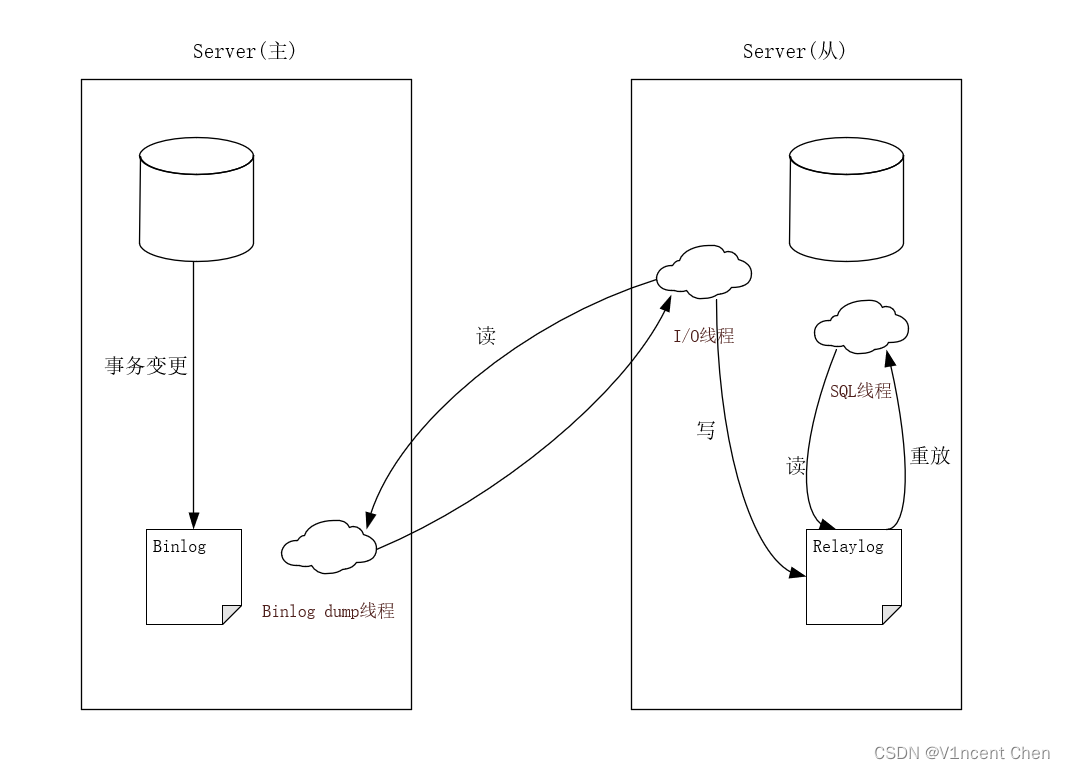
如果binlog dump线程追赶上了主库,它将进入睡眠状态,直到主库发送信号量通知其有新的事件产生时才会被唤醒,备库i/o线程会将接收到的事件记录到中继日志中。
使用复制可以带来如下好处:
- 复制可以将读操作分布到多个服务器上,对读密集型业务有更好的承载能力。
- 由于读的压力分离至从库,主库可以分配更多的资源来响应写请求。
- 提高安全,可以利用延迟复制等特性,快速恢复主库上的误操作。
- 高可用,复制+故障切换系统,可以让系统宕机时快速恢复,响应请求。
二、二进制日志格式
二进制日志在记录事务变更时有statement、row、mixed三种格式,通过binlog_format系统变量来设置:
statement
基于sql语句的复制(statement-based replication,sbr),将修改数据的sql语句都会被记录到binlog中,优点是不需要记录每行的数据变化,这样二进制日志会比较少。缺点是在某些情况下不能很好工作,例如last_insert_id()、now()等非确定性函数,以及用户自定义函数(user-defined function,udf)、存储过程、触发器时也易出问题。
- row(推荐,也是mysql8默认的日志格式)
基于行的复制(row-based replication,rbr)。该格式不记录sql语句,仅记录哪条数据被修改了,修改成了什么样子,能清楚地记录每一行数据的修改前后细节。优点是不会出现某些特定情况下的存储过程、函数或触发器的调用和触发无法被正确复制的问题。缺点是通常会产生大量的日志。
mixed
混合复制(mixed-based replication,mbr)。它是statement和row这两种格式的混合体,默认使用statement格式保存二进制日志,对于statement格式无法正确复制的操作,会自动切换到基于row格式的复制操作,mysql会根据执行的sql语句选择日志保存方式。
二进制日志除了复制还会在数据库故障崩溃时进行恢复使用,因此建议将二进制日志和数据文件保存在不同的磁盘,减少i/o争用。三种日志格式中,理论上基于行的复制(row)更优,因为几乎没有基于行的复制模式无法处理的场景。对于所有的sql构造、触发器、存储过程等都能正确执行,这也是mysql8默认的日志格式。
三、复制的配置
mysql最基本的复制是单路、异步、基于日志位置的复制。其架构是1台主库,1台或多台从库通过指定日志文件及位置连接到主库。
现有2台数据库环境如下,示例基本异步复制的配置步骤:
- 192.168.3.71(主库 主机名master)
- 192.168.3.72(从库 主机名slave01)
3.1 配置主库
为主库配置唯一的server_id并打开二进制日志,配置数据库配置文件(redhat/centos默认是/etc/my.cnf)在[mysqld]选项下加入下列参数:
[mysqld] server_id=71 log_bin = bin-log sync_binlog = 1 innodb_flush_log_at_trx_commit =1
其中server_id和log_bin参数是必选,其他参数是可选项,根据自身需要选择:
- server_id需要在整个复制拓扑中保持唯一,一种通用的建议是采用ip地址的后8位,只要遵循某种规则保持唯一即可。
- log_bin用于打开二进制日志并明确指定日志名称,默认日志采用主机名命名,建议明确指定日志名,否则后期主机更名容易带来问题。
- sync_binlog(强烈推荐)保证每次提交事务会将binlog同步到磁盘,保证服务器崩溃时不丢失事务,还可以防止主从不一致。
- innodb_flush_log_at_trx_commit 保证每次提交事务innodb将日志写入redo log,只针对innodb表。
3.2 配置从库
修改从库的配置参数,必要时重启服务器。在[mysqld]选项下加入下列参数:
server_id = 72 relay_log = relay-bin log_bin = bin-log log_slave_updates = 1 read_only = 1 skip_slave_start = 1
上面的配置只有server_id=72是必须的,其他都是可选项,自己可以根据需要选择:
- relay_log用于指定中继日志名称以避免主机更名带来的问题。
- log_bin和log_slave_update用来控制slave在复制时同时也将事件写入自己的二进制日志(级联复制使用)。
- read_only=1备库建议开启,用来防止普通用户修改数据,但具有super权限的用户依然是可以修改的。
- skip_slave_start阻止备库启动时自动开启复制,如果备库在崩溃后处于不一致的状态下自动启动复制,可能会导致更多的损坏。
3.3 创建复制专用用户
在主库上创建用户并赋予replication slave权限:
create user 'repuser'@'192.168.3.%' identified by 'repp@ssword'; grant replication slave on *.* to 'repuser'@'192.168.3.%';

3.4 同步数据
大部分情况下主库都是都不是空的,这就需要在开启复制前获取主库的快照并还原到从库,保证复制开始时数据一致。主要方法有3种:
- 直接复制数据文件(需要关闭主库暂停业务)
- 使用mysqldump工具转储(便捷、但数据量大时速度较慢)
- 使用xtrabackup等第三方工具转储(便捷、速度较快)
第一种方法由于需要关库,意味着业务要生产业务要暂停,通常不会采用。第二种采用mysqldump转储,适合数据量中等的情况。如果不能关库,采用mysqldump转储又太慢,可以试着采用第三方工具xtrabackup,由于是采用物理层面的数据文件备份,所以速度比mysqldump快很多。
下面示例采用mysqldump转储的方式,在主库开启一个会话执行下面语句:
flush tables with read lock; show master status;
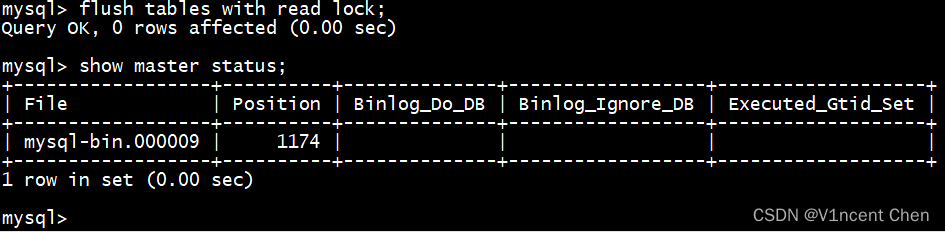
第一句会阻止所有的数据库变更,第二句显示当前的日志名称和位置,记录下来,这个就是复制的起点。
此时,另开一个会话获取数据快照,注意备份时第一个执行flush table with read lock的会话不能退出,否则可能会发生数据变更。
mysqldump --all-databases --master-data > dbdump.sql

导出之后第一个会话就可以退出了,或者执行unlock tables,让主库继续执行业务。
将上述转储文件传输到备库并导入:
scp dbdump.sql root@'192.168.3.72':/root
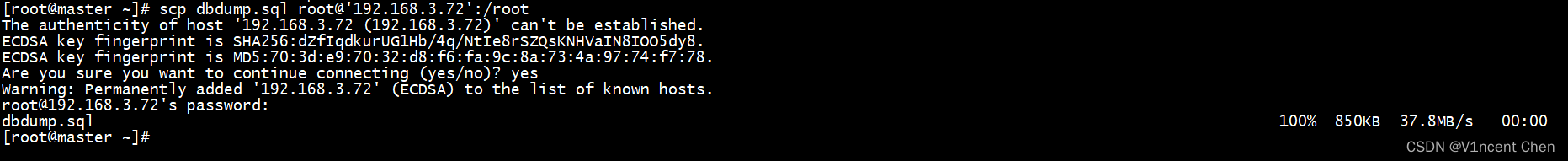
登录到备库上还原数据,此时主备库的数据已经相同,可以启动复制了:
mysql < dbdump.sql

3.5 将从库指向主库并启动复制:
在从库上执行change master to(8.0.23版本以上使用change replication source to),指定主库位置及我们在第三步建立的复制用户:
change master to master_host = '192.168.3.71', master_user='repuser', master_password='repp@ssword', master_log_file='mysql-bin.000009', master_log_pos=1174;
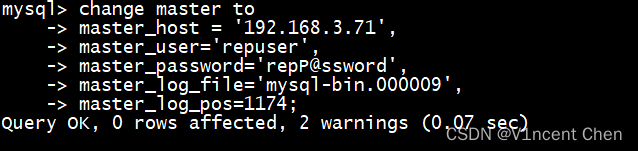
最后两句master_log_file,master_log_pos就是上一步主库show master status显示的日志名和偏移量,由于我们在转储时加了--master-data选项,所以备份文件中自动会带上这个坐标,不加也可以。
启动复制:
start slave; show slave status \g;
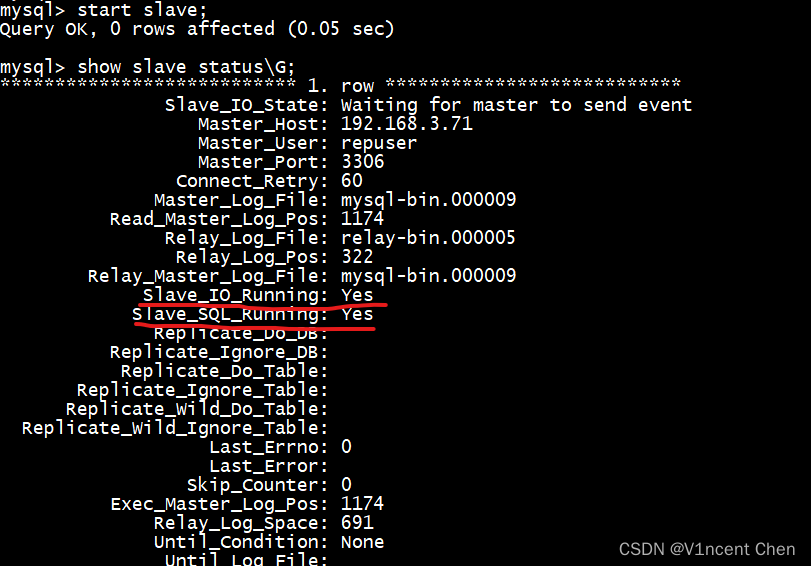
start slave 语句会启动从库上的i/o线程和sql线程,并且连接到主库(主库上启动binlog dump线程)。
show slave status,我们可以看到备库的i/o和sql线程都已经起来了,slave_io_state显示正在等待主库发送更多的事件。mysql的基础异步复制就完成了。
到此这篇关于mysql实现异步复制的示例的文章就介绍到这了,更多相关mysql 异步复制内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论