摘要: maxcompute作为阿里巴巴集团内部绝大多数大数据处理需求的核心计算组件,拥有强大的计算能力,随着集团内外大数据业务的不断扩展,新的数据使用场景也在不断产生。在这样的背景下,maxcompute(odps)计算框架持续演化,而原来主要面对内部特殊格式数据的强大计算能力,也正在一步步的通过新增的非结构化数据处理框架,开放给不同的外部数据。
前言
maxcompute作为阿里巴巴集团内部绝大多数大数据处理需求的核心计算组件,拥有强大的计算能力,随着集团内外大数据业务的不断扩展,新的数据使用场景也在不断产生。在这样的背景下,maxcompute(odps)计算框架持续演化,而原来主要面对内部特殊格式数据的强大计算能力,也正在一步步的通过新增的非结构化数据处理框架,开放给不同的外部数据。 我们相信阿里巴巴集团的这种需求,也代表着业界大数据领域的最前沿实践和走向,具有相当的普适性。在之前我们已经对maxcompute 2.0新增的非结构化框架做过整体介绍,描述了在maxcompute上如何处理存储在oss上面的非结构化数据,侧重点在怎样从oss读取各种非结构化数据并在maxcompute上进行计算。 而一个完整数据链路,读取和计算处理之后,必然也会涉及到非结构化数据的 写出。 在这里我们着重介绍一下从maxcompute往oss输出非结构化数据,并提供一个具体的在maxcompute上进行图像处理的实例, 来展示从【oss->maxcompute->oss】的整个数据链路闭环的实现。 至于对于kv nosql类型数据的输出,在对tablestore数据处理介绍 中已经有所介绍,这里就不再重复。
1. 使用前提和假设
1.1 maxcompute 2.0 功能
这里介绍的功能基于maxcompute新一代的2.0计算框架,目前2.0计算框架已经全面上线,默认就可使用。
另外本文中使用了maxcompute 2.0新引进的一个binary类型,目前在使用binary类型时,还需要显性设置set odps.sql.type.system.odps2=true。
1.2 网络连通性与访问权限
另外因为maxcompute与oss是两个分开的云计算,与云存储服务,所以在不同的部署集群上的网络连通性有可能影响maxcompute访问oss的数据的可达性。 关于oss的节点,实例,服务地址等概念,可以参见oss相关介绍。 在maxcompute公共云服务访问oss存储,推荐使用oss私网地址(即以-internal.aliyuncs.com结尾的host地址)。
此外需要指出的是,maxcompute计算服务要访问tablestore数据需要有一个安全的授权通道。 在这个问题上,maxcompute结合了阿里云的访问控制服务(ram)和令牌服务(sts)来实现对数据的安全反问:
首先需要在ram中授权maxcompute访问oss的权限。登录ram控制台,创建角色aliyunodpsdefaultrole,并将策略内容设置为:
{
"statement": [
{
"action": "sts:assumerole",
"effect": "allow",
"principal": {
"service": [
"odps.aliyuncs.com"
]
}
}
],
"version": "1"
}然后编辑该角色的授权策略,将权限aliyunodpsrolepolicy授权给该角色。
如果觉得这些步骤太麻烦,还可以登录阿里云账号点击此处完成一键授权。
2. maxcompute内置的oss数据输出handler
2.1 创建external table
maxcompute非结构化数据框架希望从根本上提供maxcompute与各种数据的联通,这里的“各种数据”是两个维度上的:
- 各种存储介质,比如oss
- 各种数据格式, 比如文本文件,视频,图像,音频,基因,气象等格式的数据
而数据的这两个维度的特征,都是通过external table的概念来引入maxcompute的计算体系的。 与读取oss数据的使用方法类似,对oss数据进行写操作,在如上打开安全授权通道后,也是先通过create external table语句创建出一个外部表,再通过标准maxcompute sql的insert into/overwrite等语句来实现的,这里先用maxcompute内置的tsvstoragehandler为例来说明一下用法:
drop table if exists tpch_lineitem_tsv_external;
create external table if not exists tpch_lineitem_tsv_external
(
orderkey bigint,
suppkey bigint,
discount double,
tax double,
shipdate string,
linestatus string,
shipmode string,
comment string
)
stored by 'com.aliyun.odps.tsvstoragehandler' ----------------------------------------- (1)
location 'oss://oss-cn-shanghai-internal.aliyuncs.com/oss-odps-test/tsv_output_folder/'; --(2)这个ddl语句建立了一个外部表tpch_lineitem_tsv_external,并将前面提到的两个维度的外部数据信息关联到这个外部表上。
- 数据存储介质: location 将一个oss上的地址关联到外部表上,对这个外部表的进行读写操作都会反映到这个oss地址上。
- 数据存储格式: storagehandler用来表明对这些数据的读写操作方式,这里使用了maxcompute内置的
com.aliyun.odps.tsvstoragehandler, 用户可以使用这个由系统自带的实现来读取和写出tsv文件。 同时用户也可以通过maxcompute的sdk来自定义storagehandler, 这个将在后面的章节介绍。
其中oss数据存储的具体地址的uri格式为:
location 'oss://${endpoint}/${bucket}/${userpath}/'最后还要提到的是,在上面的ddl语句中定义了外部表的schema, 对于数据输出而言,这表示输出的数据格式将由这个schema描述。 就tsv格式而言,这个schema描述比较直观容易理解; 而在用户自定义的输出数据格式上,这个schema与输出数据的联系则更松散一些,有着更大的自由度。 在后面介绍通过自定义storagehandler/outputer的时候会详细展开。
2.2 通过对external table的 insert 操作实现tsv文本文件的写出
在将oss数据通过external table关联上后,对oss文件的写出可以对external table做标准的sql insert overwrite/insert into来操作。 具体输出数据的来源可以有两种
- 数据源为maxcompute的内部表: 也就是说可以通过对外表insert操作来实现maxcompute内部表数据到外部存储介质的写出。
- 数据源为之前通过external table引入maxcompute计算体系的外部数据: 这可以用来将外部数据引入maxcompute进行计算,然后再存储到(不同的)外部存储地址,或者甚至是不同的外部存储介质(比如将tablestore数据经由maxcompute导出到oss)。
2.2.1 从maxcompute内部表输出数据到oss
这里先来看第一种场景:假设我们已经有一个名为tpch_lineitem的maxcompute内部表,其schema可以通过
describe tpch_lineitem; 得到:
+------------------------------------------------------------------------------------+
| internaltable: yes | size: 241483831680 |
+------------------------------------------------------------------------------------+
| native columns: |
+------------------------------------------------------------------------------------+
| field | type | label | comment |
+------------------------------------------------------------------------------------+
| l_orderkey | bigint | | |
| l_partkey | bigint | | |
| l_suppkey | bigint | | |
| l_linenumber | bigint | | |
| l_quantity | double | | |
| l_extendedprice | double | | |
| l_discount | double | | |
| l_tax | double | | |
| l_returnflag | string | | |
| l_linestatus | string | | |
| l_shipdate | string | | |
| l_commitdate | string | | |
| l_receiptdate | string | | |
| l_shipinstruct | string | | |
| l_shipmode | string | | |
| l_comment | string | | |
+------------------------------------------------------------------------------------+其中有16个columns。 现在我们希望将其中的一部分数据以tsv格式导出到oss上面。 那么在用上述ddl创建出external table之后,使用如下insert overwrite操作就可以实现:
insert overwrite table tpch_lineitem_tsv_external
select l_orderkey, l_suppkey, l_discount, l_tax, l_shipdate, l_linestatus, l_shipmode, l_comment
from tpch_lineitem
where l_discount = 0.07 and l_tax = 0.01;这里将从内部的tpch_lineitem表中,在符合l_discount = 0.07 并 l_tax = 0.01的行中选出8个列(对应tpch_lineitem_tsv_external这个外部表的schema)按照tsv的格式写到oss上。 在上面这个insert overwrite操作成功完成后,就可以看到oss上的对应location产生了一系列文件:
osscmd ls oss://oss-odps-test/tsv_output_folder/
2017-01-14 06:48:27 39.00b standard oss://oss-odps-test/tsv_output_folder/.odps/.meta
2017-01-14 06:48:12 4.80mb standard oss://oss-odps-test/tsv_output_folder/.odps/20170113224724561g9m6csz7/m1_0_0-0.tsv
2017-01-14 06:48:05 4.78mb standard oss://oss-odps-test/tsv_output_folder/.odps/20170113224724561g9m6csz7/m1_1_0-0.tsv
2017-01-14 06:47:48 4.79mb standard oss://oss-odps-test/tsv_output_folder/.odps/20170113224724561g9m6csz7/m1_2_0-0.tsv
...这里可以看到,通过上面location指定的oss-odps-test这个oss bucket下的tsv_output_folder文件夹下产生了一个.odps文件夹,这其中将有一些.tsv文件,以及一个.meta文件。 这样子的文件结构是maxcompute(odps)往oss上输出所特有的:
- 通过maxcompute对一个oss地址,使用insert into/overwrite 外部表来做写出操作,所有的数据将在指定的location下的
.odps文件夹产生; - 其中
.odps文件夹中的.meta文件为maxcompute额外写出的宏数据文件,其中用于记录当前文件夹中有效的数据。 正常情况下,如果insert操作成功完成的话,可以认为当前文件夹的所有数据均是有效数据。 只有在有作业失败的情况下需要对这个宏数据进行解析。 即使是在作业中途失败或被kill的情况下,对于insert overwrite操作,再跑一次成功即可。 如果对于高级用户,一定需要解析.meta文件的话,可以联系maxcompute技术团队。
这里迅速看一下这些tsv文件的内容:
osscmd cat oss://oss-odps-test/tsv_output_folder/.odps/20170113232648738gam6csz7/m1_0_0-0.tsv
4236000067 9992377 0.07 0.01 1992-11-06 f rail across the ideas nag
4236000290 3272628 0.07 0.01 1998-04-28 o rail uriously. furiously unusual dinos int
4236000386 8081402 0.07 0.01 1994-02-19 f rail its. express, iron
4236000710 3879271 0.07 0.01 1995-03-10 f air es are carefully fluffily spe
...
可以看到确实在oss上产生了对应的tsv数据文件。
最后,大家可能也注意到了,这个insert overwrite操作产生了多个tsv文件,对于maxcompute内置的tsv/csv处理来说,产生的文件数目与对应sql stage的并发度是相同的,在上面这个例子中,inser overwite ... select ... from ...; 的操作在源数据表(tpch_lineitem) 上分配了1000个mapper,所以最后产生了1000个tsv文件的。 如果需要控制tsv文件的数目,可以配合maxcompute的各种灵活语义和配置来实现。 比如如果需要强制产生一个tsv文件,那在这个特定例子中,可以在inser overwite ... select ... from ...最后加上一个distribute by l_discount, 就可以在最后插入仅有一个reducer的reduce stage, 也就会只输出一个tsv文件了:
osscmd ls oss://oss-odps-test/tsv_output_folder/
2017-01-14 08:03:41 39.00b standard oss://oss-odps-test/tsv_output_folder/.odps/.meta
2017-01-14 08:03:35 4.20gb standard oss://oss-odps-test/tsv_output_folder/.odps/20170113234037735gcm6csz7/r2_1_33_0-0.tsv可以看到在增加了distribute by l_discount后,现在同样的数据只了一个输出tsv文件,当然这个文件的size就大多了。 这方面的调控技巧还有很多,都是可以依赖sql语言的灵活性,数据本身的特性,以及maxcompute计算相关设置来实现的,这里就不深入展开了。
2.2.2 以maxcompute为计算介质,实现不同存储介质之间的数据转移
external table作为一个maxcompute与外部存储介质的一个切入点,之前已经介绍过对oss数据的读取以及tablestore数据的操作,结合对外部数据读取和写出的功能,就可以实现通过external table实现各种各样的数据计算/存储链路,比如:
- 读取external table a关联的oss数据,在maxcompute上做复杂计算处理,并输出到external table b关联的oss地址
- 读取external table a关联的tablestore数据,在maxcompute上做复杂计算处理,并输出到external table b关联的oss地址
而这些操作与上面数据源为maxcompute内部表的场景, 唯一的区别只是select的来源变成一个external table,而不是maxcompute内置表。
3. 通过自定义storagehandler来实现数据输出
除了使用内置的storagehandler来实现在oss上输出tsv/csv等常见文本格式,maxcompute非结构化框架提供了通用的sdk,允许用户对外输出自定义数据格式文件,包括图像,音频,视频等等。 这种对于用户自定义的完全非结构化数据格式支持,也是maxcompute从结构化/文本类数据的一个向外扩展,在这里我们会以一个图像处理的例子,来走通整个【oss->maxcompute->oss】数据链路,尤其着重介绍对oss输出文件的功能。
为了方便大家理解,这里先提供一个在使用用户自定义代码的场景下,数据在maxcompute计算平台上的流程:
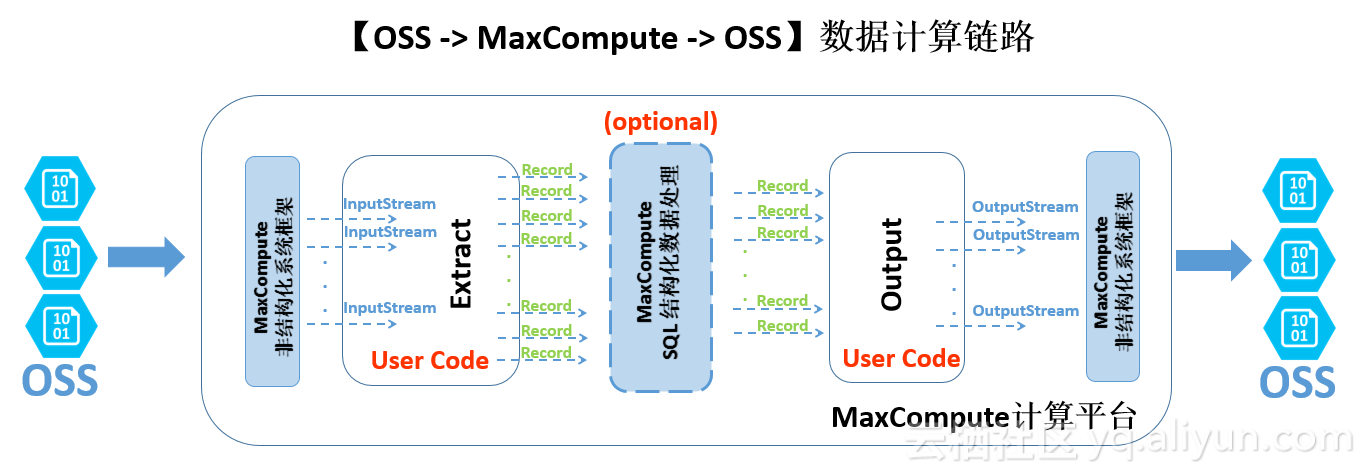
从上图可以看出,从数据的流动和处理逻辑上理解,用户可以简单地把非结构化处理框架理解成在maxcompute计算平台两端有机耦合的的数据导入(ingres)以及导出(egress):
- 外部的(oss)数据经过非结构化框架转换,会使用java用户容易理解的
inputstream类提供给自定义代码接口。 用户自实现extract逻辑只需要负责对输入的inputstream做读取/解析/转化/计算,最终返回maxcompute计算平台通用的record格式; - 这些record可以自由的参与maxcompute的sql逻辑运算,这一部分计算是基于maxcompute内置的强大结构化sql运算引擎,并可能产生新的record
- 运算过后的record中再传递给用户自定义的output逻辑,用户在这里可以进行进一步的计算转换,并最终将record里面需要输出的信息通过系统提供的
outputstream输出,由系统负责写到oss。
值得指出的是,这里面所有的步骤都是可以由用户根据需要来进行自由的选择与拼接的。 比如如果用户的输入就是maxcompute的内部表,那步骤1.就没有必要了,事实上在前面的章节2中的例子,我们就实现了将内部表直接写成oss上的tsv文件的流程。 同理, 如果用户没有输出的需求,步骤3. 就没有必要,比如我们之前介绍的oss数据的读取。 最后,步骤2.也是可以省略的,比如如果用户的所有计算逻辑都是在自定义的extract/output中完成,没有进行sql逻辑运算的需要,那步骤1.是可以直接连接到步骤3.的。
理解了上面这个数据变换的流程,我们就可以来通过一个图像处理例子来看看怎么具体的通过非结构化框架在maxcompute sql上完整的实现非结构化数据的读取,计算以及输出了:
3.1 范例:oss图像文件 -> maxcompute计算处理 -> oss图像输出
这里我们先提供实现这整个【oss->maxcompute->oss】数据链路需要用到的maxcompute sql query,并做简单的注解,详细的用户代码实现逻辑将在后面的3.2子章节中介绍sdk接口的时候做展开解释。
3.1.1 关联oss上的原始输入图像到external table: images_input_external
drop table if exists images_input_external;
create external table if not exists images_input_external
(
name string,
width bigint,
height bigint,
image binary
)
stored by 'com.aliyun.odps.udf.example.image.imagestoragehandler' --- (1)
with serdeproperties ('inputimageformat'='bmp' , 'transformedimageformat' = 'jpg') --- (2)
location 'oss://oss-cn-shanghai-internal.aliyuncs.com/oss-odps-test/dev/sampledata/test_images/mixed_bmp/' --- (3)
using 'odps-udf-example.jar'; --- (4)说明:
- 用户指明使用的用户代码wrapper class名字是com.aliyun.odps.udf.example.image.imagestoragehandler,这个class及其依赖的三方库用户通过jar提供,具体jar名字会通过下面的using语句(见第4点)指定。
- 通过serdeproperties来实现参数传递,格式为'key'='value', 具体用法可以参见基本功能介绍以及下面的用户代码说明
- 指定输入图像地址,这个地址上存放了一系列不同分辨率的bmp图像文件。
- 指定包含用户jar包,内含自定义的storagehandler/extractor/outputer,以及需要的三方库(这里用到了java imageio库,具体见下面用户代码范例)。jar包通过add jar命令上传,可以参见基本功能介绍。
另外要说明的是这里指定的external table的schema就是用户在进行extract操作后构造的record格式,具体怎么构造这个schema用户可以根据需要自己根据能从输入数据中抽取到的信息定义。 在这里我们定义了对于输入图片数据,会将图片名称,图片的长和宽,以及图片的二进制bytes抽取出来放进record(见后面的extractor代码说明),所以就有了上面的【string,bigint,bigint,binary】的schema。
3.1.2 关联oss输出地址到external table: images_output_external
create external table if not exists images_output_external
(
image_name string,
image_width bigint,
image_height bigint,
outimage binary
)
stored by 'com.aliyun.odps.udf.example.image.imagestoragehandler'
location 'oss://oss-cn-shanghai-internal.aliyuncs.com/oss-odps-test/dev/output/images_output/' ---(1)
using 'odps-udf-example.jar';说明: 可以看到这里创建关联输出图像文件的external table,使用的ddl语句,与前面关联输入图像时使用的ddl语句是非常类似的:只是location不一样,表明图像数据处理后将输出到另外一个地址。 另外还有一点就是这里我们没有使用serdeproperties来进行传参,这个只是在这个场景上没有需求,在有需求的时候可以用同样的方法把参数传递给outputer。 当然这里两个ddl语句如此相似,有一个原因是因为我们这个例子中用户代码中对于extract出的record以及输入给outputer的record使用了一样的schema, 同时这一对extractor和outputer都被封装在了同一个imagestoragehandler里放在同一个jar包里。 在实际应用中,这些都是可以根据实际需求自己调整的,由用户自己选择组合和打包方式。
3.1.3 从oss读取原始图片数据到maxcompute, 计算处理,并输出图像到oss
在上面的3.1.1以及3.1.2子章节中的两个ddl语句,分别实现了把输入oss数据,以及计划输出oss数据,分别绑定到两个location以及指定对应的用户处理代码,参数等设置。 然而这两个ddl语句对系统而言,只是进行了一些宏数据的记录操作,并不会涉及具体的数据计算操作。 在这两个ddl语句运行成功后,运行如下sql语句才会引发真正的运算。 换句话说,在fig.1中描述的整个【oss->maxcompute->oss】数据读取/计算/输出链路,实际上都是通过下面一个简单的sql 语句完成的:
insert overwrite table images_output_external
select * from images_input_external
where width = 1024;这看起来就是一个标准的maxcompute sql语句,只不过因为涉及了images_output_external和images_input_external这两个外部表,所以真正进行的物理操作与传统的sql操作会有一些区别:在这个过程中,涉及了读写oss,以及通过imagestoragehandler这个wrapper,调用自定义的extractor,outputer代码来对数据进行操作。 下面就来具体看看在这个例子中的用户自定义代码实现了怎样的功能,以及具体是如何实现的。
3.2 imagestoragehandler实现
如同之前介绍过的,maxcompute非结构化框架通过storagehandler这个接口来描述对各种数据存储格式的处理。 具体来说,storagehandler作为一个wrapper class, 让用户指定自己定义的exatractor(用于数据的读入,解析,处理等) 以及outputer(用于数据的处理和输出等)。 用户自定义的storagehandler 应该继承 odpsstoragehandler,实现getextractorclass以及getoutputerclass 两个接口。
通常作为wrapper class, storagehandler的实现都很简单,比如这里的imagestoragehandler 就只是通过这两个接口指定了我们将使用imageextractor以及imageoutputer:
package com.aliyun.odps.udf.example.image;
public class imagestoragehandler extends odpsstoragehandler {
@override
public class<? extends extractor> getextractorclass() {
return imageextractor.class;
}
@override
public class<? extends outputer> getoutputerclass() {
return imageoutputer.class;
}
}
另外要说明的是如果确定在使用某个storagehandler的时候,只需要用到extractor,或者只需要用到outputer功能,那不需要的接口则不用实现。 比如如果我们只需要读取oss数据而不需要做insert操作,那getoutputerclass()的实现只需要扔个notimplemented exception就可以了,不会被调用到。
3.3 imageextractor实现
因为对于sdk中extractor接口的介绍以及对用户如何写一个自定义的extractor,在之前介绍的oss数据的读取中已经有所涉及,所以这里就不再对这方面做深入的介绍。
extractor的工作在于读取输入数据并进行用户自定义处理,那么我们首先来看看这里由images_input_external这个外表绑定的oss输入location上存放的具体数据内容:
osscmd ls oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/
2017-01-09 14:02:01 1875.05kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/barbara.bmp
2017-01-09 14:02:00 768.05kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/cameraman.bmp
2017-01-09 14:02:00 1054.74kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/fishingboat.bmp
2017-01-09 14:01:59 257.05kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/goldhill.bmp
2017-01-09 14:01:59 468.80kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/house.bmp
2017-01-09 14:01:59 468.80kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/jetplane.bmp
2017-01-09 14:02:01 2.32mb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/lake.bmp
2017-01-09 14:01:59 257.05kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/lena.bmp
2017-01-09 14:02:00 768.05kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/livingroom.bmp
2017-01-09 14:02:00 768.05kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/pirate.bmp
2017-01-09 14:02:00 768.05kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/walkbridge.bmp
2017-01-09 14:02:00 1054.74kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/woman_blonde.bmp
2017-01-09 14:02:00 768.05kb standard oss://oss-odps-test/dev/sampledata/test_images/mixed_bmp/woman_darkhair.bmp可以看到这个location存放了一系列bmp图像数据,分辨率从 400 x 400 到 1200 x 1200不等。 具体在这个例子中用到的imageextractor的详细代码在github上可以找到, 这里只做一些简单介绍说明该extractor做了些什么工作:
-
从输入的oss地址上使用非结构化框架提供的
inputstream接口读取图像数据,并在本地进行如下操作- 对于图像宽度小于1024的图片,统一放大到1024 x 1024; 对于图像宽度大于1024的图片,跳过不进行处理
- 处理过的图片,在内存中转存成由输入参数指定的格式(jpg)
- 把处理后在内存中的jpg数据的原始字节存入输出的record中的binary field, 同一个record中还将存放处理后图像的长和宽(都是1024), 以及原始的图像名字(这个可以从输入的
inputstream上获取); - 填充后的record从extract接口返回进入maxcompute系统;
- 在这个过程中,用户可以灵活的进行各种操作,比如额外的参数验证等。
另外要说明的是,目前record作为maxcompute结构化数据处理的基本单元,有一些额外的限制,比如binary/string类型都有8mb大小的限制,但是在大部分场景下这个大小应该是能满足存储需求的。
3.4 imageoutputer的实现
接下来我们着重讲一下imageoutputer的实现。 首先所有的用户输出逻辑都必须实现outputer接口,具体来说有如下三个:setup, output和close, 这和extractor的setup, extract和close三个接口基本上是对称的。
// base outputer class, custom outputer shall extend from this class
public abstract class outputer{
public abstract void setup(executioncontext ctx, outputstreamset outputstreamset, dataattributes attributes);
public abstract void output(record record) throws ioexception;
public abstract void close() throws ioexception;
}这其中setup()和close()在一个outputer中只会调用一次。 用户可以在setup里面做初始化准备工作,另外通常需要把setup()传递进来的这三个参数保存成ouputerd的class variable, 方便之后output()或者close()接口中使用。 而close()这个接口用于方便用户代码的扫尾工作。
通常情况下大部分的数据处理发生在output(record)这个接口内。 maxcompute系统会根据当前outputer分配处理的record数目不断调用,也就是对每个输入record系统会调用一次 output(record)。 系统假设在一个output(record) 调用返回的时候,用户代码已经消费完这个record, 因此在当前output(record)返回后,系统可能将这个record所使用的内存用作它用: 所以不推荐一个record中的信息在跨多个output()函数调用被使用,如果一定有这个需求的话,用户必须把相关信息通过class variable等方式自行另外保存。
3.4.1 imageoutputer.setup()
setup用于初始化整个outputer, 在这个接口上提供了整个outputer操作过程中可能需要的参数:
executioncontext: 用于提供一些系统信息和接口,比如读取resource等,在imageoutputer这个例子中我们没有用到这个参数;outputstreamset: 用户可以从这个类的next()接口获取对外输出所需要的outputstream,具体用法我们在下面详细介绍;dataattributes: 用户通过serdeproperties设置的key-value参数可以通过这个类获取,参数获取这里imageoutputer例子中没有用到,但是extractor上的setup参数中也有这个类,在上面的imageextractor用到了改功能,可以参考一下。 同时这个类上面还提供了一些helper接口,比如方便用户验证schema等。
在我们这个imageoutputer里,setup()的实现比较简单:
@override
public void setup(executioncontext ctx, outputstreamset outputstreamset, dataattributes attributes) {
this.outputstreamset = outputstreamset;
this.attributes = attributes;
this.attributes.verifyschema(new odpstype[]{ odpstype.string, odpstype.bigint, odpstype.bigint, odpstype.binary });
}只是做了简单的初始化以及对schema的验证。
3.4.2 imageoutputer.output(record) 以及 outputstreamset的使用
在介绍具体output()接口之前,首先我们要来看看 outputstreamset, 这个类有两个接口:
public interface outputstreamset{
sinkoutputstream next();
sinkoutputstream next(string filenamepostfix);
}两个接口都是用来获取一个新的sinkoutputstream(一个java outputstream的实现,可以按照outputstream使用),两个接口唯一的区别是next()获取的outputstream写出的文件名完全由maxcompute系统决定,而next(string filenamepostfix)则允许用户提供文件名的postfix。 提供这个postfix的意义是,在输出文件具体地址和名字格式总体由maxcompute系统决定的前提下,用户依然可以定制一个方便理解的postfix。 比如使用next("_boat.jpg") 得到的outputstream可能对应如下一个输出文文件:
oss://oss-odps-test/dev/output/images_output/.odps/20170115148446219dicjab270/m1_0_-1--1-0_boat.jpg这其中尾端的"_boat.jpg"可以帮助用户理解输出文件的涵义。 如果这个 outputstream是由next()获得的话,那对应的输出文件可能就是这样的:
oss://oss-odps-test/dev/output/images_output/.odps/20170115148446219dicjab270/m1_0_-1--1-0用户可能就需要具体读取这个文件才能知道这个文件中具体存放了什么内容。
前面提到output(record)这个接口会由系统不断调用,但是应该强调的是,并不一定在每一个record都需要调用一次outputstreamset.next()接口来获得一个新的outputstream。 事实上在大多数情况下,我们建议在一个outputer里面尽可能减少调用next()的次数(最好只调用一次)。 也就是说理想情况下,一个outpuer只应该产生一个输出文件。 比如处理tsv这种文本格式文件,假设有5000个record对应5000行tsv数据,那么最理想的情况是应该把这5000行数据全部写到一个tsv文件中。 当然用户可能会有各种各样不同的切分输出文件的需求:比如希望每个文件大小控制在一定范围,或比如文件的边界有显著的意义等等。
具体到当前这个图像例子,从下面的imageoutputer代码实现中可以看出,这个例子中确实是处理每个record就调用一次next()的,因为在当前场景中,每一个输入的record都表示一张图片的信息(binary bytes, 图像名字,图像长宽),所以这里通过多次调用next()来输出多个图片文件。 但是我们还是需要再次强调,调用next()的次数过多可能有一些其他弊端,比如造成碎片化小数据在oss上的存储等等。 尤其在maxcompute这种分布式计算系统上,因为系统本身就会调度起多个outputer进行并行计算处理,如果每个outpuer都输出过多文件的话,最后产生的文件数目会有一个乘性效应。 回头来看我们这个例子中,即使在这里,多个图像其实也可以通过一个outputstream,按照tar/tar.gz的方式写到单个文件中,这些都是在实现具体系统中用户需要根据自己的场景, 以及处理逻辑,输出数据类型等信息来进行优化和tradeoff的。
在理解了这些之后,现在来具体看看imageoutputer的实现output接口实现:
@override
public void output(record record) throws ioexception {
string name = record.getstring(0);
long width = record.getbigint(1);
long height = record.getbigint(2);
bytearrayinputstream input = new bytearrayinputstream(record.getbytes(3));
bufferedimage sobeledgeimage = getedgeimage(input);
outputstream outputstream = this.outputstreamset.next(name + "_" + width + "x" + height + "." + outputformat);
imageio.write(sobeledgeimage, this.outputformat, outputstream);
}可以看到这里主要就做了三件事情:
- 根据之前保存的图像名字,长宽信息,和编码方式(".jpg")拼出一个带扩展名的输出文件名postfix。
- 读取图像binary bytes,并用
getedgeimage()来利用sobel算子对图像做边缘检测。 具体getedgeimage()的实现这里就不进行深入解释了: 使用了标准的sobel模板卷积算法, 有兴趣看imageoutputer源码即可。 - 对每一个图像产生一个新的
outputstream并将数据写出,至此当前record处理完毕,写出一张图片到oss,output()函数返回。
3.4.3 imageoutputer.close()
在这个例子中,outputer.close()接口没有包含具体的实现逻辑,是个no-op。
至此我们就介绍完了一个output的实现,现在可以看看在运行完这个sql query,对应oss地址的数据:
osscmd ls oss://oss-odps-test/dev/output/images_output/
2017-01-15 14:36:50 215.19kb standard oss://oss-odps-test/dev/output/images_output/.odps/20170115148446219dicjab270/m1_0_-1--1-0-barbara_1024x1024.jpg
2017-01-15 14:36:50 108.90kb standard oss://oss-odps-test/dev/output/images_output/.odps/20170115148446219dicjab270/m1_0_-1--1-1-cameraman_1024x1024.jpg
2017-01-15 14:36:50 169.54kb standard oss://oss-odps-test/dev/output/images_output/.odps/20170115148446219dicjab270/m1_0_-1--1-2-fishingboat_1024x1024.jpg
2017-01-15 14:36:50 214.94kb standard oss://oss-odps-test/dev/output/images_output/.odps/20170115148446219dicjab270/m1_0_-1--1-3-goldhill_1024x1024.jpg
2017-01-15 14:36:50 71.00kb standard oss://oss-odps-test/dev/output/images_output/.odps/20170115148446219dicjab270/m1_0_-1--1-4-house_1024x1024.jpg
2017-01-15 14:36:50 126.50kb standard oss://oss-odps-test/dev/output/images_output/.odps/20170115148446219dicjab270/m1_0_-1--1-5-jetplane_1024x1024.jpg
2017-01-15 14:36:50 169.63kb standard oss://oss-odps-test/dev/output/images_output/.odps/20170115148446219dicjab270/m1_0_-1--1-6-lake_1024x1024.jpg
2017-01-15 14:36:50 194.18kb standard oss://oss-odps-test/dev/output/images_output/.odps/20170115148446219dicjab270/m1_0_-1--1-7-lena_1024x1024.jpg
...
可以看到图像数据按照期待格式写到了指定地址,这里我们就选一个输入图像(lena.bmp)以及对应的输出图像(m1_0_-1--1-7-lena_1024x1024.jpg)看一下对比:

这个例子中整个图像处理流程已经通过如上的sql query完成。 而从上面展示的imageextractor以及imageoutputer 源代码,我们可以看出整个过程中用户的逻辑基本与写单机图像处理程序无异,用户的代码只需要在extractor上做inputstream到record的准换,而在outputer上做反向的record到outputsteam的写出处理,其他核心的处理逻辑实现基本和单机算法实现相同,在用户的层面,并不用去操心底层分布式系统的细节以及maxcompute和oss的交互。
3.5 数据处理步骤的灵活性
从上面这个例子中我们也可以看出,在一个完整的【oss->maxcompute->oss】数据流程中,extractor和outputer中涉及的具体计算逻辑其实也并不一定会有一个非常明确的边界。 extractor和outputer只要各自完成所需的转换record/stream的转换,具体的额外算法逻辑在两个地方都有机会完成。 比如上面这个例子的整个流程涉及了如下图像处理相关的运算:
- 图像的缩放 (统一到 1024 x 1024)
- 图像格式的转换 (bmp -> jpg)
- 图像的sobel边缘检测
上面的例子实现中,把1. 和 2. 放在imageextractor中完成,而3.则放在imageoutputer中完成,但并不是唯一的选择。 我们完全可以把所有3个步骤都放在imageextractor中完成,让imageoutputer只做record到写出最后图像的操作;也可以在imageextractor中只做读取原始binary到recrod, 而把所有3个图像处理步骤都放在imageoutputer中进行,等等。 具体进行怎样的选择,用户可以完全根据需要自己实现。
另外一个系统设计的点是如果对于一个数据需要做重复的运算,那可以考虑将数据从oss中通过extractor读出进maxcompute,然后存储成maxcompute的内置表格再进行(多次)的计算。 这个对于maxcompute和oss没有进行混布,不在一个物理网络上的场景尤其有意义: maxcompute从内置表中读取数据无疑要比从外部oss存储服务中读出数据要有效得多。 在上面3.1.3子章节中的图像处理例子,这个inser overwite操作:
insert overwrite table images_output_external
select * from images_input_external
where width = 1024;就可以改写成两个分开的语句:
insert overwrite table images_internal
select * from images_input_external
where width = 1024;
insert overwrite table images_output_external
select * from image_internal;通过把数据写到一个内部images_internal表中,后面如果有多次读取数据的需求的话,就可以不再去访问外部oss了。 这里也可以看到maxcompute非结构化框架以及sql语法本身提供了非常高的灵活性和可扩展性,用户可以根据实际计算的不同模式/场景/需求,来在上面完成各种各样的数据计算工作流。
5. 结语
非结构化数据处理框架随着maxcompute 2.0一起推出,意在丰富maxcompute平台的数据处理生态,来打通阿里云核心计算平台与阿里云各个重要存储服务之间的数据链路。 在之前介绍过的读取oss以及处理tablestore数据的整体方案后,本文侧重介绍数据往oss的输出方案,并依托一个图像处理的处理实例,展示了【oss->maxcompute->oss】整个数据链路的实现。 在这些新功能的基础上,我们希望实现整个阿里云计算与数据的生态融合: 在不同的项目上,我们已经看到了在maxcompute上处理oss上的海量视频,图像等非结构化数据的巨大潜力。 今后随着这个生态的丰富,我们期望oss数据,tablestore数据以及maxcompute内部存储的数据,都能在maxcompute的核心计算引擎上进行融合,从而产生更大的价值。


发表评论