感谢人迹22同学指出了init函数和do_request()函数的两处bug,具体bug修正写在文末。
2024年2月29日
前言
概述
在上一章中,我们写好了线程池的代码,当时我们说说的是请求队列里面添加的元素的类型是http解析类型。具体什么是http解析,今天我们就来了解一下。
我就不在文章里给出http的原理了,感兴趣可以的同学可以去网上找。我们应该知道的是,在服务器项目中,http很重要。如果说先前我们写的线程,数据库池或者底层的小工具如locker锁等东西是地基,是骨架,那么http解析部分就是主体,是血肉。那么可以预见是,http解析部分的内容会相当地长,它应该是目前为止最长的一篇文章,我会尽可能地分段地来介绍每一部分地功能和代码,也会使用更多的拓扑图来梳理结构。如果阅读起来太累,我推荐你按分段一段一段地读,读完一段歇口气,然后再看后面的部分。我也非常推荐你把笔纸拿出来,解析一下各部分的代码,写一写它们的运行逻辑,我相信这对你帮助会非常大。
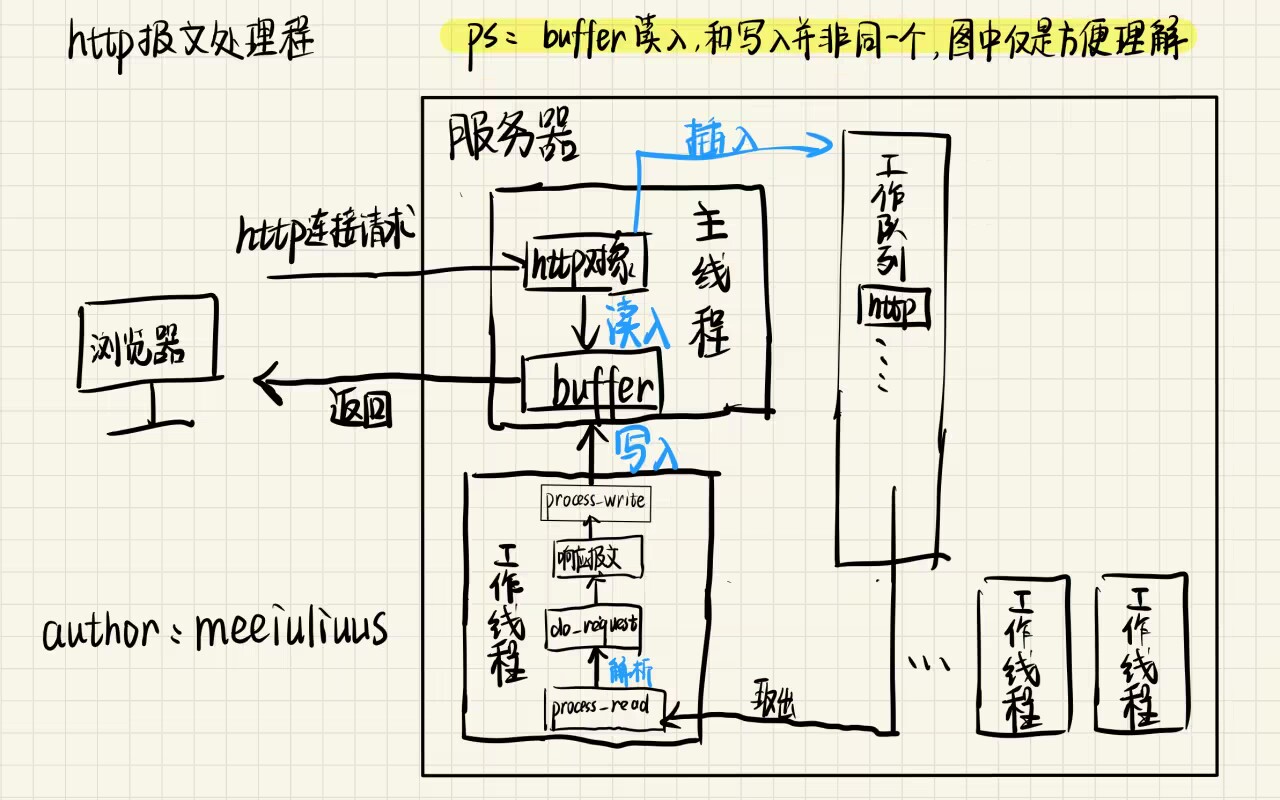
这是我画的简易的拓扑图,它的左边是浏览器,右边整个大框可以理解为部分服务器。可以看到右边的工作队列和工作线程在上一章也有体现,这里它们进入了一个更大的环境,成为了一个局部模块。
头文件
原谅我一次性把这个非常庞大的头文件丢了了上来,按一个模块一个模块地发头文件实在太费时了,而且每个知识点的具体实现大都体现在定义里,声明大家看看就好。头文件中比较重要的内容有这些:
- 主/状态机的状态枚举
- 报文解析的结果枚举
- io向量及buffer控制部分的变量
#ifndef http_conn_h
#define http_conn_h
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/epoll.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <sys/stat.h>
#include <string.h>
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <stdarg.h>
#include <errno.h>
#include <sys/wait.h>
#include <sys/uio.h>
#include <map>
#include "../lock/locker.h"
#include "../cgimysql/sql_connection_pool.h"
#include "../timer/lst_timer.h"
#include "../log/log.h"
class http_conn{
public:
/*设置读取文件的名称m_rea_file大小*/
static const int filename_len = 200;
/*设置读缓冲区m_read_buf大小*/
static const int read_buffer_size = 2048;
/*设置写缓冲区m_write_buf大小*/
static const int write_buffer_size = 1024;
/*报文的请求方法,本项目只用到get和post*/
enum method{get = 0, post, head, put, delete, trace, options, connect, path};
/*主状态机的状态*/
enum check_state{check_state_requestline = 0, check_state_header, check_state_content};
/*报文解析结果*/
enum http_code{no_request, get_request, bad_request, no_resource, forbidden_request, file_request, internal_error, closed_connections};
/*从状态机的状态*/
enum line_status{line_ok = 0, line_bad, line_open};
public:
http_conn(){}
~http_conn(){}
public:
/*初始化套接字地址,函数内部调用私有方法init*/
void init(int sockfd, const sockaddr_in &addr, char *, int, int, string user, string passwd, string sqlname);
/*关闭http连接*/
void close_conn(bool real_close = true);
void process();
/*读取浏览器端发来的全部数据*/
bool read_once();
/*响应报文写入函数*/
bool write();
sockaddr_in *get_address() {
return &m_address;
}
/*同步线程初始化数据库读取表*/
void initmysql_result(connection_pool *connpool);
int timer_flag;
int improv;
private:
void init();
/*从m_read_buf读取,并处理请求报文*/
http_code process_read();
/*向m_write_buf写入响应报文*/
bool process_write(http_code ret);
/*主状态机解析报文中的请求行数据*/
http_code parse_request_line(char *text);
/*主状态机解析请求报文中的请求头数据*/
http_code parse_headers(char *text);
/*主状态机解析报文中的请求内容*/
http_code parse_content(char *text);
/*生成响应报文*/
http_code do_request();
/*m_start_line是已解析的字符*/
/*get_line用于将指针往后偏移,指向未处理的字符*/
char *get_line() {return m_read_buf + m_start_line;};
/*从状态机读取一行,分析是请求报文的哪一部分*/
line_status parse_line();
void unmap();
/*根据响应报文的格式,生成对应的8个部分,以下函数均由do_request调用*/
bool add_response(const char *format,...);
bool add_content(const char *content);
bool add_status_line(int status, const char *title);
bool add_headers(int content_length);
bool add_content_type();
bool add_content_length(int content_length);
bool add_linger();
bool add_blank_line();
public:
static int m_epollfd;
static int m_user_count;
mysql *mysql;
int m_state;//读事件0,写事件1
private:
int m_sockfd;
sockaddr_in m_address;
/*存储读取的请求报文*/
char m_read_buf[read_buffer_size];
/*缓冲区中m_read_buf中数据的最后一个字节的下一个位置*/
long m_read_idx;
/*m_read_buf读取的位置m_checked_idx*/
long m_checked_idx;
/*m_read_buf中已经解析的字符个数*/
int m_start_line;
/*存储发送的响应报文数据*/
char m_write_buf[write_buffer_size];
/*指示buffer中的长度*/
int m_write_idx;
/*主状态机的状态*/
check_state m_check_state;
/*请求方法*/
method m_method;
/*以下为解析请求报文中对应的6个变量*/
char m_real_file[filename_len];
char *m_url;
char *m_version;
char *m_host;
long m_content_length;
bool m_linger;
char *m_file_address; //读取服务器上的文件地址
struct stat m_file_stat;
struct iovec m_iv[2]; //io向量机制iovec
int m_iv_count;
int cgi; //是否启用的post
char *m_string; //存储请求头数据
int bytes_to_send; //剩余发送的字节
int bytes_have_send; //已发送的字节
char *doc_root; //网站根目录
map<string, string> m_users;
int m_trigmode; //m_trigmode == 1时epoll为et触发模式
int m_close_log;
char sql_user[100];
char sql_passwd[100];
char sql_name[100];
};
#endif
定义文件
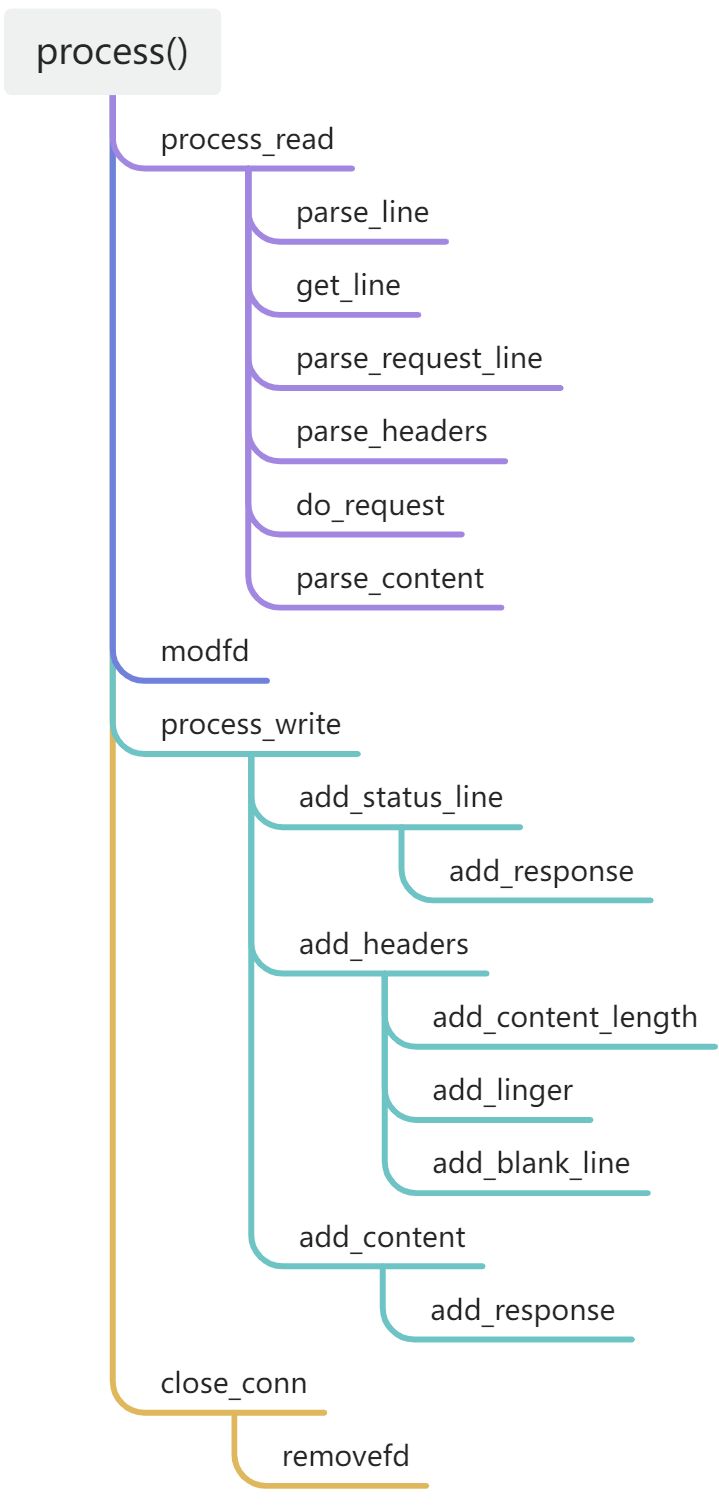
process()函数是http最为核心的函数,将process()函数的调用栈画成目录格式见下图,帮助各位同学理解各代码所处的位置。
接收连接
init
http类的初始化工作我们单独定义了一个init函数对私有成员初始化,而不是使用构造函数。我们定义两个init(),一个有参一个无参,有参init()初始化的内容是一些 根据连接进来的用户动态变化的变量,不同的连接这部分内容都不相同,而无参init()则负责将类的内部用于实现各模块功能的变量初始化,具体代码见下
int http_conn::m_user_count = 0;
int http_conn::m_epollfd = -1;
void http_conn::init(int sockfd, const sockaddr_in &addr, char *root, int trigmode,
int close_log, string user, string passwd, string sqlname) {
m_sockfd = sockfd;
m_address = addr;
m_trigmode = trigmode;
addfd(m_epollfd, sockfd, true, m_trigmode);
m_user_count++;
/*当浏览器出现连接重置时,可能是网站根目录出错或http响应格式出错或者访问的文件中内容完全为空*/
doc_root = root;
m_close_log = close_log;
strcpy(sql_user, user.c_str());
strcpy(sql_passwd, passwd.c_str());
strcpy(sql_name, sqlname.c_str());
/*私有无参初始化*/
init();
}
addfd
/*设置fd非阻塞*/
int setnonblocking(int fd) {
int old_option = fcntl(fd, f_getfl);
int new_option =old_option | o_nonblock;
fcntl(fd, f_setfl, new_option);
return old_option;
}
/*将内核事件表注册读事件,et模式,选择开启epolloneshot*/
void addfd(int epollfd, int fd, bool one_shot, int trigmode) {
epoll_event event;
event.data.fd = fd;
if (trigmode ==1) {
event.events = epollin | epollet | epollrdhup;
} else {
event.events = epollin | epollrdhup;
}
if (one_shot) {
event.events |= epolloneshot;
}
epoll_ctl(epollfd, epoll_ctl_add, fd, &event);
setnonblocking(fd);
}
无参init()
/*初始化接收新的连接,check_state默认为分析请求行状态*/
void http_conn::init() {
mysql = null;
bytes_to_send = 0;
bytes_have_send = 0;
m_check_state = check_state_requestline;
m_linger = false;
m_method = get;
m_url = 0;
m_version = 0;
m_content_length = 0;
m_host = 0;
m_start_line = 0;
m_checked_idx = 0;
m_read_idx = 0;
m_write_idx = 0;
cgi = 0;
m_state = 0;
timer_flag = 0;
improv = 0;
memset(m_read_buf, '\0', read_buffer_size);
memset(m_write_buf, '\0', write_buffer_size);
memset(m_real_file, '\0', filename_len);
}
removefd, modfd
在init里面我们调用了addfd(),addfd函数实现的功能是将传进来的sockfd(也就是真正的客户端连接)注册在epoll内核事件表上,这里就是我们项目第一次开始涉及epoll了。在基础知识部分我们介绍了三种i/o复用方式:c++ webserver从零开始:基础知识(四)——i/o复用-csdn博客
既然使用了epoll_ctl,那epoll_create去哪了呢?其实我们的epoll_create调用还在最顶层使用,最顶层调用了epoll_create后将得到的epollfd作为参数传递给http类里的init函数,init将其用以设置事件的属性。其实我们在lst_timer类里实现过一次addfd,但是lit_timer中并没有实现removefd,modfd,大家可以想一想这之中的原理。
/*从内核事件表删除描述符*/
void removefd(int epollfd, int fd) {
epoll_ctl(epollfd, epoll_ctl_del, fd, 0);
close(fd);
}
/*将事件重置为oneshot*/
void modfd(int epollfd, int fd, int ev, int trigmode) {
epoll_event event;
event.data.fd = fd;
if (trigmode == 1) {
event.events = ev | epollin | epollet | epollrdhup;
} else {
event.events = ev | epollin | epollrdhup;
}
epoll_ctl(epollfd, epoll_ctl_mod, fd, &event);
}
read_once()
初始化部分完成后,我们来看看http类流程图中做的第一个非常重要的事——将数据读到缓冲区。在这里我们定义了一块缓冲区m_read_buf专门用来存放从浏览器发送来的请求报文,并用一个指针m_read_idx记录、维护这个读缓冲区。这里就涉及到了服务器的一个重要知识点:lt模式和et模式。
在lt模式下,epoll_wait会无数次地通知应用程序读事件的发生,直到应用程序去取。这里的应用程序是什么呢?很显然就是下面这个read_once()代码,在if ( m_trigmode == 0) 程序块里,应用程序用recv去将sockfd内的内容取到m_readbuf里面,如果没有取完,程序是无所谓的,它会继续往下执行,直到下一次epoll_wait再次通知,它便再进行recv操作。
而与此相对应的是另一个程序控制块,即et模式,在et模式下,epoll_wait只会通知应用程序一次,应用程序被要求在这一次就把sockfd中全部的数据取出,即read_once,可以看到在et模式下,代码执行一个永不结束的循环while(true),唯有当数据全部取完(即recv返回-1并设置errno为eagain或ewouldblock)时,程序才会退出,不然程序就一直循环下去。(其实当对方关闭了sock连接也会退出,但这就属于异常处理的流程,而非常规流程了)
bool http_conn::read_once() {
if (m_read_idx >= read_buffer_size) {
return false;
}
int bytes_read = 0;
/*lt模式*/
if (m_trigmode == 0) {
bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, read_buffer_size - m_read_idx, 0);
m_read_idx += bytes_read;
if (bytes_read <= 0) {
return false;
}
return true;
} else {
/*et模式*/
while (true)
{
bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, read_buffer_size - m_read_idx, 0);
if (bytes_read == -1) {
/*当errno == eagain或ewouldblock时,表示没有数据可读,需要稍后尝试*/
if (errno == eagain || errno == ewouldblock) {
break;
}
return false;
}
/*对方关闭连接*/
else if (bytes_read == 0) {
return false;
}
m_read_idx += bytes_read;
}
return true;
}
}
到此为止,http类接收浏览器连接的代码就结束了,接下来介绍http处理连接部分的代码。
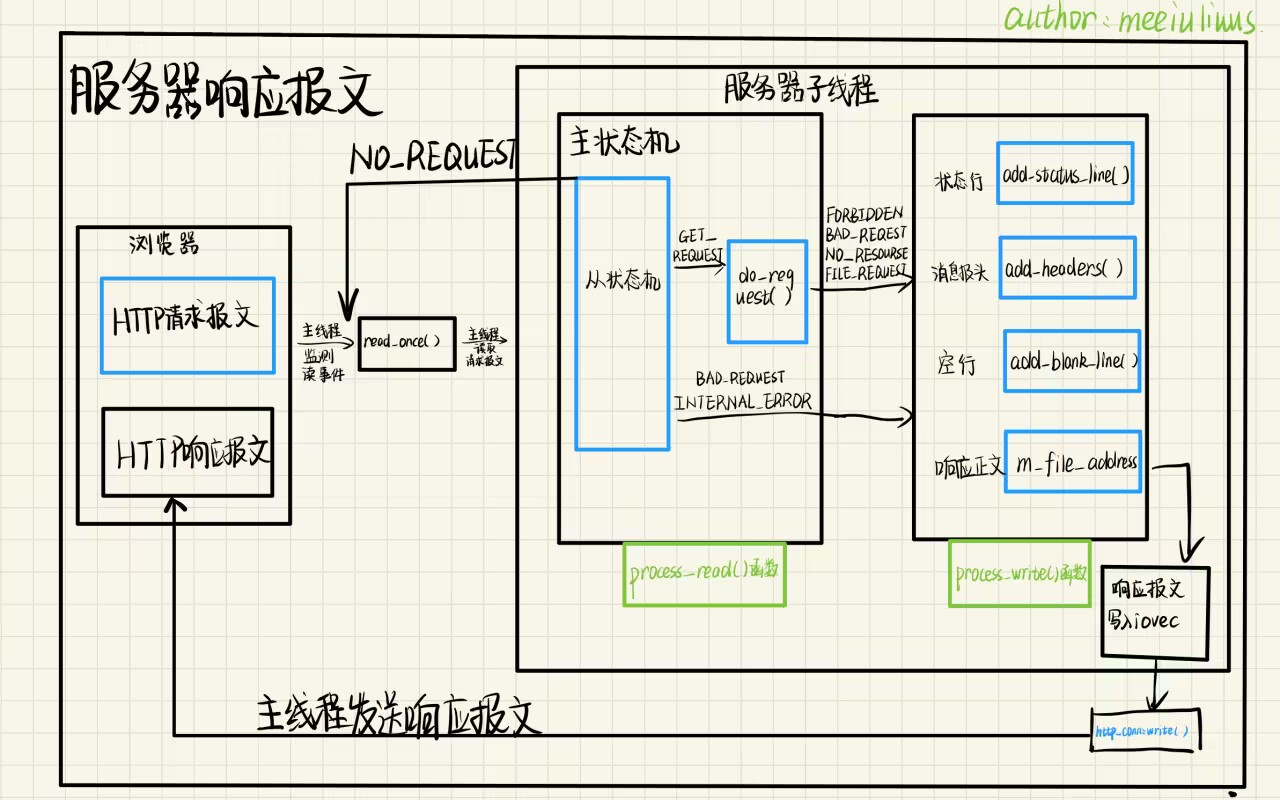
处理连接
在处理连接部分,我们设计了两个状态机主状态机/从状态机来进行报文解析。下图是处理连接的拓扑图:
如果是get请求,则在check_state_header状态中调用do_request
如果是post请求,则在check_state_content状态中调用do_request

从状态机设计
在上面的read_once()函数中我们获得了一个字符数组m_read_buf,和一个指针m_read_idx。在从状态机中,我们开始读取m_read_buf至今为止保存的内容。这时我们需要创建一个新的指针m_checked_idx来记录每一行报文的结束地址。这是因为http报文是按行来分开不同的信息的,所以我们在确定m_checked_idx的结束地址时,可以根据c中的换行转义符 \r\n 来进行判断。下面是从状态机的运行逻辑:
大家可以思考一下,什么情况下当前字符会是\n,而上一个字符是\r(若有不清楚的,可以在评论区提问)
/*从状态机,用于分析出一行的内容
返回值为行的读取状态,有line_ok,line_bad,line_open*/
http_conn::line_status http_conn::parse_line() {
char temp;
for (; m_checked_idx < m_read_idx; ++m_checked_idx) {
temp = m_read_buf[m_checked_idx];
if (temp == '\r') {
if ((m_checked_idx + 1) == m_read_idx) {
return line_open;
} else if (m_read_buf[m_checked_idx + 1] == '\n') {
m_read_buf[m_checked_idx++] = '\0';
m_read_buf[m_checked_idx++] = '\0';
return line_ok;
}
return line_bad;
}
else if (temp == '\n') {
if (m_checked_idx > 1 && m_read_buf[m_checked_idx - 1] == '\r') {
m_read_buf[m_checked_idx - 1] = '\0';
m_read_buf[m_checked_idx++] = '\0';
return line_ok;
}
return line_bad;
}
}
return line_open;
}
主状态机-parse_request_line函数
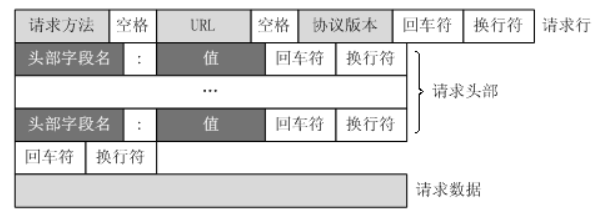
分析http报文格式,我们得知第一行里记录了http报文的类型,url(get类型),版本号。我们便可以开始着手写主状态机的第一个函数了。
/*解析http请求行,获得请求方法,目标url及http版本号*/
http_conn::http_code http_conn::parse_request_line(char *text) {
m_url = strpbrk(text, " \t");//将找到的第一个空格或者水平制表符返回
if (!m_url) {
return bad_request;
}
/*将该位置改为0,并将前面的数据取出*/
*m_url++ = '\0';
/*取出数据,通过与get和post比较,确定请求方式*/
char *method = text;
if (strcasecmp(method, "get") == 0) {
m_method = get;
} else if (strcasecmp(method, "post") == 0) {
m_method = post;
cgi = 1;
} else
return bad_request;
/*m_url此时跳过了第一个空格或\t字符,但不知道后面是否还有
将m_url向后偏移,通过查找,继续跳过空格和\t,指向请求资源的第一个字符*/
m_url += strspn(m_url, " \t");
/*同样的方法判断http版本号*/
m_version = strpbrk(m_url, " \t");
if (!m_version) {
return bad_request;
}
*m_version++ = '\0';
m_version += strspn(m_version, " \t");
if (strcasecmp(m_version, "http/1.1") != 0) {
return bad_request;
}
if (strncasecmp(m_url, "http://", 7) == 0) {
m_url += 7;
m_url = strchr(m_url, '/');
}
if (strncasecmp(m_url, "https://", 8) == 0) {
m_url += 8;
m_url = strchr(m_url, '/');
}
if (!m_url || m_url[0] != '/') {
return bad_request;
}
if (strlen(m_url) == 1) {
strcat(m_url, "judge.html");
}
m_check_state = check_state_header;
return no_request;
}
主状态机--parse_headers函数
解析完请求行,我们再来解析请求头部,根据报文格式,以及头部字段名的种类,我们有下面的代码
/*解析http请求的一个头部信息*/
http_conn::http_code http_conn::parse_headers(char *text) {
/*判断是空行还是请求头*/
if (text[0] == '\0') {
if (m_content_length != 0) {
m_check_state = check_state_content;
return no_request;
}
return get_request;
}
/*解析请求头部连接字段*/
else if (strncasecmp(text, "connection:", 11) == 0) {
text += 11;
/*跳过空格和\t字符*/
text += strspn(text, " \t");
if (strcasecmp(text, "keep-alive") == 0) {
/*如果是长连接,把m_linger设为true*/
m_linger = true;
}
}
/*解析请求头部内容长度字段*/
else if (strncasecmp(text, "content-length:", 15) == 0) {
text += 15;
text += strspn(text, " \t");
m_content_length = atol(text);
}
/*解析请求头部host字段*/
else if (strncasecmp(text, "host:", 5) == 0) {
text += 5;
text += strspn(text, " \t");
m_host = text;
}
else {
log_info("oop!unkonw header: %s", text);
}
return no_request;
}主状态机--parse_content函数
最后解析请求数据,在我们这个项目中,post请求发送的是用户名和密码。以此来实现注册登录功能,实际web中parse_content的内容要多得多得多。
/*判断http请求是否被完整读入*/
http_conn::http_code http_conn::parse_content(char *text) {
if (m_read_idx >= (m_content_length + m_checked_idx)) {
text[m_content_length] = '\0';
/*post请求中最后为输入的用户名和密码*/
m_string = text;
return get_request;
}
return no_request;
}
主状态机实现--process_read
实现了三个parse函数,我们现在来完成主状态机的设计。主状态机的设计主要是根据我们的拓扑图。
有限状态机部分,比较简单,具体的逻辑在拓扑图中也有,就不细说了
http_conn::http_code http_conn::process_read() {
/*初始化从状态机状态,http请求解析结果*/
line_status line_status = line_ok;
http_code ret = no_request;
char* text = 0;
/*parse_line为从状态机的具体实现*/
while( ((line_status = parse_line()) == line_ok) || (m_check_state == check_state_content && line_status == line_ok) ) {
text = get_line();
/*m_checked_idx是每一个数据行在m_read_buf中的起始位置*/
/*m_checked_idx表示从状态机在m_read_buf中读取的位置*/
m_start_line = m_checked_idx;
log_info("%s", text);
/*主状态机三种状态转移逻辑转移*/
switch (m_check_state)
{
case check_state_requestline:
{
/*解析请求行*/
ret = parse_request_line(text);
if (ret == bad_request) {
return bad_request;
}
break;
}
case check_state_header:
{
/*解析请求头*/
ret = parse_headers(text);
if (ret == bad_request) {
return bad_request;
}
/*完整解析get请求后,跳转到报文响应函数*/
else if (ret == get_request) {
return do_request();
}
break;
}
case check_state_content:
{
/*解析消息体*/
ret = parse_content(text);
/*完整解析post请求后,跳转到报文响应函数*/
if (ret == get_request) {
return do_request();
}
/*解析完消息体即完成了报文解析,为了避免再次进入循环,更新line_status*/
line_status = line_open;
break;
}
default:
return internal_error;
}
}
return no_request;
}
响应连接
ok,我们的http解析流程进入最后一步,响应连接。
do_request
在do_request部分,我们实现对post请求的响应连接。同时我们在这里实现一个简易的注册登录功能。
除此之外,我们根据m_url中最后一个‘/’的后一位的字符来判断返回给用户什么资源
http_conn::http_code http_conn::do_request() {
strcpy(m_real_file, doc_root);
int len = strlen(doc_root);
/*找到m_url中/的位置*/
const char *p = strrchr(m_url, '/');
/*处理cgi*/
if (cgi == 1 && (*(p + 1) == '2' || *(p + 1) =='3')) {
/*根据标志判断是登录检测还是注册检测*/
char flag = m_url[1];
char *m_url_real = (char *)malloc(sizeof(char)* 200);
strcpy(m_url_real, "/");
strcat(m_url_real, m_url + 2);
strncpy(m_real_file + len, m_url_real, filename_len - len - 1);
free(m_url_real);
/*提取用户名和密码*/
char name[100], password[100];
int i;
for (i = 5; m_string[i] != '&'; ++i)
name[i - 5] = m_string[i];
name[i - 5] = '\0';
int j = 0;
for (i = i + 10; m_string[i] != '\0'; ++i, ++j)
password[j] = m_string[i];
password[j] = '\0';
if (*(p + 1) == '3') {
/*如果是注册,先检测数据库中是非有重名的
没有重名,增加数据*/
char *sql_insert = (char *)malloc(sizeof(char) * 200);
strcpy(sql_insert, "insert into user(username, passwd) values(");
strcat(sql_insert, "'");
strcat(sql_insert, name);
strcat(sql_insert, "', '");
strcat(sql_insert, password);
strcat(sql_insert, "')");
if (users.find(name) == users.end()) {
m_lock.lock();
/*sql查询*/
int res = mysql_query(mysql,sql_insert);
users.insert(pair<string, string>(name, password));
m_lock.unlock();
if (!res) {
strcpy(m_url, "/log.html");
} else {
strcpy(m_url, "/registererror.html");
}
} else {
strcpy(m_url, "/registererror.html");
}
}
/*如果是登录,直接判断
若浏览器端输入的用户名和密码在表中可以查找到,返回1,否则返回0*/
else if (*(p + 1) == '2') {
if (users.find(name) != users.end() && users[name] == password) {
strcpy(m_url, "/welcome.html");
} else {
strcpy(m_url, "/logerror.html");
}
}
}
/*如果请求资源为/0,表示跳转注册界面*/
if (*(p + 1) == '0') {
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/register.html");
/*将网站目录和/register.html进行拼接,更新到m_real_file中*/
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
/*请求资源为/1,表示跳转登录界面*/
else if (*(p + 1) == '1') {
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/log.html");
strncpy(m_real_file + len, m_url_real, sizeof(m_url_real));
free(m_url_real);
}
else if (*(p + 1) == '5')
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/picture.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else if (*(p + 1) == '6')
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/video.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else if (*(p + 1) == '7')
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/fans.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else {
strncpy(m_real_file + len, m_url, filename_len - len - 1);
}
if (stat(m_real_file, &m_file_stat) < 0) {
return no_resource;
}
/*如果文件不可读,返回forbidden_request*/
if (!(m_file_stat.st_mode & s_iroth)) {
return forbidden_request;
}
/*如果是目录,返回bad_request*/
if (s_isdir(m_file_stat.st_mode)) {
return bad_request;
}
/*以只读方式获取文件描述符,通过mmap将该文件描述符映射到内存*/
int fd = open(m_real_file, o_rdonly);
m_file_address = (char *)mmap(0, m_file_stat.st_size, prot_read, map_private, fd, 0);
close(fd);
/*请求文件存在,可以访问*/
return file_request;
}
add_response
我们定义一个基础的往http响应的缓冲区添加格式化的数据的函数,并且使用可变参数va_list增加它的可复用性。这样我们后面的各种写数据就可以直接调用add_response了。
bool http_conn::add_response(const char *format, ...) {
/*若写入内容超出m_write_buf大小则报错*/
if (m_write_idx >= write_buffer_size) {
return false;
}
/*定义可变参数列表*/
va_list arg_list;
va_start(arg_list, format);
/*将数据format从可变参数列表写入缓冲区,返回写入数据长度*/
int len = vsnprintf(m_write_buf + m_write_idx, write_buffer_size - 1 - m_write_idx, format, arg_list);
/*若写入的数据长度比缓冲区剩下的空间大,则报错*/
if (len >= (write_buffer_size - 1 - m_write_idx)) {
va_end(arg_list);
return false;
}
/*更新m_write_idx位置*/
m_write_idx += len;
va_end(arg_list);
log_info("request:%s", m_write_buf);
return true;
}
调用add_response的函数系列
/*添加状态行*/
bool http_conn::add_status_line(int status, const char *title) {
return add_response("%s %d %s\r\n", "http/1.1", status, title);
}
/*添加消息报头,具体的添加长度文本 连接状态 和空行*/
bool http_conn::add_headers(int content_len) {
return add_content_length(content_len) && add_linger() && add_blank_line();
}
bool http_conn::add_content_length(int content_len) {
return add_response("content-length:%d\r\n", content_len);
}
bool http_conn::add_content_type() {
return add_response("content-type:%s\r\n", "text/html");
}
bool http_conn::add_linger() {
return add_response("connection:%s\r\n",(m_linger == true) ? "keep-alive" : "close");
}
bool http_conn::add_blank_line() {
return add_response("%s", "\r\n");
}
bool http_conn::add_content(const char *content) {
return add_response("%s", content);
}
process_write
我们在决定好要给浏览器返回什么数据前,还需要根据服务器状态的不同,将不同的数据填入写缓冲区。这与接受连接时,服务器将数据从读缓冲区读出解析相对应。在http协议中定义有状态码,这些状态码给浏览器一些信息以表示服务器资源不同的状态。其中,正常访问的状态以200开头,则在下面的代码中,唯有当http_code状态码为file_request(对应200状态码)时,应用程序才正常地往缓冲区写浏览器请求的数据。
const char *ok_200_title = "ok";
const char *error_400_title = "bad request";
const char *error_400_form = "your request has bad syntax or is inherently impossible to staisfy.\n";
const char *error_403_title = "forbidden";
const char *error_403_form = "you do not have permission to get file form this server.\n";
const char *error_404_title = "not found";
const char *error_404_form = "the requested file was not found on this server.\n";
const char *error_500_title = "internal error";
const char *error_500_form = "there was an unusual problem serving the request file.\n";bool http_conn::process_write(http_code ret) {
switch (ret)
{
case internal_error:
{
add_status_line(500, error_500_title);
add_headers(strlen(error_500_form));
if (!add_content(error_500_form)) {
return false;
}
break;
}
case bad_request:
{
add_status_line(404, error_404_title);
add_headers(strlen(error_404_form));
if (!add_content(error_404_form)) {
return false;
}
break;
}
case forbidden_request:
{
add_status_line(403, error_403_title);
add_headers(strlen(error_403_form));
if (!add_content(error_403_form))
return false;
break;
}
case file_request:
{
add_status_line(200, ok_200_title);
if (m_file_stat.st_size != 0) {
add_headers(m_file_stat.st_size);
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
m_iv[1].iov_base = m_file_address;
m_iv[1].iov_len = m_file_stat.st_size;
m_iv_count = 2;
bytes_to_send = m_write_idx + m_file_stat.st_size;
return true;
} else {
const char *ok_string = "<html><body></body></html>";
add_headers(strlen(ok_string));
if (!add_content(ok_string)) {
return false;
}
}
}
default:
return false;
}
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
m_iv_count = 1;
bytes_to_send = m_write_idx;
return true;
}
write
在写缓冲区写满要发送的数据后,我们最后调用write将其发送给浏览器。这里要注意的api是writev,writev用于一次函数调用写多个非连续缓冲区。在循环里面调用writev时,需要重新处理iovec向量中的指针和长度,writev不会对它们作任何处理。
在write函数中,服务器的子线程注册epollout事件,将缓冲区中的数据存入sock文件描述符,发给浏览器,浏览器进行解析,然后把画面渲染出来,一个网络地址访问的一生就结束了。
bool http_conn::write() {
int temp = 0;
/*响应报文为空*/
if (bytes_to_send == 0) {
modfd(m_epollfd, m_sockfd, epollin, m_trigmode);
init();
return true;
}
while (1) {
/*将响应报文状态行,消息头,空行和响应正文发给浏览器端*/
temp = writev(m_sockfd, m_iv, m_iv_count);
/*未发送*/
if (temp < 0) {
/*判断缓冲区是否满了*/
if (errno == eagain) {
modfd(m_epollfd, m_sockfd, epollout, m_trigmode);
return true;
}
unmap();
return false;
}
bytes_have_send += temp;
bytes_to_send -= temp;
/*第一个iovec头部信息已发完,发第二个*/
if (bytes_have_send >= m_iv[0].iov_len) {
m_iv[0].iov_len = 0;
m_iv[1].iov_base = m_file_address + (bytes_have_send - m_write_idx);
m_iv[1].iov_len = bytes_to_send;
} else {
/*继续发第一个*/
m_iv[0].iov_base = m_write_buf + bytes_have_send;
m_iv[0].iov_len = m_iv[0].iov_len - bytes_have_send;
}
/*数据已全部发完*/
if (bytes_to_send <= 0) {
unmap();
/*epoll上重置epolloneshot事件*/
modfd(m_epollfd, m_sockfd, epollin, m_trigmode);
/*请求为长连接*/
if (m_linger) {
/*重新初始化http对象*/
init();
return true;
} else {
return false;
}
}
}
}封装运行函数--process
最后,我们将http内部的代码封装成一个简单的process函数,将我们所有的设计,细节,心血藏于这短短11行普普通通的代码,这也许就是封装的魅力吧。
void http_conn::process() {
http_code read_ret = process_read();
if (read_ret == no_request) {
modfd(m_epollfd, m_sockfd, epollin, m_trigmode);
return;
}
bool write_ret = process_write(read_ret);
if (!write_ret) {
close_conn();
}
modfd(m_epollfd, m_sockfd, epollout, m_trigmode);
}
结束语
http类我们就完成了,下一章我们开始写最顶层的一个server封装类。将我们至今为止写的所有代码,封装到一个类里,去实现它们的使命。
bug修正:
见下图,do_request()函数中lock()加在if条件判断里面可能导致两个账户同时创建一个users.name的情况。需要将m_lock.unlock()移到if外,并在else里面添加解锁。
这种错误在mysql的并发中有个专有名词:幻读。幻读只有在serializable隔离级别中才可以被避免,而mysql的默认级别刚好是repeatable-raed,刚好无法解决幻读问题,所以这个bug可能会导致mysql报错。
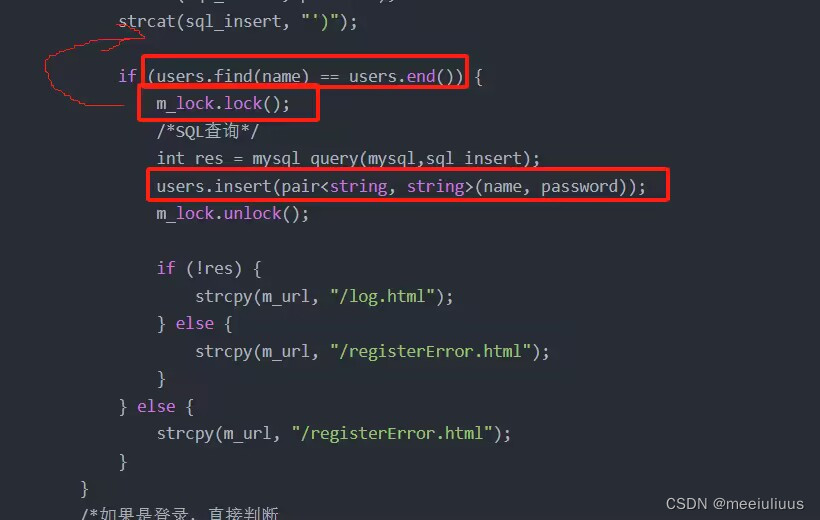
此图来源:人迹22同学


发表评论