前言
mysql中,字符集和排序规则在处理文本数据时起着至关重要的作用,本文将详细介绍 mysql中的字符集和排序规则。
简介
字符集(character set):
- 字符集定义了数据库中可以存储的字符的集合。在mysql中,常见的字符集包括utf8、utf8mb4、latin1等。
- utf8mb4字符集是用于在mysql中存储unicode字符集(包括emoji等特殊字符)的一种字符集,提供更广泛的字符支持。
排序规则(collation):
- 排序规则定义了如何对字符进行比较和排序。不同的排序规则会影响字符比较的结果。
- 排序规则由字符集和排序方式组成,例如utf8_general_ci、utf8mb4_unicode_ci等。
字符集
常见字符集 以及 说明
- utf8:
utf-8 是一种变长字符编码,可以表示世界上几乎所有的字符。utf8是mysql中常用的字符集,但在处理某些特殊字符(如 emoji)时可能会有问题。
- utf8mb4:
utf8mb4 是 utf8 的超集,支持存储更广泛的字符范围(包括 emoji 等)。通常用于支持更广泛的语言和符号。
- latin1:
latin1 是一种较老的字符集,适用于大多数西欧语言和部分其他语言的字符。
- latin2:
latin2 是扩展的 latin1 字符集,支持中东欧语言中的额外字符。
- cp1251:
cp1251 是常用于俄语的字符集。
- utf16:
utf-16 是一种固定长度字符编码,用于表示 unicode 字符。每个字符占两个字节。
- utf32:
utf-32 是一种固定长度字符编码,用于表示 unicode 字符。每个字符占四个字节。
- binary:
binary 字符集以二进制方式存储数据,并且对存储的数据进行大小写敏感的比较。
- ascii:
ascii 字符集只支持 ascii 字符集中的字符,范围较窄。
大多数选择 utf8mb4 字符集 同时也支持表情存储
排序规则
常见的排序规则
以字符集 utf8mb4 为例
- utf8mb4_bin:这是一个大小写敏感的二进制排序规则,直接根据字符的二进制值进行比较,区分大小写。
- utf8mb4_croatian_ci:克罗地亚语的大小写不敏感排序规则,适用于克罗地亚语文本的比较和排序。
- utf8mb4_czech_ci:捷克语的大小写不敏感排序规则,适用于捷克语文本的比较和排序。
- utf8mb4_danish_ci:丹麦语的大小写不敏感排序规则,适用于丹麦语文本的比较和排序。
- utf8mb4_esperanto_ci:世界语的大小写不敏感排序规则,适用于世界语文本的比较和排序。
- utf8mb4_estonian_ci:爱沙尼亚语的大小写不敏感排序规则,适用于爱沙尼亚语文本的比较和排序。
- utf8mb4_general_ci:这是一个通用的大小写不敏感排序规则,适用于大多数情况下的文本比较和排序。
- utf8mb4_german2_ci:德语的大小写不敏感排序规则,适用于德语文本的比较和排序。
- utf8mb4_hungarian_ci:匈牙利语的大小写不敏感排序规则,适用于匈牙利语文本的比较和排序。
- utf8mb4_icelandic_ci:冰岛语的大小写不敏感排序规则,适用于冰岛语文本的比较和排序。
- utf8mb4_latvian_ci:拉脱维亚语的大小写不敏感排序规则,适用于拉脱维亚语文本的比较和排序。
- utf8mb4_lithuanian_ci:立陶宛语的大小写不敏感排序规则,适用于立陶宛语文本的比较和排序。
- utf8mb4_persian_ci:波斯语的大小写不敏感排序规则,适用于波斯语文本的比较和排序。
- utf8mb4_polish_ci:波兰语的大小写不敏感排序规则,适用于波兰语文本的比较和排序。
- utf8mb4_roman_ci:罗马尼亚语的大小写不敏感排序规则,适用于罗马尼亚语文本的比较和排序。
- utf8mb4_romanian_ci:罗马尼亚语的大小写不敏感排序规则,适用于罗马尼亚语文本的比较和排序。
- utf8mb4_sinhala_ci:僧伽罗语的大小写不敏感排序规则,适用于僧伽罗语文本的比较和排序。
- utf8mb4_slovak_ci:斯洛伐克语的大小写不敏感排序规则,适用于斯洛伐克语文本的比较和排序。
- utf8mb4_slovenian_ci:斯洛文尼亚语的大小写不敏感排序规则,适用于斯洛文尼亚语文本的比较和排序。
- utf8mb4_spanish2_ci:西班牙语的大小写不敏感排序规则,适用于西班牙语文本的比较和排序。
- utf8mb4_spanish_ci:西班牙语的大小写不敏感排序规则,适用于西班牙语文本的比较和排序。
- utf8mb4_swedish_ci:瑞典语的大小写不敏感排序规则,适用于瑞典语文本的比较和排序。
- utf8mb4_turkish_ci:土耳其语的大小写不敏感排序规则,适用于土耳其语文本的比较和排序。
- utf8mb4_unicode_520_ci:unicode 5.20版本的大小写不敏感排序规则,适用于支持 unicode 5.20字符集的文本比较和排序。
- utf8mb4_unicode_ci:unicode的大小写不敏感排序规则,适用于支持unicode字符集的文本比较和排序。
- utf8mb4_vietnamese_ci:越南语的大小写不敏感排序规则,适用于越南语文本的比较和排序。
比较常用的应该就是以下4个
- utf8mb4_general_ci: 不区分大小写,一般用于一般文本比较,适合非敏感数据。
- utf8mb4_unicode_ci: 不区分大小写,支持多语言,适合需要多语言支持的应用。
- utf8mb4_bin: 区分大小写,按照二进制顺序比较,适合敏感数据比较。
选择排序规则的考虑因素:
- 大小写敏感性:
_ci(case insensitive):不区分大小写。
_cs(case sensitive):区分大小写。 选择对大小写敏感的排序规则,如utf8mb4_bin。
- 多语言支持:
_unicode_ci:提供对多语言的支持,适用于需要处理不同语言字符的场景。
- 排序方式:
_ci(case insensitive):按照不区分大小写的方式进行排序。
_bin(binary):按照二进制方式进行排序,严格按照字符的编码值进行比较。
- 性能考虑:
不同排序规则对性能有影响,一些排序规则可能比其他规则更快。
选择合适的排序规则有助于优化查询性能。
实践
我们来测试下 区分大小写和不区分大小写的排序规则 查询有何不同
新建表
新建bs表 同时 name 排序规则设置为utf8mb4_general_ci 大小写不敏感
create table `bs` ( `id` bigint(20) not null auto_increment, `name` varchar(255) character set utf8mb4 collate utf8mb4_general_ci not null, primary key (`id`) ) engine=innodb auto_increment=3 default charset=utf8mb4
测试数据写入
insert into `test`.`bs` (`id`,`name`) values ('1','a');
insert into `test`.`bs` (`id`,`name`) values ('2','a');
insert into `test`.`bs` (`id`,`name`) values ('3','aa');
insert into `test`.`bs` (`id`,`name`) values ('4','aa');
insert into `test`.`bs` (`id`,`name`) values ('5','aa');
insert into `test`.`bs` (`id`,`name`) values ('6','aa');排序规则 不区分大小写 数据测试
select * from bs where name= 'a';
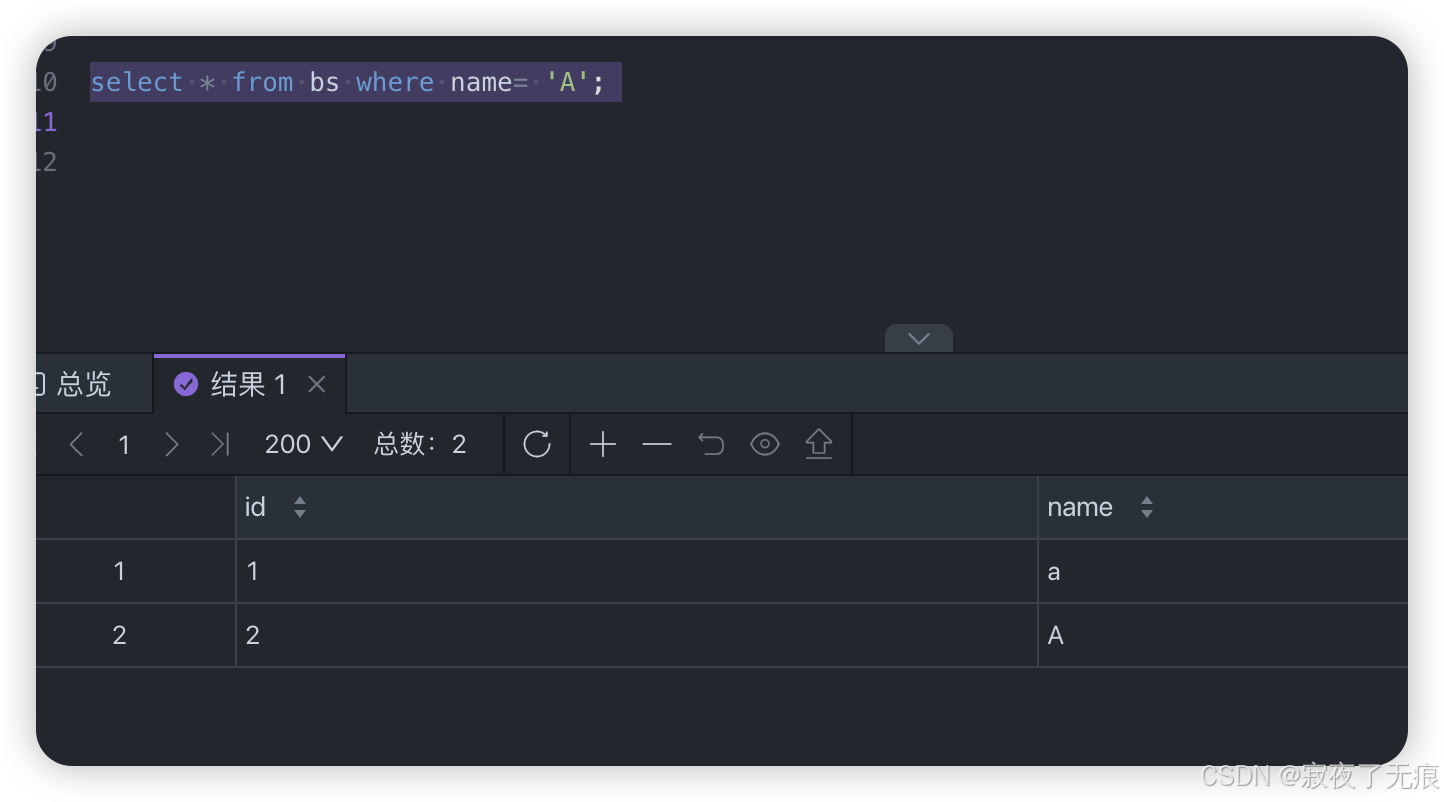
select * from bs where name= 'a';
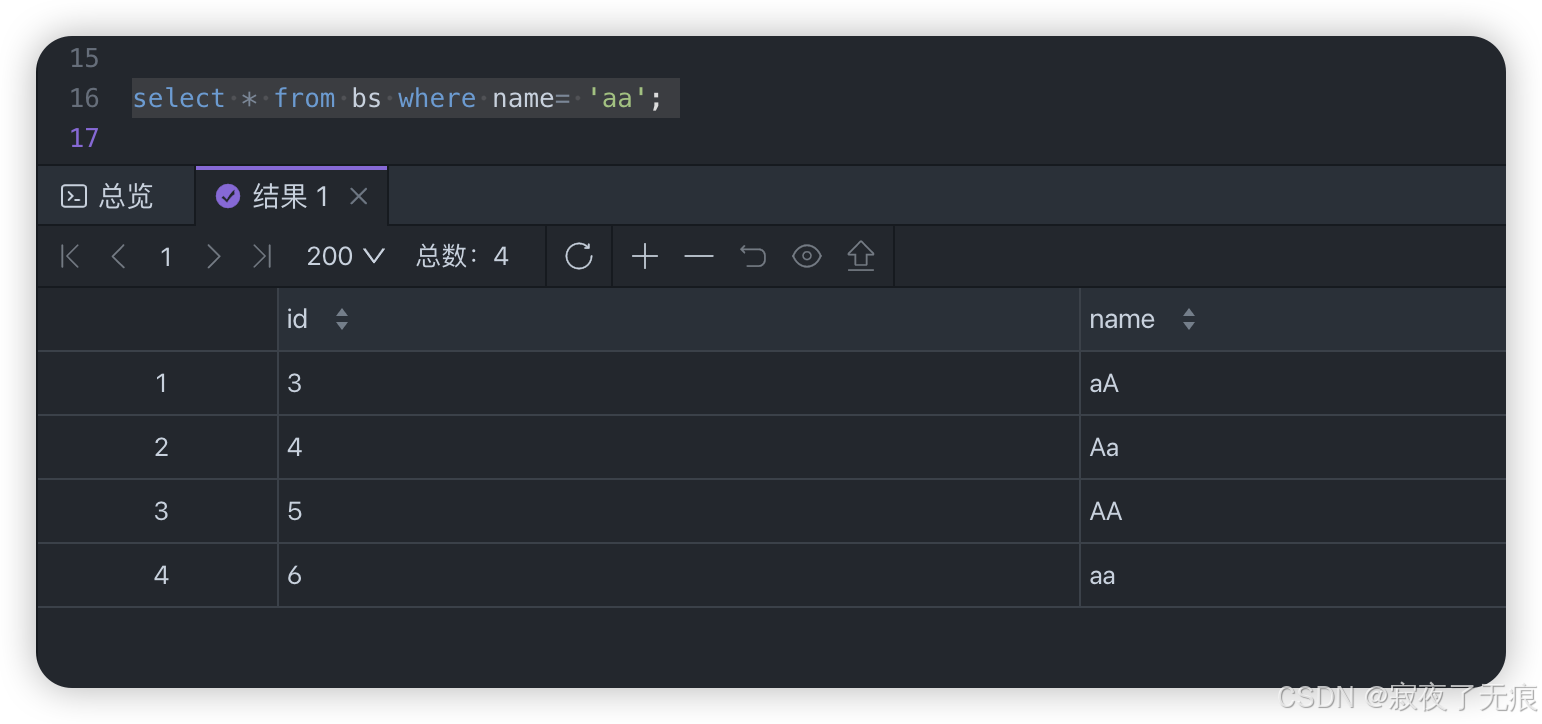
select * from bs where name= 'aa';
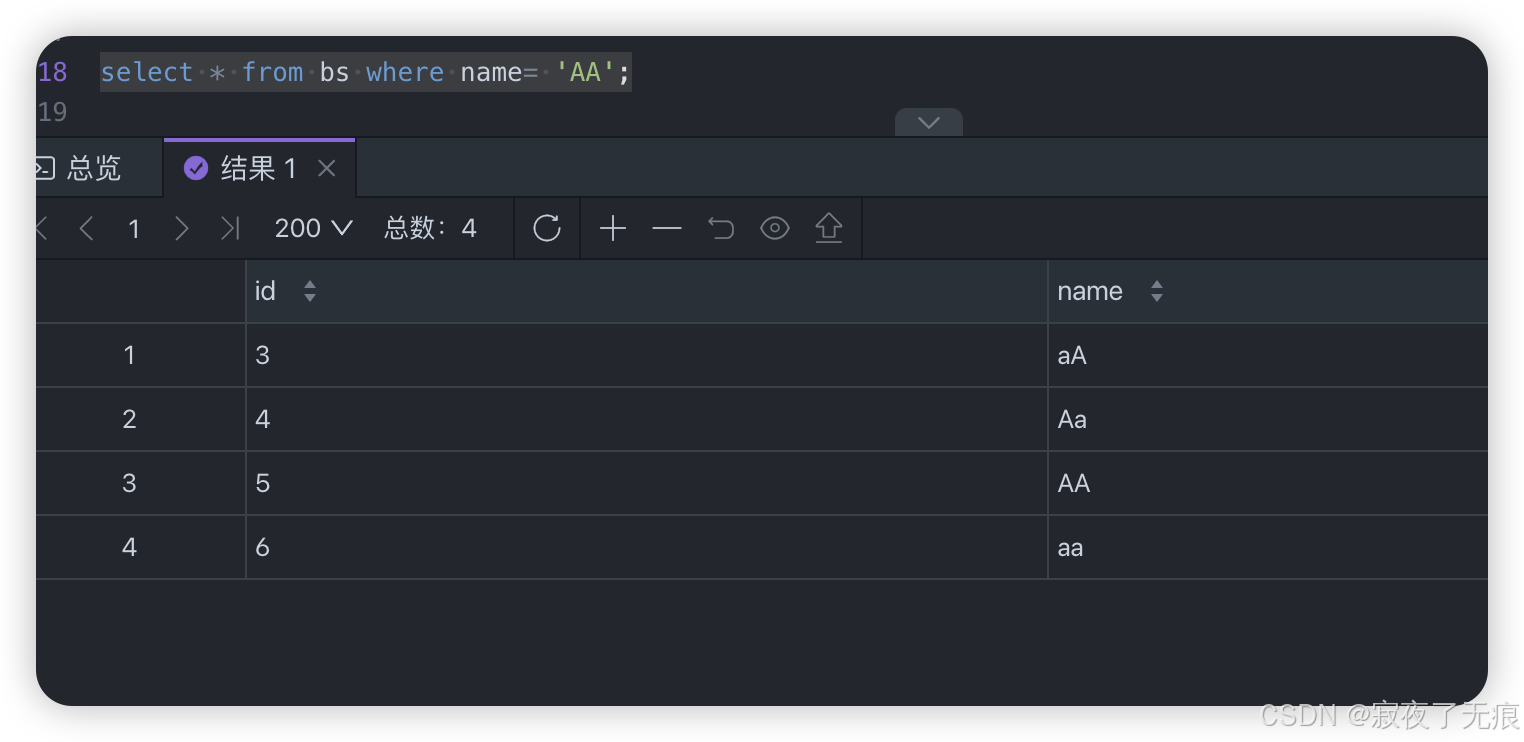
select * from bs where name= 'aa';
select * from bs where name= 'aa';
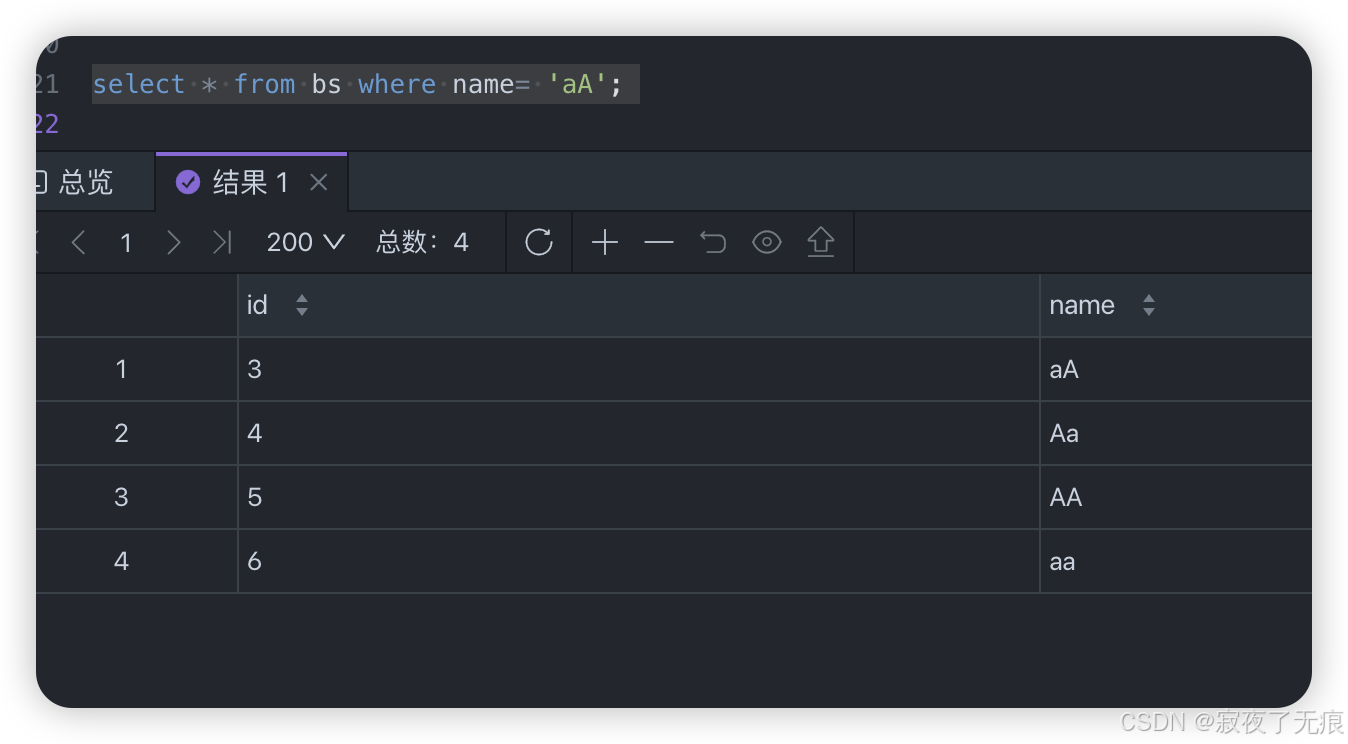
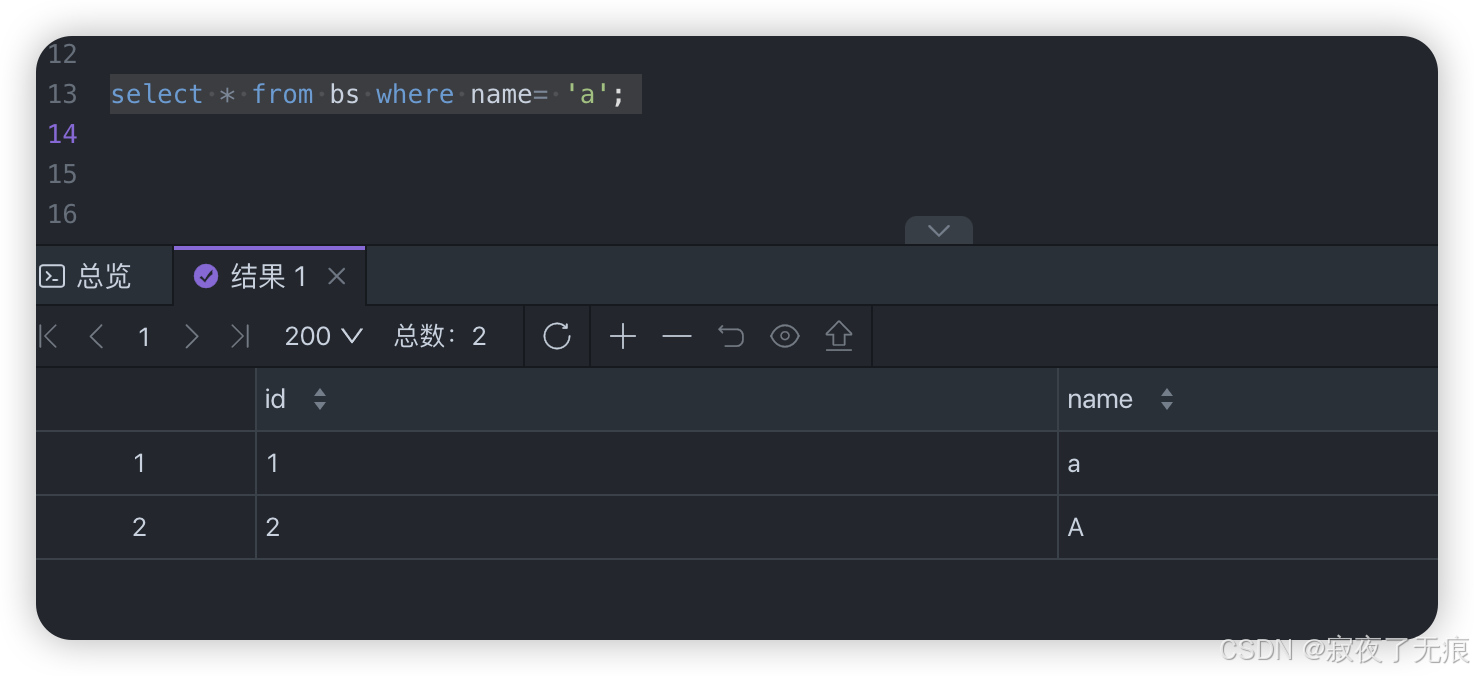
select * from bs where name= 'aa';
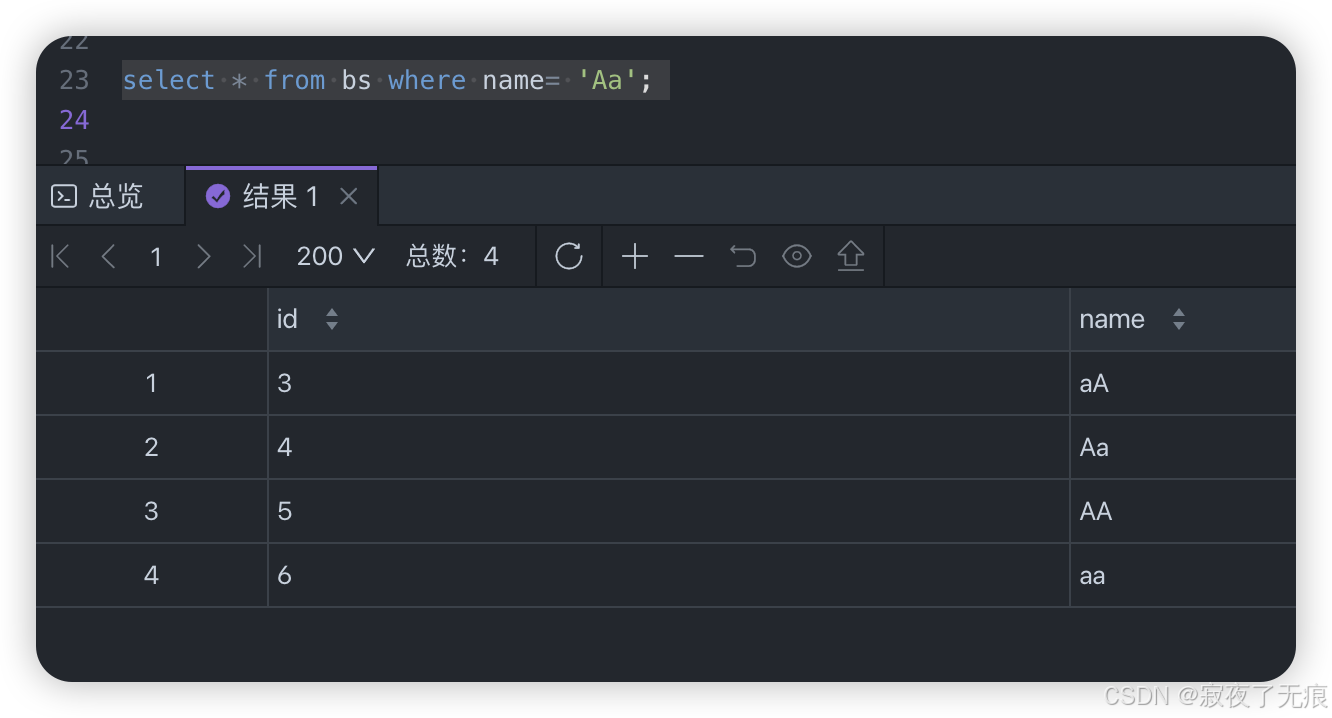
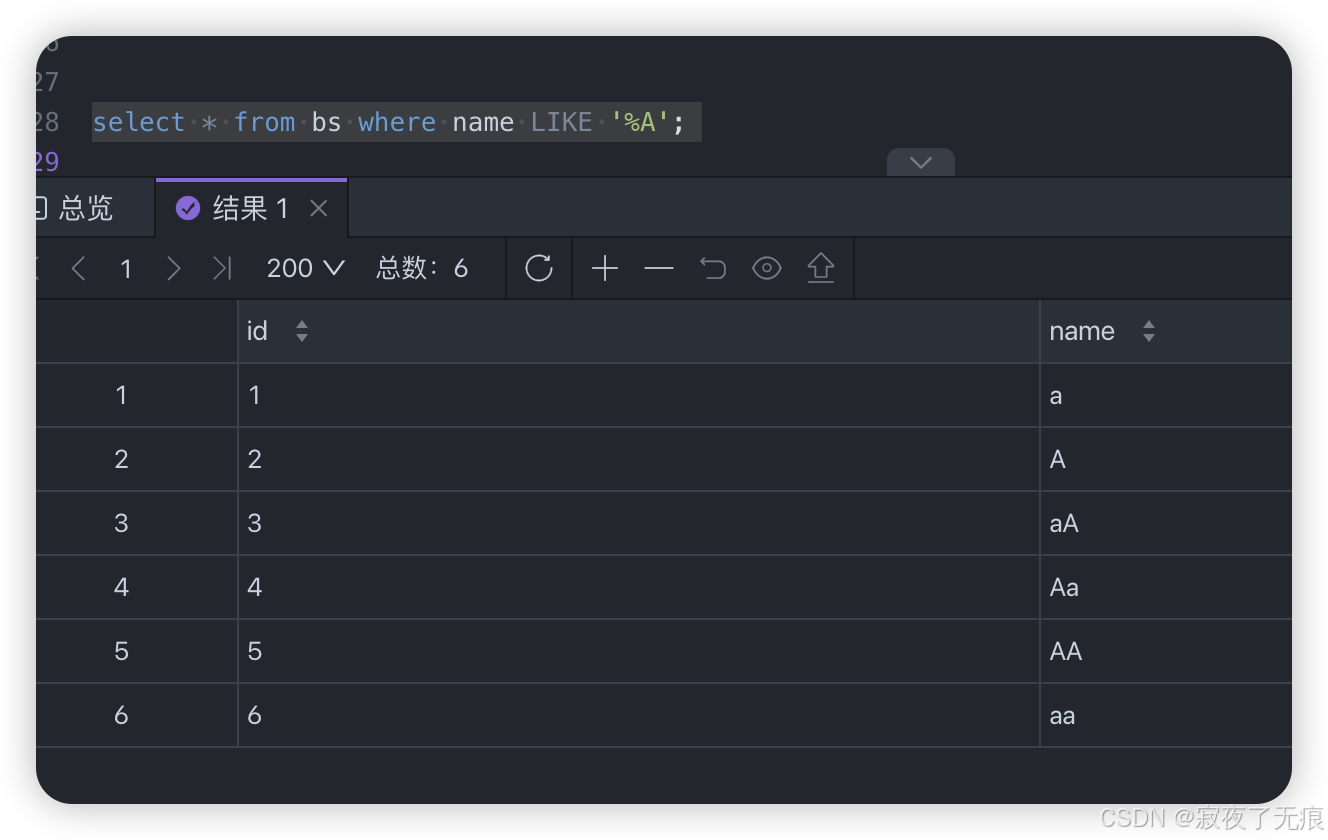
select * from bs where name like '%a';
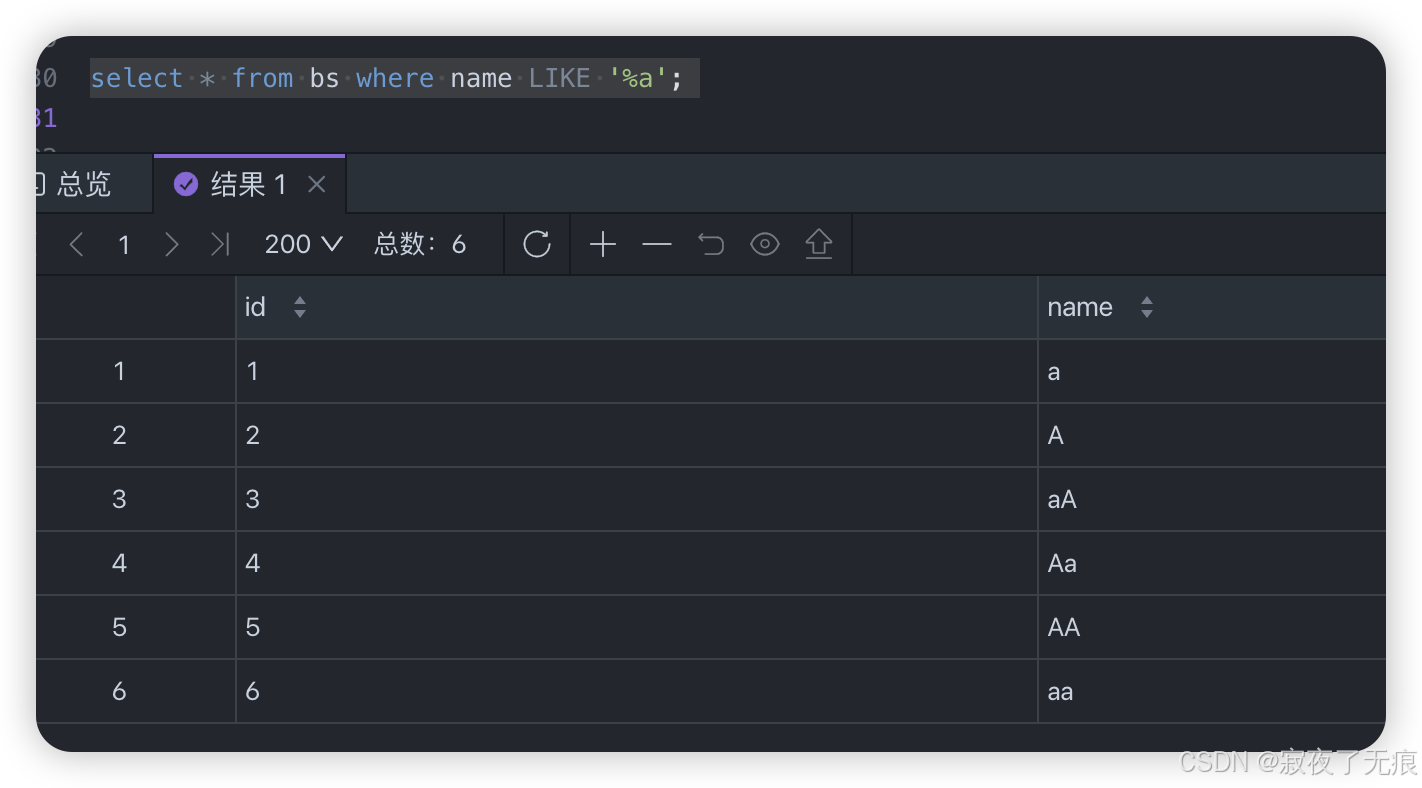
select * from bs where name like '%a';
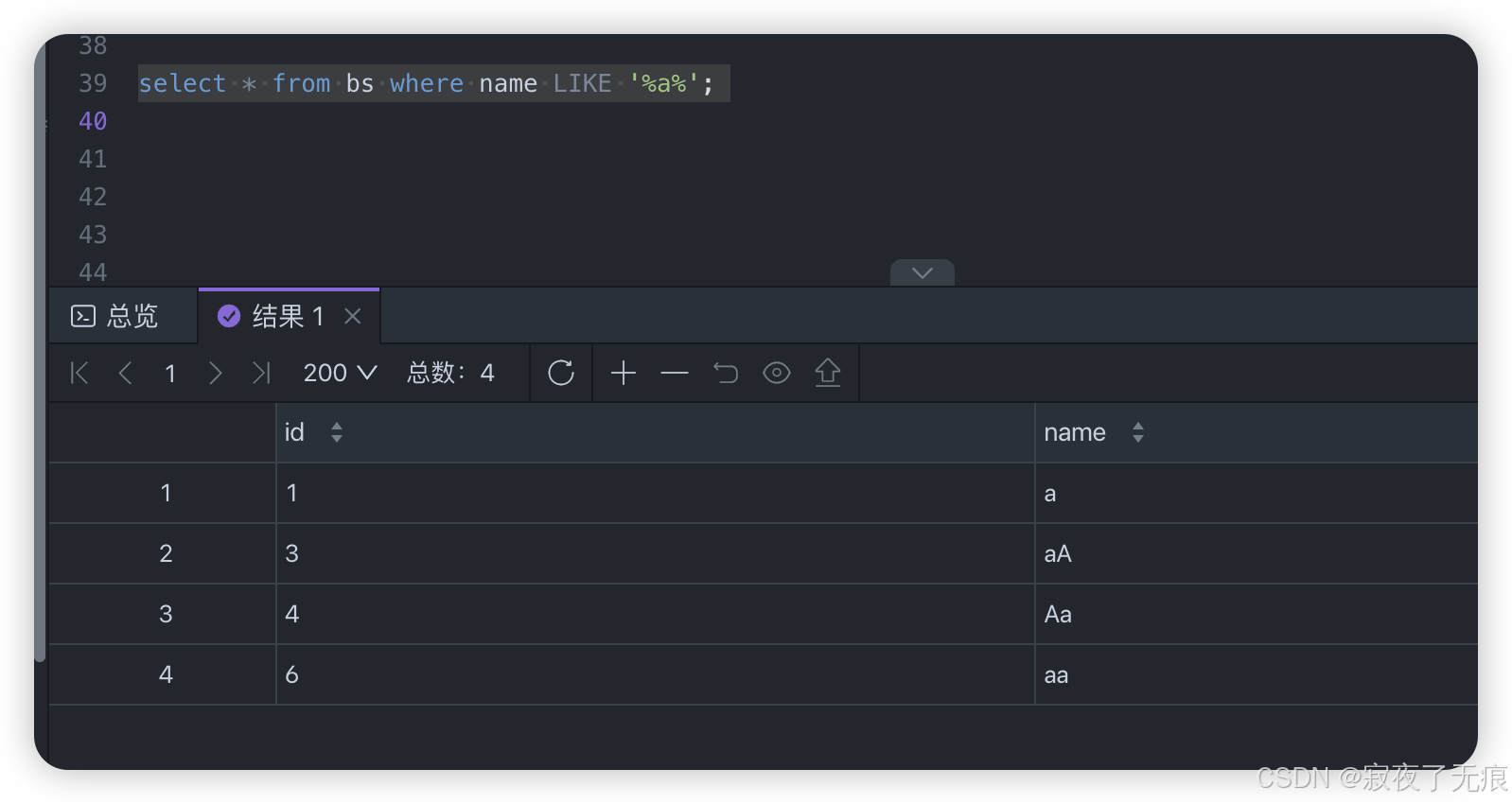
select * from bs where name= '%a%';
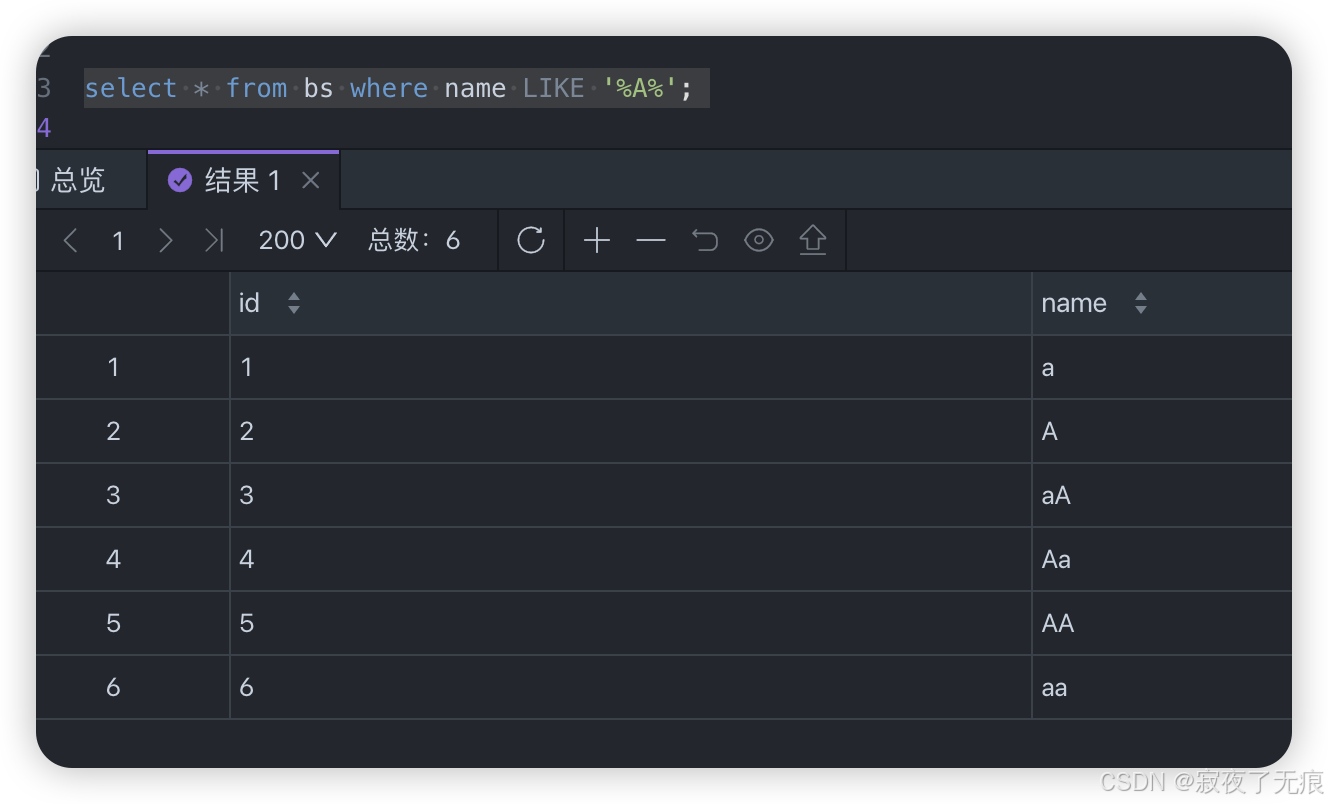
select * from bs where name= '%a%';
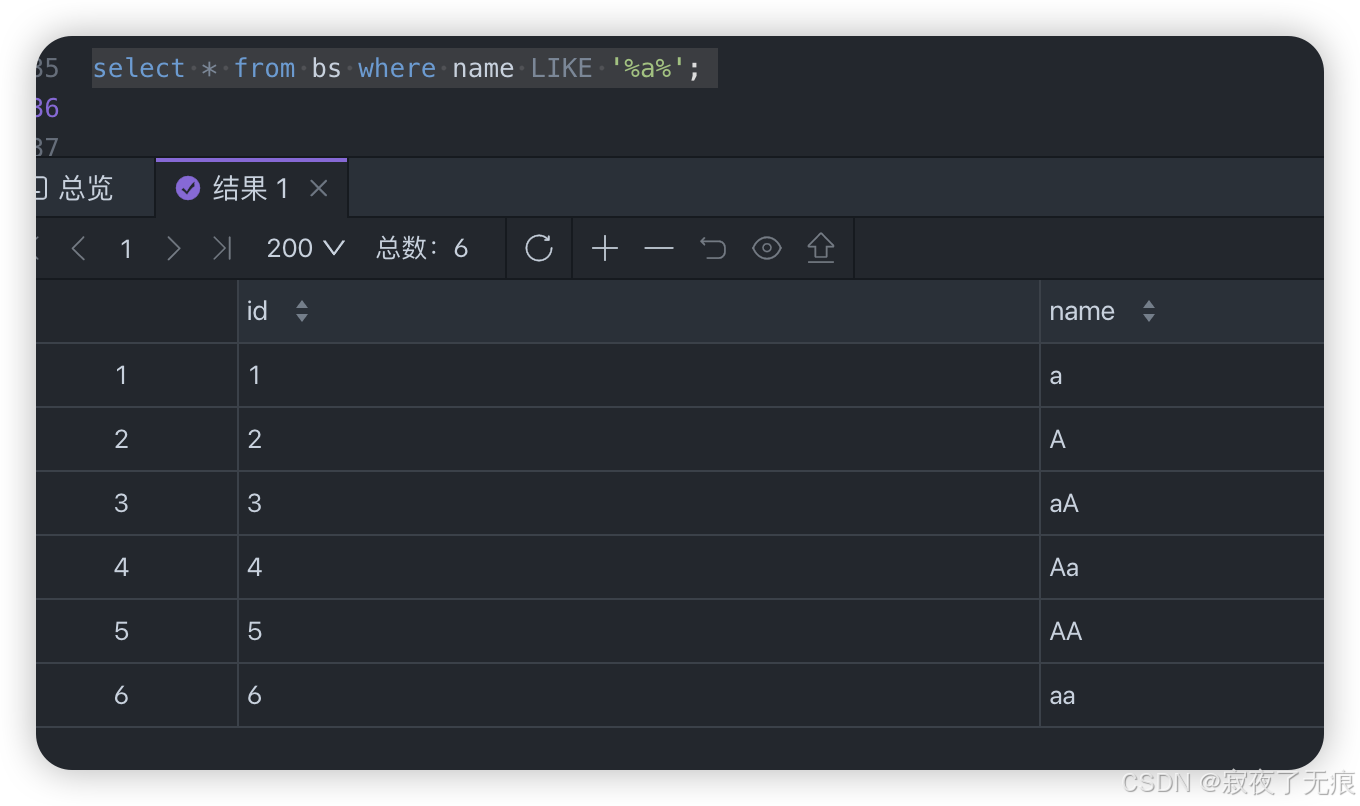
排序规则 区分大小写 数据测试
修改表name 字段为 排序规则为 utf8mb4_bin
alter table `bs` modify column `name` varchar(255) character set utf8mb4 collate utf8mb4_bin not null ;
select * from bs where name= 'a';

select * from bs where name= 'a';
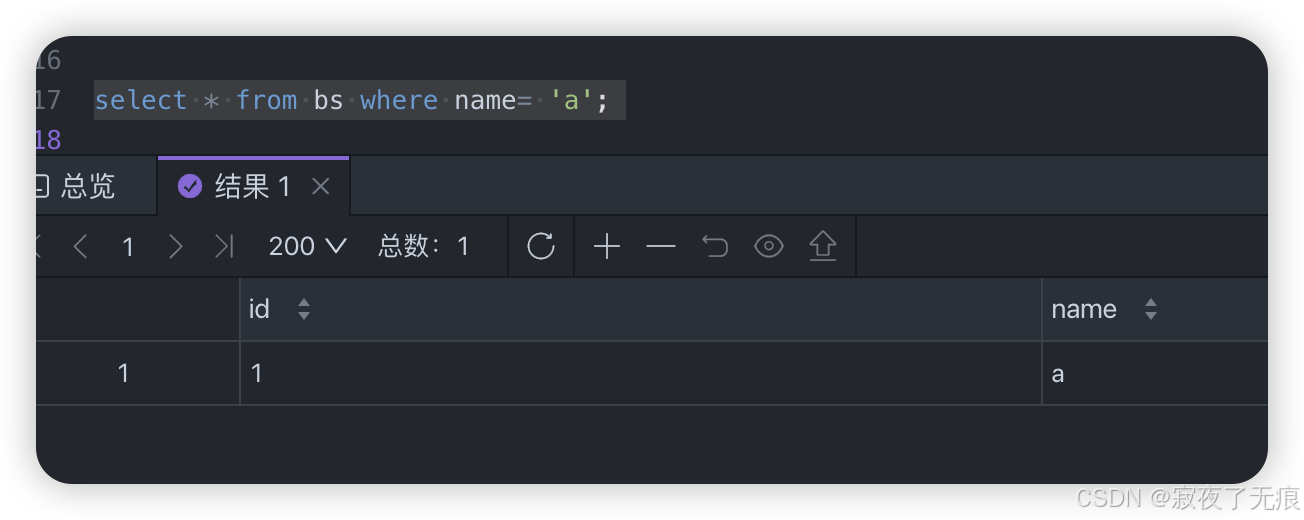
select * from bs where name= 'aa';

select * from bs where name= 'aa';
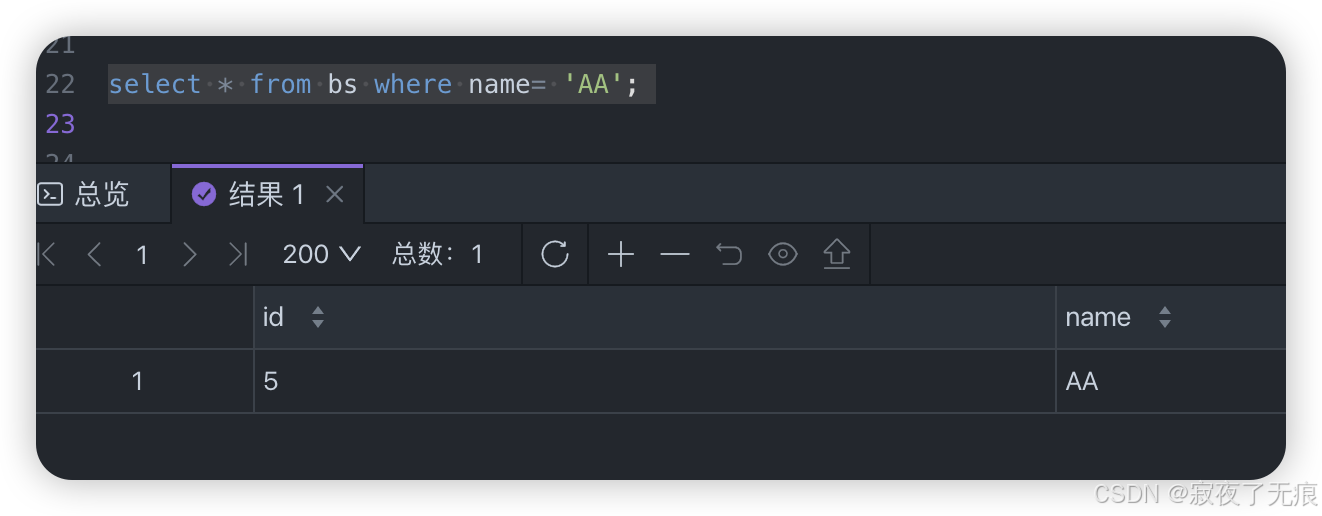
select * from bs where name= 'aa';
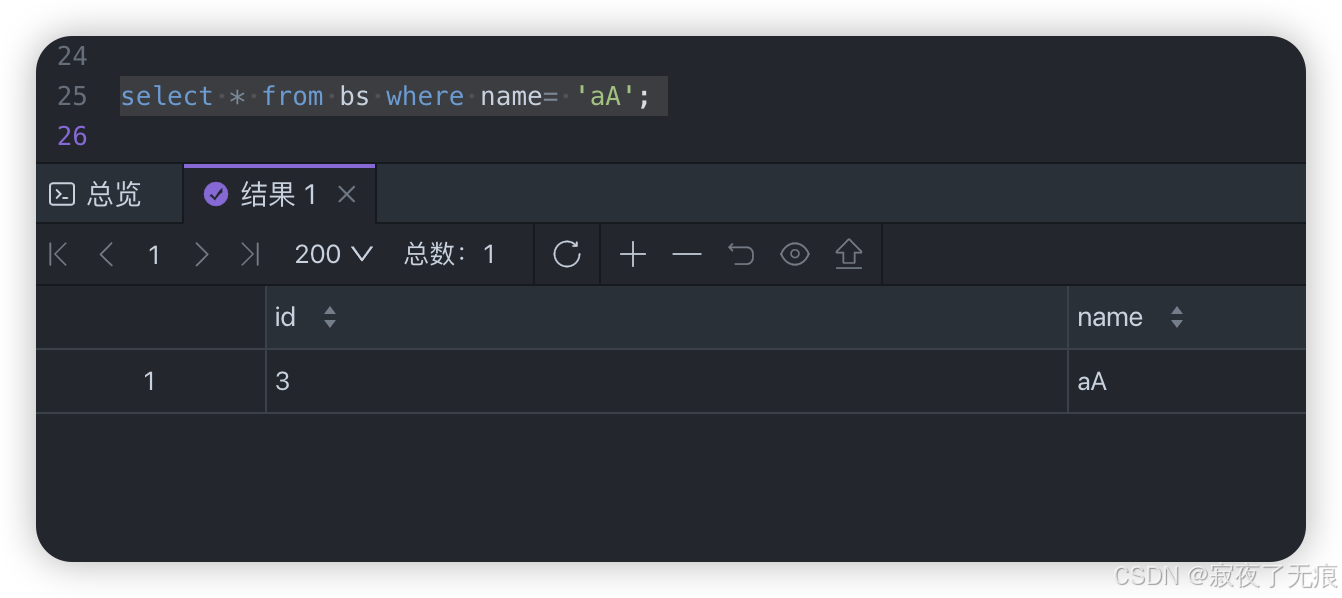
select * from bs where name= 'aa';
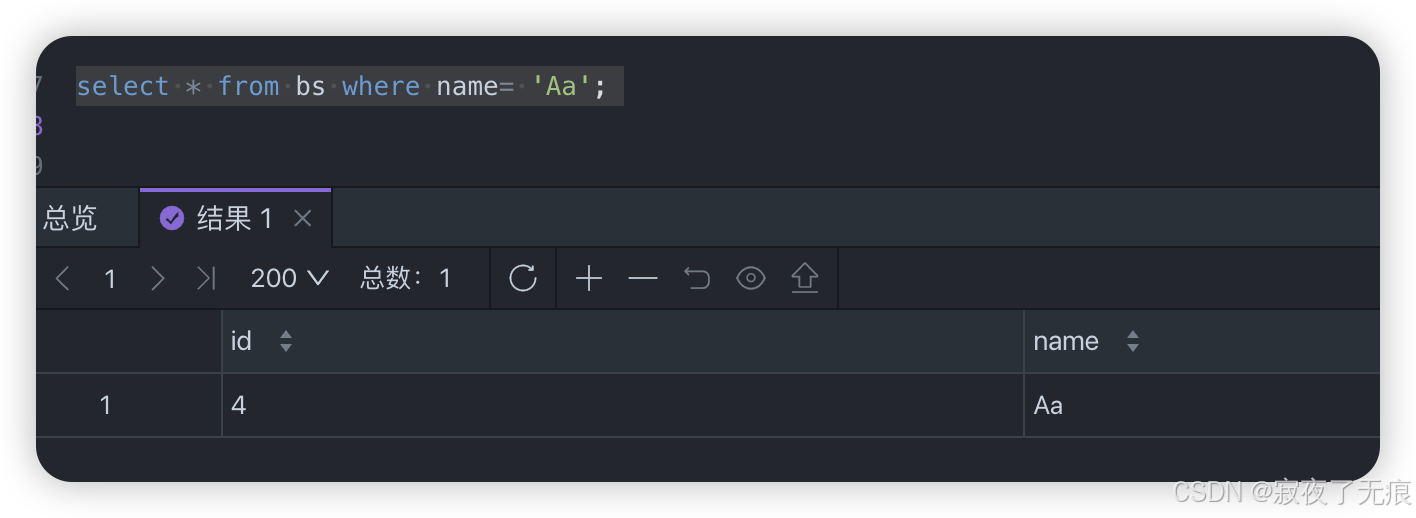
select * from bs where name like '%a';
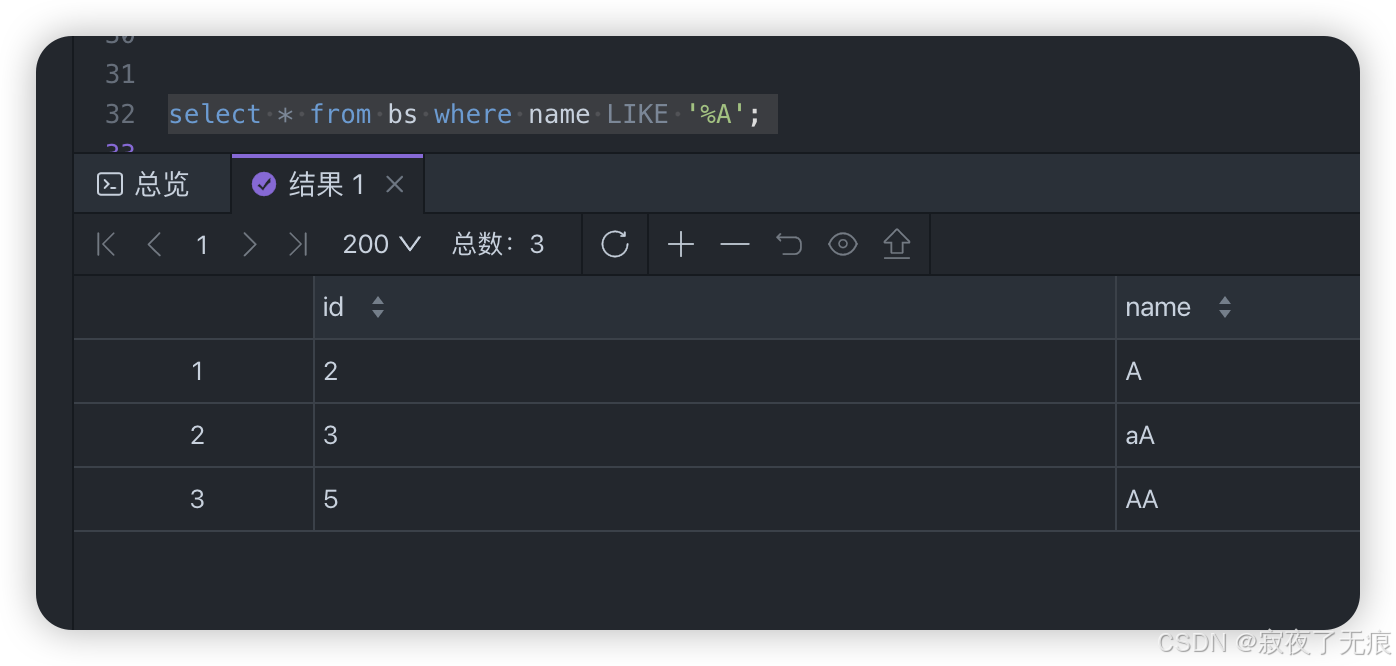
select * from bs where name like '%a';
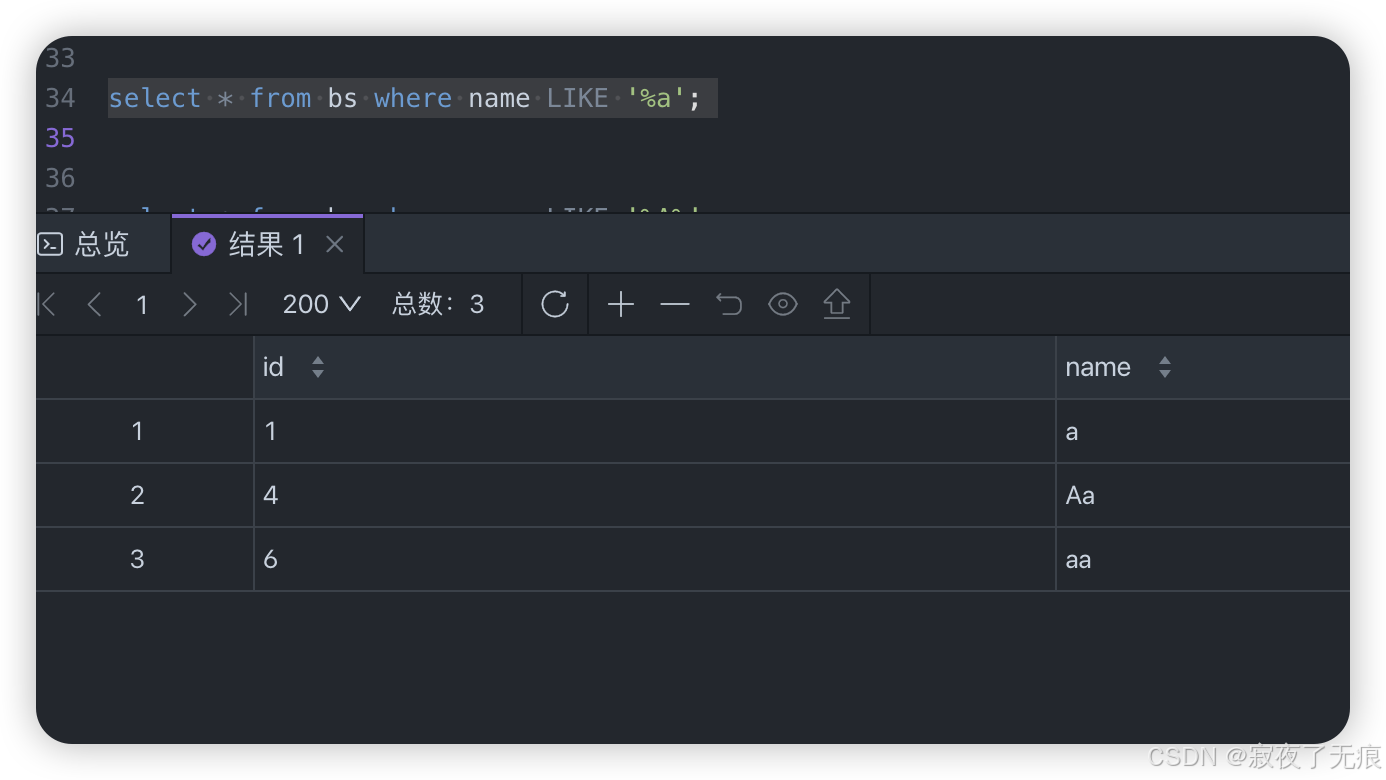
select * from bs where name like '%a%';

select * from bs where name like '%a%';
总结
可以看到在排序规则区分大小写和不区分大小写 对sql查询的结果 影响还是比较大的。
所以在选择字符集时,需要考虑使用的语言、特殊字符的需求以及数据存储的具体情况。确保所选字符集能够覆盖项目中的所有字符需求,并选择合适的排序规则以确保数据的正确比较和排序。
到此这篇关于mysql字符集和排序规则详解的文章就介绍到这了,更多相关mysql字符集和排序规则内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!

发表评论