文章目录
网易云音乐热歌榜单热评
在的基础上深度爬取网易云音乐热歌榜热评
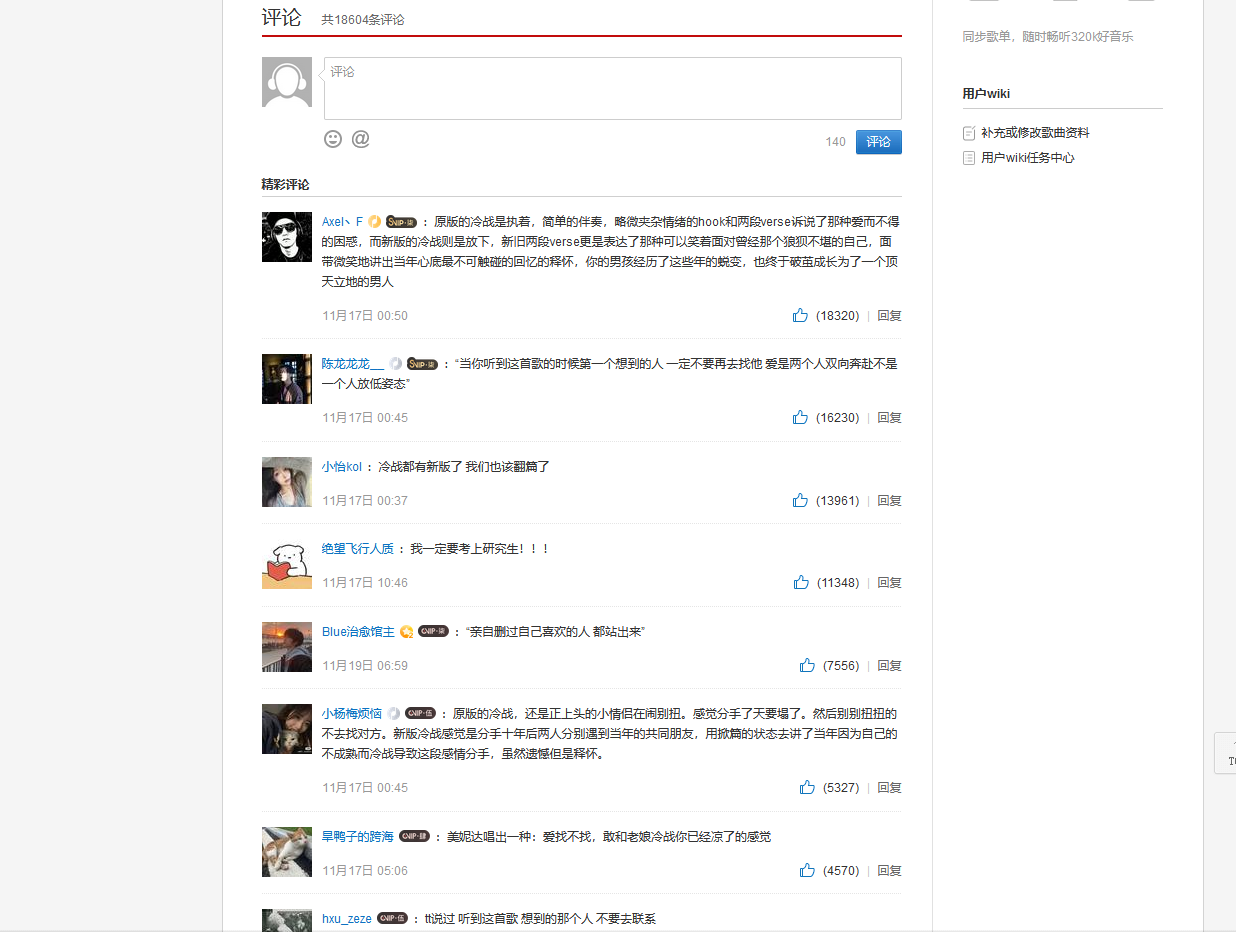
在爬取到热歌榜单的歌曲url后深度爬取歌曲所有的评论数据,通过f12可以发现所有的评论数据在同一个div标签内,而对于热评来说只需要爬取前十五条数据即可,同时要注意页面中嵌套了frame在爬取时需要使用switch_to.frame()方法来切换页面frame以防定位不到元素。
完整代码
from selenium import webdriver
from selenium.webdriver.common.by import by
# edge驱动
driver = webdriver.edge()
# 访问网易云音乐热歌榜
print("访问网易云音乐中..")
driver.get("https://music.163.com/#/discover/toplist?id=3778678")
driver.implicitly_wait(10) # 隐性等待
# 切换到 iframe 中
driver.switch_to.frame('g_iframe')
# 解析网页源代码获取所有 tr 标签
print("解析网页中..")
tr_list = driver.find_elements(by.xpath, "//table[@class='m-table m-table-rank']/tbody/tr")
# 遍历 tr 标签获取每个歌曲的url
print("获取榜单所有歌曲url中..")
url_list = [tr.find_element(by.xpath, "td[2]/div/div/div/span/a").get_attribute("href") for tr in tr_list]
print("开始爬取..")
fp = open("music_hot_comment.txt", "a", encoding="utf-8")
# 遍历 url_list 请求每个url
for url in url_list:
driver.get(url)
# 这里也需要切换到 iframe 中
driver.switch_to.frame('g_iframe')
# 获取歌曲名
music_title = driver.find_element(by.class_name, "tit").text
# print(f"《{music_title}》")
music_title_ = (f"《{music_title}》\n")
# 写入歌名
fp.write(music_title_)
# 获取所有评论
music_comment = driver.find_elements(by.xpath, "//div[@class='cmmts j-flag']")
# 取出每条评论
for comment in music_comment:
# 只要热评 前15条评论为热评
for i in range(1, 16):
hot_comment = comment.find_element(by.xpath, f"div[{i}]/div[2]/div/div").text
# print(f"{hot_comment}")
fp.write(f"{hot_comment}\n")
fp.write("\n")
print("爬取完毕")
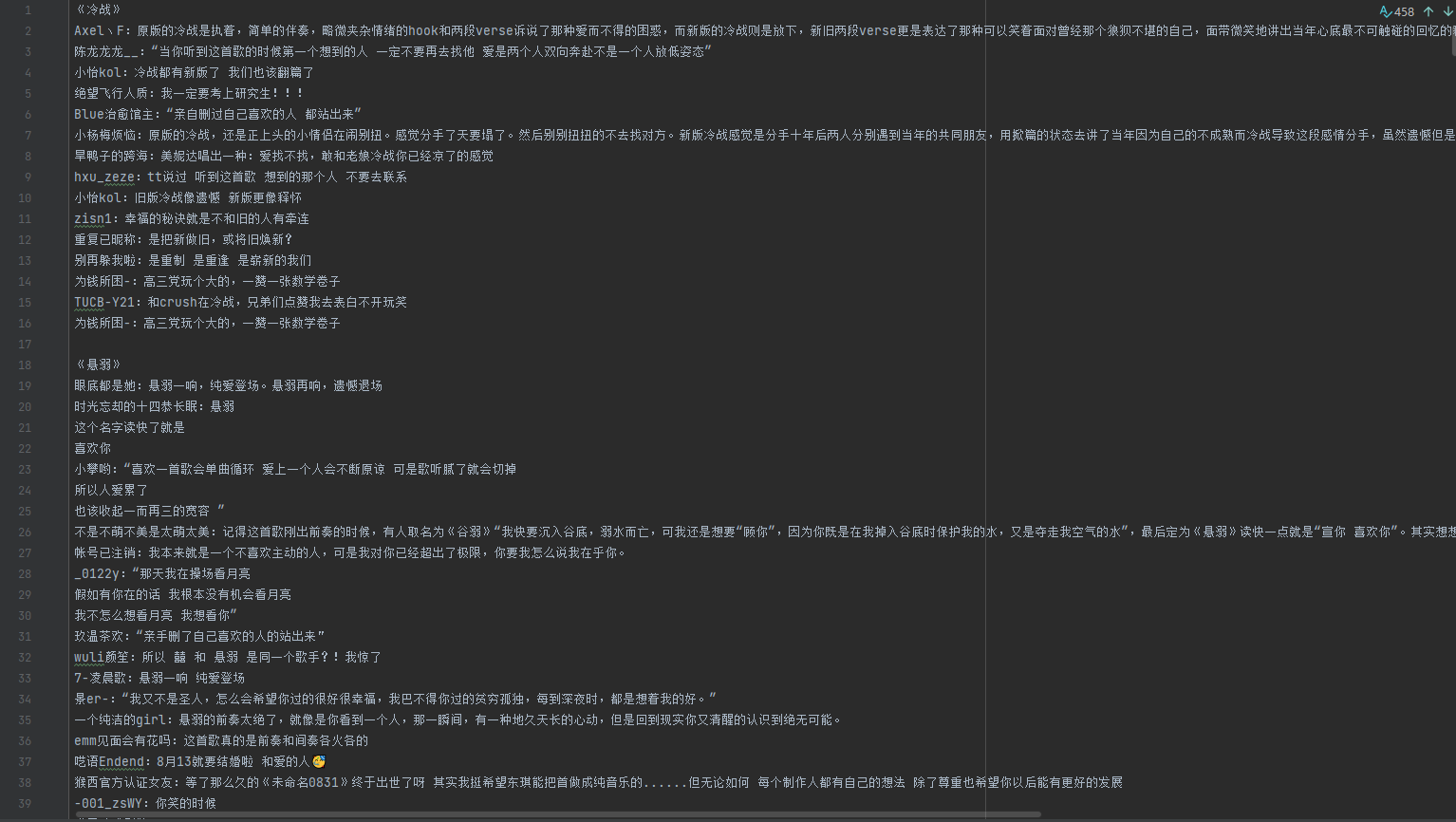
运行结果




发表评论